hello,大家好,这里是bang___bang_,在上两篇中我们讲解了进程的概念、状态和进程地址空间,本篇讲解进程的控制!!包含内容有进程创建、进程等待、进程替换、进程终止!!
附上前2篇文章链接:
Linux——操作系统进程详解!!(建议收藏细品!!)_bang___bang_的博客-CSDN博客
[Linux]环境变量 进程地址空间(虚拟内存与物理内存的关系)_bang___bang_的博客-CSDN博客
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-1.png)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-2.gif)
目录
1️⃣计算机四个重要概念
2️⃣进程创建
🍙fork函数初识
🍙fork返回值
🍙fork调用失败原因
3️⃣进程终止
🍙进程终止的场景
🍙退出码
🍥查看退出码echo
🍥字符串格式查看错误信息strerror
🍥退出码讲解
🍙进程常见退出方法
🍥_exit函数——系统调用接口
🍥exit函数——C库函数
🍥return退出
4️⃣进程等待
🍙进程等待必要性
🍙进程等待的方法
🍥wait方法
🍥waitpid方法
5️⃣进程程序替换
🍙替换原理
🍙替换函数
🍥execl函数
🍥execv函数
🍥execlp函数
🍥execle函数
🍥execvp函数
🍥execvpe函数
🍥execve函数(系统调用)
1️⃣计算机四个重要概念
✦竞争性:系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级
✦独立性:多进程运行,需要独享各种资源,多进程运行期间互不干扰
✦并行:多个进程在多个CPU下分别,同时进行运行,这称之为并行
✦并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
2️⃣进程创建
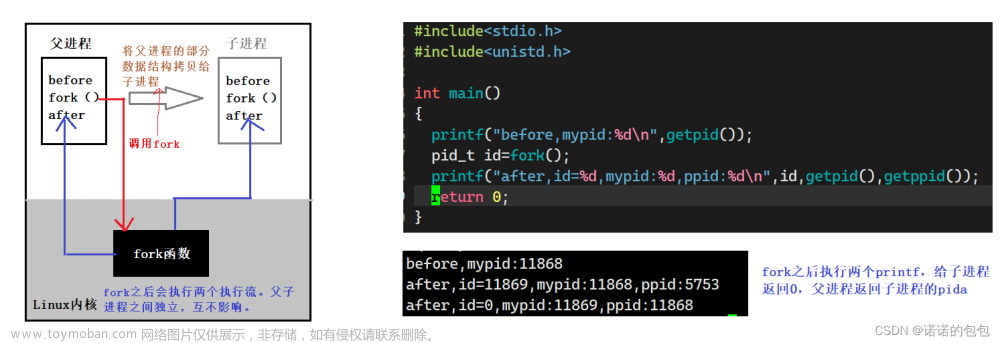
fork创建子进程,操作系统都做了什么?
fork创建子进程,系统多了一个进程。
进程=内核数据结构+进程代码和数据!
🍙fork函数初识
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-3.png)
- 创建子进程:失败返回-1,成功返回子进程PID给父进程,0返回给子进程
进程调用fork,当控制转移到内核中的fork代码后,内核做:
★分配新的内存块和内核数据结构给子进程
★将父进程部分数据结构内容拷贝至子进程
★添加子进程到系统进程列表当中
★fork返回,开始调度器调度
在进程详解篇,我提到过父子进程代码共享。
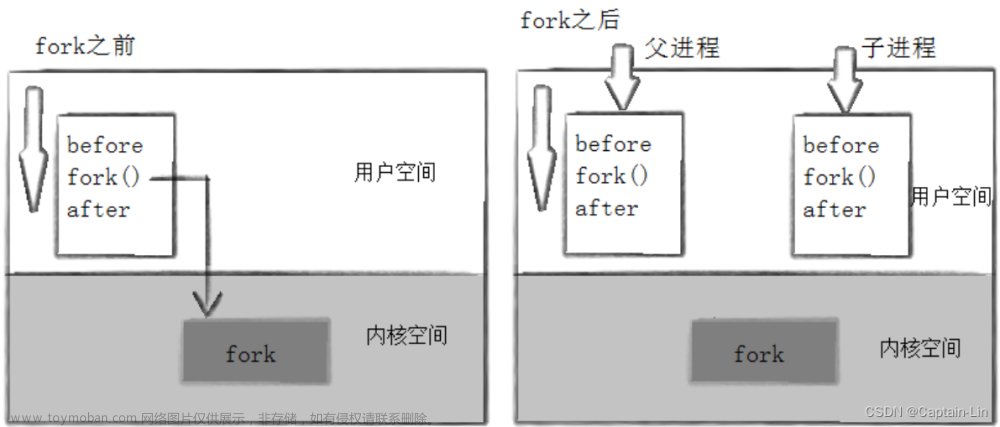
那么有个问题:是父进程所有的代码子进程都共享呢?还是在fork函数之后的代码才共享?
