1、Kafka介绍
Kafka是一款开源的分布式消息系统,最初由LinkedIn公司开发并开源。它被设计用于处理海量的实时数据流,可以支持高吞吐量和低延迟的数据传输。
Kafka的设计主要目标是提供一个持久化的、高吞吐量的、可扩展的、分布式发布/订阅消息系统,以解决实时数据处理的需求。它基于发布/订阅模型,通过将消息发布到主题(Topic)并让订阅者订阅相关主题,实现了消息的生产者和消费者之间的解耦。
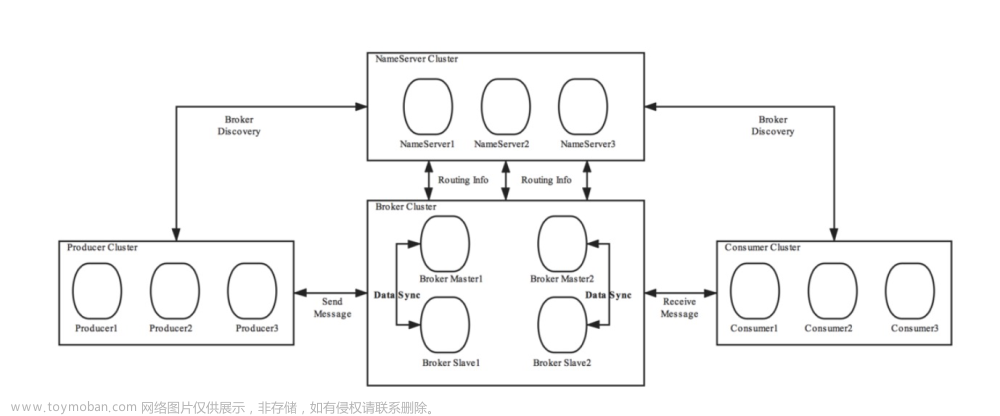
Kafka的架构和设计思想非常灵活,主要由以下几个核心组件组成:
Producer(生产者): 负责将消息发布到Kafka集群中的指定主题。
Consumer(消费者): 订阅并消费特定主题的消息。
Topic(主题): 消息的类别或者主题分类,消息被发布到特定的主题,消费者可以订阅感兴趣的主题。
Broker(代理): Kafka集群中的服务器节点,负责消息的存储和转发。
Partition(分区): 每个主题可以分为多个分区,每个分区都是有序且持久化的消息记录队列。
Producer API(生产者API)和Consumer API(消费者API): 提供了丰富的编程接口,方便开发者在应用程序中集成Kafka。
Kafka的特点包括:
高性能:Kafka可以支持每秒数十万条消息的高吞吐量处理。
可扩展性:Kafka的持久化消息存储和分区机制可以方便地进行水平扩展。
容错性:Kafka具备良好的容错机制,即使在某个节点故障的情况下,仍然可以保证消息的可靠传输。
消息保留:Kafka可以根据配置保留消息的时间或大小限制。
多语言支持:Kafka提供了多种编程语言的客户端,方便开发者使用不同语言来集成和使用Kafka。
Kafka广泛应用于各种领域,特别是大数据处理、实时流处理和日志收集等场景。
2、Flink介绍
Flink(Apache Flink)是一种开源的流处理和批处理框架,它提供了可靠、高性能、可伸缩的大数据处理能力。Flink最初由德国柏林工业大学(Berlin TU)的一个研究小组开发,并于2014年成为Apache软件基金会的顶级项目。
Flink的设计目标是实时流处理和批处理的无缝融合,它提供了统一的数据处理模型,使得开发人员可以方便地编写和运行具有低延迟和高吞吐量需求的大规模数据处理应用。
Flink的核心概念是流(Stream)和转换(Transformation)。应用程序通过定义数据流(DataStream)来描述输入数据和计算过程,并且可以应用各种转换操作(如过滤、转换、合并等)对数据流进行操作和处理。Flink提供了丰富的转换函数和算子,可以轻松地实现各种复杂的数据处理逻辑。
Flink具有以下特点:
低延迟和高吞吐量:Flink采用了基于内存的流式计算模型,能够实现毫秒级的实时响应。
Exactly-Once语义:Flink可以确保数据处理的精确一次性,即数据不会丢失也不会重复处理。
可容错性:Flink通过在集群中保存数据的一致性检查点(Checkpoint)来提供故障恢复和容错处理能力。
状态管理:Flink能够在处理过程中维护和管理状态,这对于处理窗口操作和流-流连接等场景非常重要。
可伸缩性:Flink可以方便地进行水平扩展,支持集群模式和分布式部署。
支持大规模数据处理:Flink可以处理海量数据,适用于大数据和实时流处理等场景。文章来源:https://www.toymoban.com/news/detail-614457.html
Flink在实时流处理、批处理、连续查询、机器学习和图分析等领域得到了广泛应用。它提供了易于使用的API和丰富的生态系统,可以与主流的大数据存储和计算平台(如Hadoop、Kafka、Cassandra等)进行无缝集成,为用户提供了强大的数据处理能力和灵活性。文章来源地址https://www.toymoban.com/news/detail-614457.html
3、Flink订阅Kafka消息实战代码
import java.util.Properties
// 配置Kafka的属性
val properties: Properties = new Properties
// 设置服务
properties.setProperty("bootstrap.servers", "bigdata_server1:9092,bigdata_server2:9092,bigdata_server3:9092")
// 设置消费者组
properties.setProperty("group.id", "test_group")
// kafka反序列化消息是在消费端
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
// 由于网络传输过来的是byte[],只有反序列化后才能得到生产者发送的真实的消息内容。
// 属性key.deserializer和value.deserializer就是key和value指定的反序列化方式
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
// 指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下改如何处理。
properties.setProperty("auto.offset.reset", "latest")
import main.flink.com.bg.Config.Config
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode
import org.apache.flink.streaming.api.datastream.DataStream
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.streaming.util.serialization.JSONKeyValueDeserializationSchema
val env: StreamExecutionEnvironment // Flink执行环境
val topic : String // 话题
// 创建一个消费者,读取指定topic话题的消息
val consumer = new FlinkKafkaConsumer(
topic, // Kafka话题
new JSONKeyValueDeserializationSchema(true),
Config.getKafkaProperties() // Kafka配置,类型
)
// 将Kafka消费者添加到输入源
val stream = env.addSource(consumer) // 返回DataStream[ObjectNode]类型
// 打印并执行消息
stream.print()
env.execute("flink kafka demo")
到了这里,关于Flink订阅Kafka消息队列实战案例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!