书接上回理解构建LLM驱动的聊天机器人时的向量数据库检索的局限性 - (第1/3部分)_阿尔法旺旺的博客-CSDN博客
其中我们强调了(1)嵌入生成,然后(2)使用近似近邻(ANN)搜索进行矢量搜索的解耦架构的缺点。我们讨论了生成式 AI 模型生成的向量嵌入之间的余弦相似性可能不是获取相关内容以进行提示的正确指标。我们还强调,在生产环境中,通过向量数据库存储、更新和维护嵌入非常昂贵。
在这篇文章中,我们将讨论使用学习索引的现代神经数据库学习如何缓解在嵌入和搜索相关的大多数问题方面提供对矢量数据库的重大升级。最后,我们将简要介绍我们正在构建的用于解决ThirdAI这些问题的神经数据库技术,我们将在下一篇文章中深入探讨。
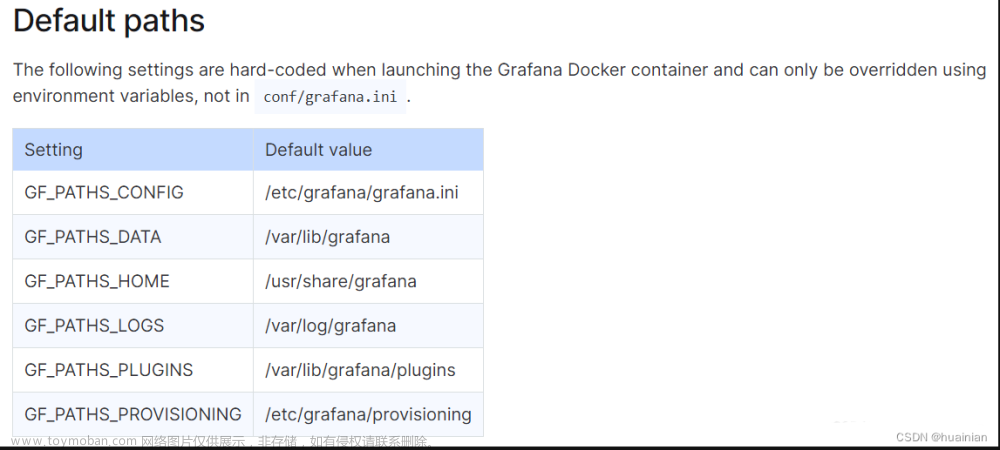
维护、存储和搜索嵌入的痛点
为了说明工程挑战,让我们考虑使用 Pubmed 35M 数据集构建 AI 代理的示例,这是一个符合行业标准的小型存储库。该数据集由大约 35 万个摘要组成,转化为大约 100 万个块,需要 100 万个嵌入。假设每个区块平均有 250 个代币,我们做出以下观察:
- 嵌入是非常重的对象:像 Ada-02 这样更简单的 OpenAI 模型为每个文本块生成大约 1500 维的嵌入。文本块约为 250 个标记(每个标记平均 4 个字符)。存储 100 万个 Pubmed 块大约需要 600GB 来存储嵌入。相比之下,未压缩的原始文本的完整数据只有200GB。更精确的LLM模型的嵌入维度超过12000,这将需要大约5.5 TB的存储空间,仅用于处理嵌入向量。
- 具有高维嵌入的近似近邻搜索(ANN)要么慢要么不准确:三十多年来,人们已经认识到,高维近邻搜索,即使是近似形式,从根本上也是困难的。大多数ANN算法,包括流行的基于图形的HNSW,都需要重量级的数据结构管理,以确保可靠的高速搜索。任何ANN专家都知道,搜索的相关性和性能在很大程度上取决于向量嵌入的分布,这使得它非常不可预测。此外,随着嵌入维度的增加,维护ANN、其搜索相关性和延迟可能会面临重大挑战。
- ANN索引的更新和删除存在问题:大多数现代向量数据库和ANN系统都是基于HNSW或其他图遍历算法构建的,其中嵌入向量是节点。由于这些图形索引的构造方式的性质,基于文档内容中的更改更新节点可能是一个非常缓慢的操作,因为它需要更新图形的边缘。出于同样的原因,删除文档也可能很慢。嵌入更新的动态性质甚至会影响检索的整体准确性。因此,对数据库的增量更新非常脆弱。从头开始重建通常成本太高。
- 检索失败很难评估和修复:当给定的文本查询无法检索相关的基础上下文,而是提供不相关或垃圾文本时,此失败可能有三个原因:a) 数据库中不存在相关的文本块,b) 嵌入质量很差,因此无法使用余弦相似性匹配两个相关文本,c) 嵌入很好, 但由于嵌入的分布,近似近邻算法无法检索到正确的嵌入。虽然原因 (a) 是可以接受的,因为问题似乎与数据集无关,但区分原因 (b) 和 (c) 可能是一个乏味的调试过程。此外,我们无法控制ANN搜索,并且优化嵌入可能无法解决问题。因此,即使在确定问题后,我们也可能无法修复它。
臭名昭著的维度诅咒:大量高维向量的ANN从根本上来说是困难和不可预测的。如果可以的话,避免整个过程。
持续自适应领域特定检索系统:无嵌入神经数据库
事实证明,有一个简单的AI系统可以进行端到端的训练,而无需昂贵,繁重和复杂的高维嵌入。关键概念是完全绕过嵌入过程,将检索问题作为可以端到端学习的神经预测系统来处理。在这种方法中,神经网络用于将给定的查询文本直接映射到相关文本。此过程需要数据结构以提高效率。每年都会在ICML,NeurIPS和ICLR等会议上发表大量论文,探讨这些想法。我们的设计是NeurIPS论文的简化版本,随后的研究在ICLR和KDD上发表。
神经数据库同样也涉及两个阶段,如下所述。
训练和插入(或索引)阶段:系统的前向工作流程如下图所示。