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-4.png)
🌰写一段fork代码看看结果(提示:眼见不一定为实)
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<stdlib.h>
int main()
{
int num=0;
int*p=#
printf("Begin:pid:%d,&num:%p\n",getpid(),p);
pid_t id=fork();
if(id<0)
{
perror("fork");
}
printf("After:pid:%d,fork return %d,&num:%p\n",getpid(),id,p);
return 0;
}
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-5.png)
根据结果我们发现Begin在子进程并没有执行,但这能表示子进程没有共享父进程的Begin代码吗?
答案是不是的!!!实际上子进程也共享到了父进程的Begin语句,只不过CPU中有个EPI寄存器,他保存了进程的上下文信息,使得子进程以为fork是他的开始,从fork语句后开始执行!!
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-6.png)
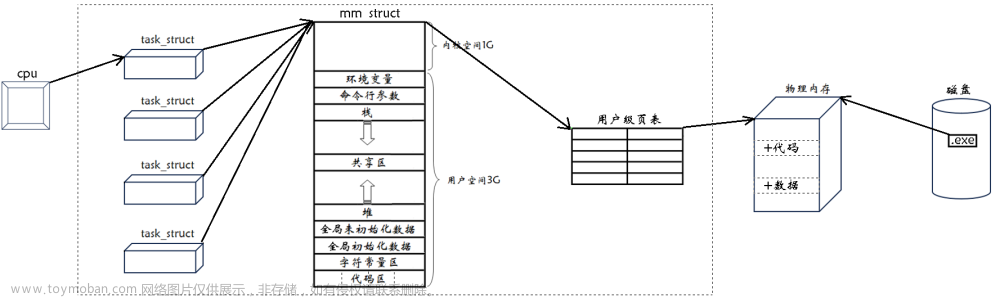
创建子进程,给子进程分配对应的内核空间结构,必须子进程自己独有,因为进程具有独立性!理论上,子进程也要有自己的代码和数据!可是一般而言,我们创建的子进程没有加载的过程(代码和数据一般是从磁盘上加载到的程序),也就是说,子进程没有自己的代码和数据!所以,子进程只能“使用”父进程的代码和数据!
代码:都是不可被写的,只能读取,所以父子共享!
数据:可能被修改的,所以,必须分离!
🍙fork返回值
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-7.png)
★子进程返回0
★父进程返回子进程的pid
★出错返回-1
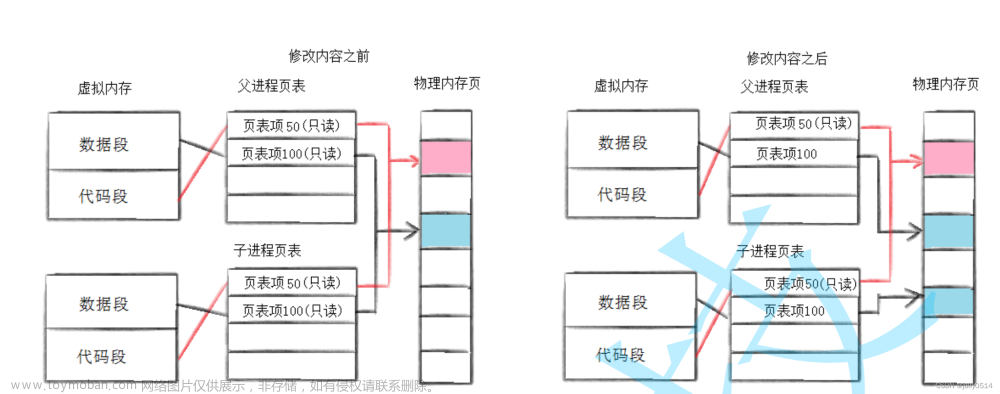
为什么fork会有2个返回值?是因为写时拷贝!!
在进程地址空间中我有讲解,这里再简单讲解一下!
基于进程的独立性,父子进程的数据必须分离,但是对于只读的数据我们也进行拷贝的话,对内存太过于浪费,所以出现了一种新的技术:写时拷贝技术!
