推荐
连分布式ID都理解不了,你是刚培训出来冒充面试官的吧
1 分布式id、系统id、业务id以及主键之间的关系
- 分布式ID、系统ID、业务ID和主键的关系:
-
分布式ID:在分布式系统中,由于存在多个独立的节点,为了保证每个节点生成的ID都是全局唯一的,就需要用到分布式ID。它是全局唯一的,可以用作数据库的主键。
-
系统ID:一般用来在一个系统或者平台内部区分不同的用户、订单等,不一定是全局唯一的,所以不能用作分布式系统中的主键。
-
业务ID:业务ID是根据业务逻辑生成的ID,它的生成规则可能会包含一些业务信息,如时间、地点等。它可以是全局唯一的,也可以只在某个业务范围内唯一。
-
主键:数据库表中的主键是用来唯一标识一条记录的,它必须是唯一的。在分布式系统中,主键一般会使用分布式ID来保证全局唯一。
2 为什么不能用主键id充当订单id
- 为什么不能用主键ID充当订单ID?
主键ID是数据库中用于唯一标识记录的,而订单ID是业务中用来标识一个订单的。虽然在技术上可能可以使用主键ID作为订单ID,但这样做会有一些问题:
-
从业务逻辑的角度看,订单ID一般需要包含一些业务相关的信息,如时间、订单类型等,而主键ID通常是无业务含义的。
-
主键ID可能会由数据库自动递增生成,如果直接暴露给用户,可能会泄露一些敏感信息,如订单数量等。
-
如果系统升级或迁移,主键ID可能会发生改变,这会影响到业务的持续性。
3 为什么业务id和主键id不能一样
- 为什么业务ID和主键ID不能一样?
业务ID和主键ID的生成规则和用途是不一样的。业务ID是根据业务逻辑生成的,可能会包含一些业务相关的信息,而主键ID一般是数据库自动生成的,没有业务含义。
另外,业务ID可能会因为业务的变化而变化,而主键ID一旦确定,就不应该发生改变。如果把业务ID和主键ID设置为一样的,那么当业务ID需要改变时,就可能会影响到数据库的主键,从而影响到数据的完整性。
4 分布式id是解决什么问题
- 分布式ID是解决什么问题?
分布式ID主要是解决分布式系统中全局唯一标识的问题。在分布式系统中,由于存在多个独立的节点,每个节点可能都需要生成ID,为了保证所有节点生成的ID都是全局唯一的,就需要使用分布式ID。
另外,分布式ID还可以解决一些其它的问题,如:
-
数据库的分片问题:通过合理的设计分布式ID,可以将数据均匀的分布在不同的数据库或者表中,提高查询的效率。
-
订单的生成问题:在电商等需要大量生成订单的业务中,分布式ID可以快速的生成大量的全局唯一的订单号。
-
数据追踪问题:在复杂的系统中,通过分布式ID,可以更容易的追踪一条数据的流转过程。
分库分表和扩展
1. 怎么分库分表:
分库分表是为了解决单一数据库或者单一数据表承载量问题的一种常用的方法。分库是将一个数据库的数据拆分到多个数据库中,分表则是将一个表的数据拆分到多个表中。以下是分库分表的一般步骤:
-
确定拆分的方式:分库还是分表,或者两者同时进行。这主要取决于你的系统瓶颈在哪里,是在单个数据库的处理能力,还是在单个表的数据量。
-
设计拆分规则:这通常需要根据业务特点来进行,常见的方式有按照用户ID、地理位置、时间等进行拆分。
-
修改应用程序:拆分后的数据库和表的结构与原来的不同,需要修改应用程序中的数据库操作代码。
-
数据迁移:将原来的数据按照新的拆分规则迁移到新的数据库和表中。
-
引入中间件:为了使应用程序对分库分表透明,通常会引入一些数据库中间件,如ShardingSphere、Mycat等。
2. 为什么分库分表要考虑引入一个横向扩展的分布式数据库呢?
