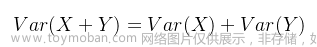- 对于神经网络的训练过程中,合适的参数初始化方法有助于更好的处理梯度消失和梯度爆炸问题。
- 通常有以下几种初始化方法:
1、随机初始化
- 随机初始化(Random Initialization):最简单的初始化方法是随机生成参数的初始值。可以根据一定的分布(如均匀分布或正态分布)从一个较小的范围内随机选择初始值,使得参数的初始状态具备一定的随机性。
2、Xavier初始化
-
Xavier 初始化(Xavier Initialization):在激活函数为Sigmoid或Tanh时表现较好。它根据连接权重的个数和输入/输出单元的数量来确定初始值的范围。权重的初始值从一个正态分布或者均匀分布中进行采样,并乘以一个较小的因子,以确保不会引起梯度消失或梯度爆炸问题。
-
通过保持输入和输出的方差一致(服从相同的分布)避免梯度消失和梯度爆炸问题
-
Xavier均匀分布:

-
Xavier正态分布:

-
Pytorch的实现:文章来源地址https://www.toymoban.com/news/detail-615734.html
torch.nn.init.xavier_uniform_(tensor, gain=1.0)
torch.nn.init.xavier_normal_(tensor, gain=1.0)
''
tensor: 一个n维的输入tensor
gain:可选的权重因子,用于缩放分布
''
3、He初始化
-
He 初始化(He Initialization):适用于ReLU(Rectified Linear Unit)激活函数的初始化方法。与Xavier初始化类似,但在计算初始值的范围时,将输入单元的数量乘以一个较大的因子,以更好地适应ReLU激活函数的特性。
-
He初始化根据权重的输入单元数来确定初始值的范围。
-
He均匀分布:

-
He正态分布:
 文章来源:https://www.toymoban.com/news/detail-615734.html
文章来源:https://www.toymoban.com/news/detail-615734.html -
Pytorch的实现:
torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
''
tensor:一个n维的输入tensor
a:负斜率,仅和leaky_relu一起使用
mode:'fan_in'(默认)或'fan_out'。选择“fan_in”保留了前向传递中权重方差的大小。选择“fan_out”保留向后传递的大小。
nonlinearity:非线性函数,建议仅与'relu'或'leaky_relu'(默认)一起使用。
''
4、权重预训练初始化
- 权重预训练初始化(Pretrained Initialization):如果已经有一个在相似任务上训练得到的预训练模型,可以使用该模型的参数作为神经网络的初始化值。这种方法通过迁移学习的方式来加速模型的收敛和提高性能。
5、零初始化
- 零初始化(Zero Initialization):将所有参数的初始值设置为零。然而,这种初始化方法在训练过程中会导致所有的参数都具有相同的更新值,无法破除对称性,因此很少使用。
到了这里,关于神经网络的初始化方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!