写时拷贝,是一种延时申请技术,可以提高整机内存的使用率。
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-8.png)
子进程执行读权限的时候,父子进程页表映射到同一物理内存,当执行写权限时,OS重新拷贝一份数据到物理内存上,同时子进程的页表断开原来的映射关系,映射到拷贝数据的物理地址。
🍙fork调用失败原因
★系统中有太多的进程
★实际用户的进程数超过了限制
3️⃣进程终止
进程终止时,操作系统做了什么?
答:释放进程申请的相关内核数据结构和对应的数据和代码。本质:释放系统资源。
🍙进程终止的场景
✦代码运行完毕,结果正确
✦代码运行完毕,结果不正确
✦代码异常退出
🍙退出码
🍥查看退出码echo
//获取最近一个进程,执行完毕的退出码!
echo $?![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-9.png)
问题:main函数返回值的意义是什么?为什么总是0?
并不是总是0,返回值是进程的退出码!0表示进程运行结果正确,非0表示进程运行结果错误。
返回值的意义:返回给上一级进程,用来评判该进程执行结果用的,可以忽略。让上层能根据程序的退出码定位代码出错的原因。非0值有无数个,不同的非0值就可以标识不同的错误原因!!从而给我们的程序在运行结束之后,结果不正确时,方便定位错误的原因细节!
🍥字符串格式查看错误信息strerror
为了方便我们查看对应的错误是什么,C库提供了一个函数strerror,将错误以字符串的形式打印。
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-10.png)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-11.png)
🍥退出码讲解
退出码在status参数中!
status并不是按照整数来整体使用的!而是按照bit位的方式,将32个bit位进行划分(位图)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-12.png)
上图是status的低16位示意图。
系统提供了2个宏来获取退出码和退出信号:
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-13.png)
WIFEXITED(status) //是否正常退出
WEXITSTATUS(status) //若正常退出,获取退出码使用:grep -ER 'xxxx' /usr/include 进行查找
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-14.png)
进程异常退出,或者崩溃,本质是操作系统通过发送信号杀掉了你的进程!!
🍙进程常见退出方法
🍥_exit函数——系统调用接口
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-15.png)
参数:status 定义了进程的终止状态,父进程通过wait来获取该值。
#include<stdio.h>
#include<unistd.h>
int main()
{
_exit(-1);
} ![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-16.png)
将status设为-1,补码为全1,但是只有8位,所以退出码显示为255(1111 1111)
🍥exit函数——C库函数
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-17.png)
exit最后也会调用_exit,但在调用前还刷新了缓冲区。
🌰观察_exit和exit的区别:
/*_exit测试*/
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("hello");
_exit(0);
}
/*exit测试*/
#include<stdio.h>
#include<stdlib.h>
int main()
{
printf("hello");
exit(0);
}![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-18.png)
printf输出是对stdout标准输出文件写入,stdout文件的缓冲区刷新策略是行刷新,即遇到\n刷新!
测试中没有\n,也就不会刷新缓冲区,也就不会显示hello。
但是通过结果图我们可以看到系统调用_exit没有打印,C库函数exit有打印,也就是说exit还刷新了缓冲区。
🍥return退出
🌰return等同于执行exit
#include<stdio.h>
int main()
{
printf("hello");
return 0;
}
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-19.png)
现象和exit一样,main返回值当做exit的参数。
4️⃣进程等待
🍙进程等待必要性
🍙进程等待的方法
🍥wait方法
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-20.png)
参数:输出型参数,获取子进程退出状态,不关心则可以设置为NULL
返回值:成功,返回被等待进程的pid;失败,则返回-1。
🌰wait系统接口的阻塞式测试:
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-21.png)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-22.png)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-23.png)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-24.png)
🍥waitpid方法
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-25.png)
pid_ t waitpid(pid_t pid, int *status, int options);
返回值:
当正常返回的时候waitpid返回收集到的子进程的进程ID;
如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
pid:
pid=-1,等待任一个子进程。与wait等效。
pid>0.等待其进程ID与pid相等的子进程。
status:输出型参数!
WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出)
WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)
options:默认为0,表示阻塞等待
WNOHANG(非阻塞等待): 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进程的ID。
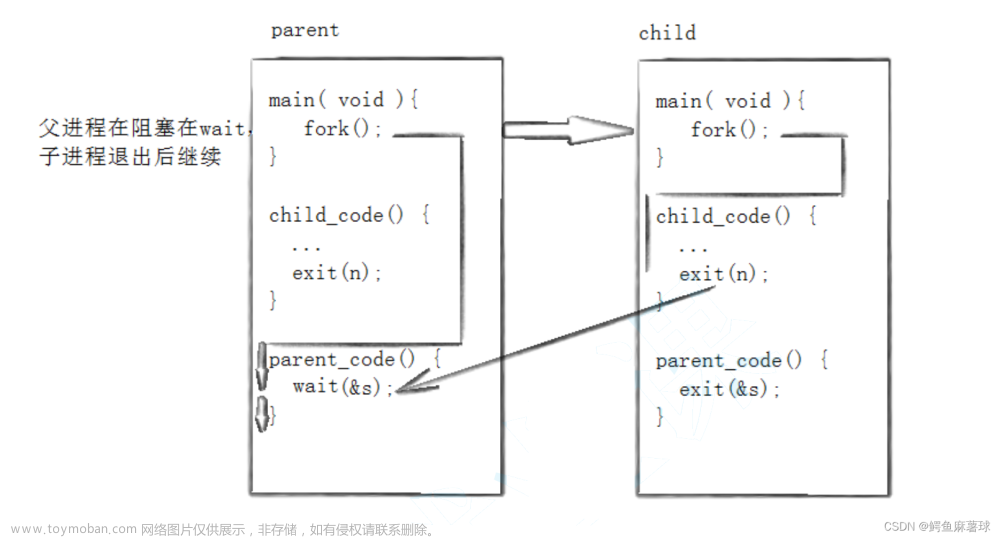
waitpid(pid,NULL,0)==wait(NULL)🌰waitpid系统接口的阻塞式测试:
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-26.png)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-27.png) 结果与wait一致。
结果与wait一致。
🌰 等待回收僵尸进程:
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-28.png)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-29.png)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-30.png)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-31.png)
🌰waitpid非阻塞式轮询检测测试:
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-32.png)
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/wait.h>
#include<sys/types.h>
//非阻塞等待测试代码
int main()
{
pid_t id=fork();
if(id==0)
{
//子进程
int cnt=5;
while(cnt)
{
printf("我是子进程:%d\n",cnt--);
sleep(1);
}
exit(11); //退出码11,仅用来测试
}
else{
int quit=0;
while(!quit)
{
int status=0;
pid_t res=waitpid(-1,&status,WNOHANG);//以非阻塞方式等待
if(res>0)
{
//等待成功&&子进程退出
printf("等待子进程退出成功,退出码:%d\n",WEXITSTATUS(status));
quit=1;
}
else if(res==0)
{
//等待成功&&但子进程并未退出
printf("子进程还在运行中,暂时还没有退出,父进程可以再等一等,处理其他事情\n");
}
else
{
//等待失败
printf("wait失败!\n");
quit=1;
}
sleep(1);
}
}
}
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-33.png)
问题:父进程通过wait/waitpid可以拿到子进程的退出结果,为什么要用wait/waitpid函数呢?直接全局变量不行吗?
答:不行,因为进程具有独立性,数据就要发生写实拷贝,父进程无法拿到正确的退出结果。
问题:既然进程是具有独立性的,进程退出码,不也是子进程的数据吗?父进程又凭什么拿到呢?
答:僵尸进程:至少要保留该进程的PCB信息!task_struct里面保留了任何进程退出时的退出结果信息!!
wait/waitpid本质是读取子进程的task_struct结构中的(退出码:exit_code,退出信号exit_signal)
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-34.png)
5️⃣进程程序替换
之前:fork()之后,父子各自执行父进程代码的一部分;父子代码共享,数据写时拷贝各自一份!
现在:如果子进程就想执行一个全新的程序呢?
想有自己的代码!就需要进程的程序替换,来完成这个功能。
🍙替换原理
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-35.png)
🍙替换函数
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-36.png)
| 函数名 | 参数格式 | 是否带路径 | 是否使用当前环境变量 |
| execl | 列表 | 不是 | 是 |
| execlp | 列表 | 是 | 是 |
| execle | 列表 | 不是 | 不是,需自己组装环境变量 |
| execv | 数组 | 不是 | 是 |
| execvp | 数组 | 是 | 是 |
| execvpe | 数组 | 是 | 不是,需自己组织环境变量 |
下面我们对各函数进行测试,测试使用ls命令替换程序。模板如下:
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-37.png)
🍥execl函数
🌰execl的使用测试:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/wait.h>
int main(int argc,char* argv[],char* env[])
{
pid_t id=fork();
if(id==0)
{
//子进程
printf("子进程开始运行,pid:%d\n",getpid());
sleep(3);
char* const _argv[]={
(char*) "ls",
(char*) "-a",
(char*) "-l",
NULL
};
//execl函数,传递参数列表
execl("/usr/bin/ls","ls","-a","-l",NULL);
exit(1);
}
else
{
//父进程
printf("父进程开始运行,pid:%d\n",getpid());
int status=0;
pid_t id=waitpid(-1,&status,0);//阻塞等待
if(id>0)
{
printf("wait seccess,exit code:%d\n",WEXITSTATUS(status));
}
}
return 0;
}
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-38.png)
execl是程序替换,调用该函数成功后,会将当前进程的所有的代码和数据都进行替换,包括以及执行的和没有执行的!(一旦调用成功,后面的所有代码都不会被执行!)