该系统利用强大的大型神经网络生成将文本映射到离散键的内存位置。这些预测键充当存储桶,用于插入和稍后检索相关文本块。从本质上讲,这是一个很好的旧哈希图,其中哈希函数是一个大型神经网络,经过训练来预测指针。为了训练网络,我们需要“语义相关”的文本对和标准的交叉熵损失。有关更多详细信息,请参阅 2019 年 NeurIPS 论文和随后的 KDD 2022 论文中提供的理论和实验比较。从数学上讲,可以证明模型的大小随文本块的数量以对数方式缩放,从而导致运行时间和内存的指数级改进。此方法不需要嵌入管理。
查询或检索阶段: 查询或检索阶段同样简单,如下图所示。

给定一个问题,我们使用经过训练的神经网络分类器来计算排名前几个桶的概率。然后,我们累积与这些顶级存储桶关联的所有 ChunkID。然后,对与问题相关的顶级存储桶及其相关相关性分数进行聚合和排序,以返回候选文本块的小型排名列表。然后,这些文本块被用作生成 AI 的提示,以生成最终的接地响应。
神经网络数据库相对于嵌入和ANN的主要优势
我们通过相同的Pubmed 35M AI-Agents应用程序来说明神经数据库的优势。文章来源:https://www.toymoban.com/news/detail-615749.html
- 没有嵌入导致指数压缩:我们的方法所需的额外内存仅在于存储神经网络的参数。我们发现,一个 25 亿参数的神经网络足以训练和索引完整的 Pubmed 35M 数据集。训练纯粹是自我监督的,因为我们不需要任何标记的样本。即使有所有的开销,我们只有不到 20GB 的存储空间用于完整索引。相比之下,使用矢量数据库存储 1500 维嵌入模型的数量至少为 600GB。这并不奇怪,因为使用嵌入模型,计算和内存随块数线性扩展。相比之下,我们的神经数据库仅随块的数量进行对数缩放,正如我们的NeurIPS论文所证明的那样。
- 像管理传统数据库一样管理插入和删除: 与基于图的近邻索引不同,神经数据库具有简单的 KEY、VALUE 类型哈希表,其中插入、删除、并行化、分片等都很简单,而且很容易理解。
- 超快速推理和显著降低成本: 推理延迟仅包括运行神经网络推理,然后是哈希表查找。最后,只有选定的区块只需要对少数候选者进行简单的加权聚合和排序。与嵌入和矢量数据库相比,您可能会看到检索速度快 10-100 倍。此外,借助ThirdAI突破性的稀疏神经网络训练算法,我们可以在普通CPU上训练和部署这些模型。
- 使用持续学习进行增量式的学习索引:可以使用语义含义相似的任何文本对来训练神经索引。这意味着,对专门针对任何理想的任务或领域,检索系统可以不断训练。获取用于训练的文本对并不难。首先,它们可以很容易地以自我监督的方式生成。此外,它们自然可用于任何具有用户交互的生产系统。
ThirdAI的亮点
在本系列的下一篇也是最后一篇博客文章(第 3/3 部分)中,我们将讨论 ThirdAI 的神经数据库生态系统,以及如何通过“动态稀疏性”来驯服像LLM这样的庞然大物,以便在任何数据处理系统中运行,无论是在云上还是在本地。我们还将介绍一组简单的自动调优 Python API。这些 API 使你能够在设备上利用下一代学习索引的强大功能。此外,我们将解释如何使用简单的CPU和几行Python代码创建一个接地气的Pubmed Q&A AI-Agent,同时通过本地环境(不需要互联网)保持隐私。如上一篇文章所示,使用标准的OpenAI嵌入和矢量数据库生态系统构建这样的AI代理通常需要花费数十万美元。您可以使用ThirdAI在您的个人设备上基本上免费获得所有这些。文章来源地址https://www.toymoban.com/news/detail-615749.html
到了这里,关于神经数据库:用于使用 ChatGPT 构建专用 AI 代理的下一代上下文检索系统 — (第 2/3 部分)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!