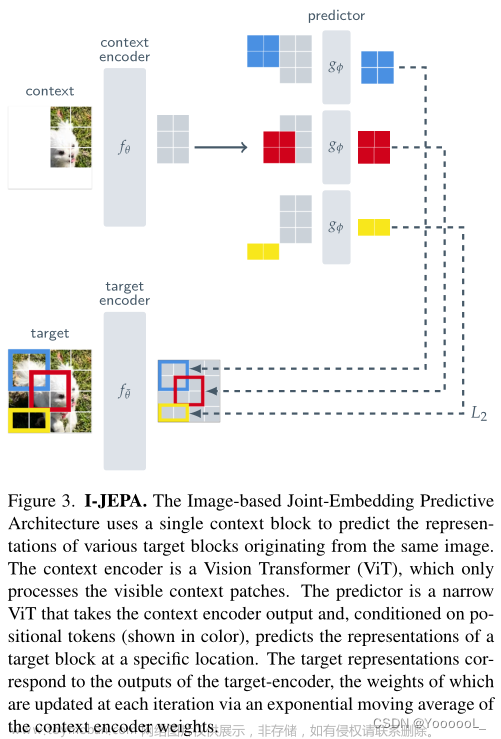
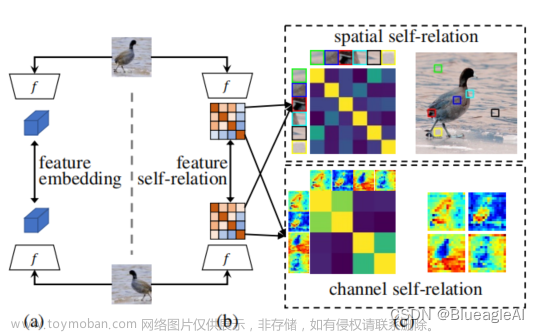
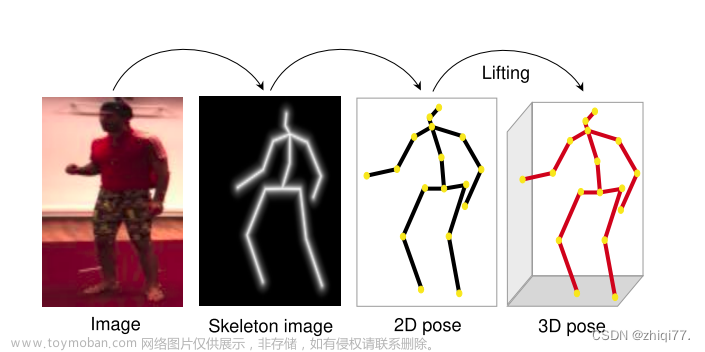
Recently, self-supervised learning (SSL) has achieved tremendous success in learning image representation. Despite the empirical success, most self-supervised learning methods are rather “inefficient” learners, typically taking hundreds of training epochs to fully converge. In this work, we
show that the key towards efficient self-supervised learning is to increase the number of crops from
each image instance. Leveraging one of the state-of-the-art SSL method, we introduce a simplistic form of self-supervised learning method called Extreme-Multi-Patch Self-Supervised-Learning
(EMP-SSL) that does not rely on many heuristic techniques for SSL such as weight sharing between
the branches, feature-wise normalization, output quantization, and stop gradient, etc, and reduces
the training epochs by two orders of magnitude. We show that the proposed method is able to
converge to 85.1% on CIFAR-10, 58.5% on CIFAR-100, 38.1% on Tiny ImageNet and 58.5% on
ImageNet-100 in just one epoch. Furthermore, the proposed method achieves 91.5% on CIFAR-10,
70.1% on CIFAR-100, 51.5% on Tiny ImageNet and 78.9% on ImageNet-100 with linear probing
in less than ten training epochs. In addition, we show that EMP-SSL shows significantly better
transferability to out-of-domain datasets compared to baseline SSL methods. We will release the
code in https://github.com/tsb0601/EMP-SSL.
https://arxiv.org/pdf/2304.03977.pdf


 文章来源:https://www.toymoban.com/news/detail-614980.html
文章来源:https://www.toymoban.com/news/detail-614980.html
文章来源地址https://www.toymoban.com/news/detail-614980.html
到了这里,关于EMP-SSL: TOWARDS SELF-SUPERVISED LEARNING IN ONETRAINING EPOCH的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!