🍥execv函数
🌰execv的使用测试:
//execv函数,传递数组
execv("/usr/bin/ls",_argv);![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-39.png)
🍥execlp函数
🌰execlp的使用测试:
//execlp函数,传递文件名(无需路径)和参数列表
execlp("ls","ls","-a","-l",NULL);![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-40.png)
🍥execle函数
🌰execle的使用测试:
//execle函数,传递参数列表和组装的环境变量
execle("/usr/bin/ls","ls","-a","-l",NULL,env);![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-41.png)
🍥execvp函数
🌰execvp的使用测试:
//使用execvp函数,传递文件名和数组
execvp("ls",_argv);![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-42.png)
🍥execvpe函数
🌰execvpe的使用测试:
//execvpe函数,传递文件名,数组,需组织环境变量
execvpe("ls",_argv,env);![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-43.png)
🍥execve函数(系统调用)
上面是exec系列的函数,事实上他们都调用execve,只有execve是真正的系统调用
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-44.png)
| 函数名 | 参数格式 | 是否带路径 | 是否使用当前环境变量 |
| execve | 数组 | 不是 | 不是,需自己组织环境变量 |
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-45.png)
🌰execve的使用测试:
exec.c:
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/wait.h>
int main(int argc,char* argv[],char* env[])
{
pid_t id=fork();
if(id==0)
{
//子进程
printf("子进程开始运行,pid:%d\n",getpid());
sleep(3);
char* const _argv[]={
(char*) "ls",
(char*) "-a",
(char*) "-l",
NULL
};
char* const _argv_mycmd[]={(char*)"mycmd",(char*)"-a",NULL};
char* const _env_mycmd[]={(char*)"My_Path=11111",NULL};
//系统调用execve
execve("./mycmd",_argv_mycmd,_env_mycmd);
exit(1);
}
else
{
//父进程
printf("父进程开始运行,pid:%d\n",getpid());
int status=0;
pid_t id=waitpid(-1,&status,0);//阻塞等待
if(id>0)
{
printf("wait seccess,exit code:%d\n",WEXITSTATUS(status));
}
}
return 0;
}mycmd.c:
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
int main(int argc,char* argv[])
{
if(argc!=2)
{
printf("can not execute!\n");
exit(1);
}
printf("获取环境变量:My_Path:%s\n",getenv("My_Path"));
if(strcmp(argv[1],"-a")==0)
{
printf("hello a!\n");
}
else if(strcmp(argv[1],"-b")==0)
{
printf("hello b!\n");
}
else{
printf("default!\n");
}
return 0;
}
![[Linux]进程控制详解!!(创建、终止、等待、替换),我在地球学Linux,linux,运维,进程控制,进程创建,进程替换,进程等待,进程终止](https://imgs.yssmx.com/Uploads/2023/07/614684-46.png)
成功将子进程程序替换为mycmd。
问题:为什么要创建子进程,在子进程中进行进程替换?
——如果不创建,那么我们替换的进程只能是父进程,如果创建了,替换的进程就是子进程,而不影响父进程。为了不想影响父进程,我们想让父进程聚焦在读取数据,解析数据,指派进程执行代码的功能!文章来源:https://www.toymoban.com/news/detail-614684.html
文末结语,本篇结合前2篇内容详细讲解了进程控制,包含:进程创建,进程终止,终止码,_exit,进程等待的必要性以及方法(wait,waitpid)阻塞式等待和非阻塞式等待,进程程序替换的替换原理以及6大替换函数和系统调用execve替换子进程程序,图文并茂,使用例子测试代码。文章来源地址https://www.toymoban.com/news/detail-614684.html
到了这里,关于[Linux]进程控制详解!!(创建、终止、等待、替换)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!