横向扩展的分布式数据库,或称为数据库分片,能有效地处理大量数据和高并发的情况。通过将数据分散到多个数据库节点上,可以提高系统的处理能力和吞吐量,从而提高系统的可扩展性和稳定性。
另外,引入一个横向扩展的分布式数据库,还可以提高数据的可用性。如果一个节点出现故障,其他节点还可以继续提供服务,从而保证了系统的可用性。
最后,使用分布式数据库,可以简化分库分表的操作。很多分布式数据库产品,如CockroachDB、TiDB等,都提供了内建的分片功能,可以自动进行数据的分布和迁移,大大简化了分库分表的操作。
3. 分库分表跟ID的关系:
分库分表的策略往往与ID有关。ID是一个常用的拆分依据,例如:
-
可以按照用户ID进行拆分,比如将用户ID为奇数的用户的数据存储在一组数据库中,将用户ID为偶数的用户的数据存储在另一组数据库中。
-
可以按照订单ID进行拆分,比如按照订单ID的某几位进行哈希,然后根据哈希值来决定存储到哪个数据库或者哪个表中。
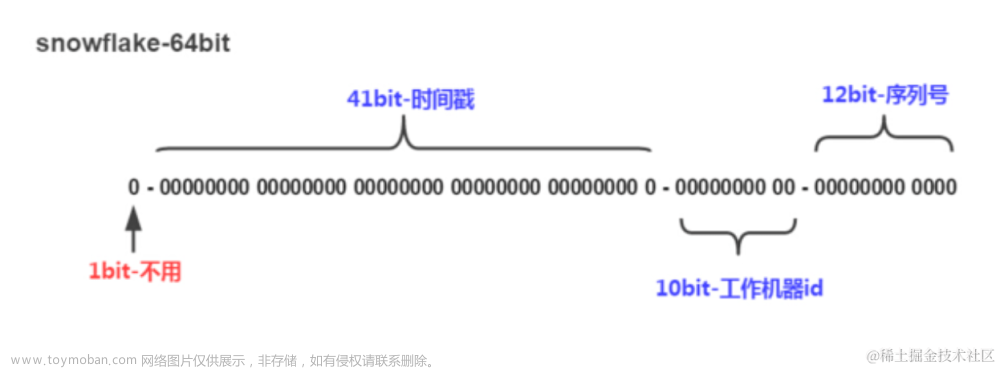
此外,分布式ID生成策略也常被用于分库分表。通过在ID中包含一些特定的信息,比如时间、机器编号等,可以用于直接或间接地决定该数据应该存储在哪个数据库或哪个表中。例如,Twitter的Snowflake算法就是一个常用的分布式ID生成策略。
分库分表、水平划分和垂直划分都是数据库架构中为了解决数据量大或者并发访问量大导致的性能问题而采用的策略。他们之间的关系和特点如下:
-
分库分表:分库是指将一个数据库拆分为多个数据库,分表则是将一个大表拆分为多个小表。分库分表可以既包含水平划分也可以包含垂直划分,具体取决于分库分表的方式。
-
水平划分(Horizontal Partitioning):是指按照数据的行进行拆分,将一个表的数据根据某些规则分散到多个具有相同结构的表中。例如,根据用户ID的奇偶性进行分表,所有奇数ID的用户数据存放在一张表,偶数ID的用户数据存放在另一张表。这种方式是分库分表的一种常用策略。
-
垂直划分(Vertical Partitioning):是指按照数据的列进行拆分,将一个表的某些列数据拆分到另一个或多个表中。例如,一个用户信息表,包含用户的基本信息和详细信息,可以将基本信息和详细信息分别存放在两个表中。垂直划分也可以用于分库,将不同的表放到不同的数据库中。
总结来说,分库分表是为了解决数据库性能问题的一个总体策略,而水平划分和垂直划分则是实现分库分表的具体技术手段。
水平划分和水平扩展数据库很像,都借用了分片吗
是的,水平划分和水平扩展的数据库(也称为分布式数据库或数据库分片)在很多方面是相似的,它们都是通过将数据分散到多个数据库或数据表中来提高系统的性能和可扩展性。实际上,你可以将水平划分看作是水平扩展的一个子集或者具体实现方式。
水平划分是在应用程序层面进行的,它需要应用程序知道如何路由到正确的数据库或表,因此通常需要修改应用程序的代码。而水平扩展的数据库,如Cassandra,MongoDB和Google Cloud Spanner等,通常会提供一个统一的接口,应用程序可以像访问一个单一的数据库一样访问它,由数据库系统自动处理数据的分布和路由。文章来源:https://www.toymoban.com/news/detail-614822.html
在水平划分和水平扩展的数据库中,都会使用到分片的概念。分片是指将数据划分为多个独立的部分,每个部分称为一个分片,每个分片可以存储在不同的物理设备上。分片的规则可以根据业务需求来定,常见的规则有按照范围分片、按照哈希分片等。文章来源地址https://www.toymoban.com/news/detail-614822.html
到了这里,关于分布式id、系统id、业务id以及主键之间的关系的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!