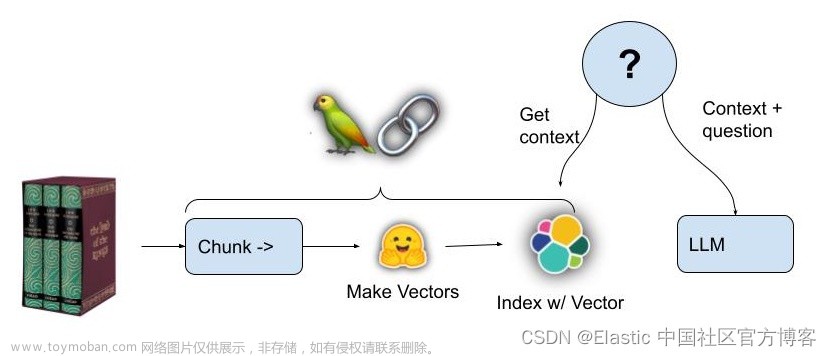
问题陈述
在信息过载的时代,根据上下文含义和用户意图而不是精确的关键字匹配来查找相关搜索结果已成为一项重大挑战。 传统的搜索引擎通常无法理解用户查询的语义上下文,从而导致相关性较低的结果。
在现代向量搜索之前,我们有 “传统”的 词袋(Bags of word - BOW)方法。 也就是说,我们获取一组要检索的“文档”(例如 Google 上的网页)。 每个文档都被转换为一组(词袋)单词,并用它来填充稀疏的 “frequency vector”。 流行的算法包括 TF-IDF 和 BM25。
这些稀疏向量由于其效率、可解释性和精确的术语匹配而在信息检索中非常受欢迎。 然而,它们还远非完美。
我们作为人类的本性与稀疏向量搜索不一致。 在搜索信息时,我们很少知道我们要查找的文档中将包含的确切术语。
密集嵌入模型在这个方向上提供了一些帮助。 通过使用密集模型,我们可以根据 “语义” 而不是术语匹配进行搜索。 然而,这些模型可能会更好。
我们需要大量数据来微调密集嵌入模型; 如果没有这个,它们就缺乏稀疏方法的性能。 对于很难找到数据并且特定领域术语很重要的利基领域来说,这是一个问题。
过去,有一系列的创可贴解决方案来解决这个问题; 从复杂和(仍然不完美)的两阶段检索系统,到查询和文档扩展或重写方法。 然而,这些都不是真正强大的解决方案。
幸运的是,在充分利用这两个世界方面已经取得了很大进展。 现在可以通过混合搜索合并稀疏和密集检索,并且可学习的稀疏嵌入有助于最大限度地减少稀疏检索的传统缺点。
解决方案:ELSER
Elastic 通过其检索模型 Elastic Learned Sparse EncodeR (ELSER) 引入了该问题的解决方案。 ELSER 是由 Elastic 训练的检索模型,使你能够执行语义搜索以检索更相关的搜索结果。 此搜索类型为你提供基于上下文含义和用户意图的搜索结果,而不是精确的关键字匹配。
ELSER 是一种域外(out-of-domain)模型,这意味着它不需要对你自己的数据进行微调,使其能够开箱即用地适应各种用例。 它将索引和搜索的段落扩展为术语集合,这些术语在不同的训练数据集中经常同时出现。 这些扩展术语不是搜索术语的同义词; 他们是 learned association。
Sparse 及 Dense
在信息检索中,向量嵌入以数值向量格式表示文档和查询。 这种格式允许我们搜索向量数据库并识别相似的向量。
稀疏向量和稠密向量是这种表示的两种不同形式,各有利弊。

TF-IDF 或 BM25 等稀疏向量具有高维数并且包含很少的非零值(因此,它们被称为 “稀疏”)。 稀疏向量背后有数十年的研究。 从而产生紧凑的数据结构和许多专为这些向量设计的高效检索算法。
密集向量的维度较低,但信息丰富,在大多数或所有维度上都具有非零值。 这些通常是使用 transformers 等神经网络模型构建的,通过这种方式,可以表示更抽象的信息,例如某些文本背后的语义。
总的来说,两种方法的优缺点可以概括如下:
Sparse
| 优点 | 缺点 |
|---|---|
| + 通常检索速度更快 | - 性能无法比基线显着提高 |
| + 良好的基线性能 | - 性能无法比基线显着提高 |
| + 不需要模型微调 | - 存在词汇不匹配问题 |
| + 术语的精确匹配 |
Dense
| 优点 | 缺点 |
|---|---|
| + 通过微调可以超越稀疏 | - 需要训练数据,在资源匮乏的场景下很难做到 |
| + 使用类似人类的抽象概念进行搜索 | - 不能很好地概括,特别是对于特定产品或服务的术语 |
| + 多模态(文本、图像、音频等)和跨模态搜索(例如文本到图像) | - 比稀疏需要更多的计算和内存 |
| - 没有精确匹配 | |
| - 不容易解释 |
架构
ELSER 使用 Elasticsearch 排名 rank-feature 类型在索引时存储术语和权重,并在以后进行搜索。 要使用 ELSER,你必须具有适当的语义搜索订阅级别或激活试用期。更多关于订阅的信息,请参阅网站 订阅 | Elastic Stack 产品和支持 | Elastic。
如果关闭部署自动扩展,则 Elasticsearch Service 中用于部署和使用 ELSER 模型的最小专用 ML 节点大小为 4 GB。 建议打开自动缩放,因为它允许你的部署根据需求动态调整资源。
KNN 与 ELSER:
Elasticsearch 的 k 最近邻 (KNN) 搜索和 ELSER (Elastic Learned Sparse EncodeR) 都提供强大的搜索功能,但它们是针对不同类型的搜索任务而设计的,并且以根本不同的方式工作。
Elasticsearch 中的 KNN 搜索
Elasticsearch 中的 KNN 搜索功能使你能够在高维空间中查找给定向量的 “最近邻居(nearest neigbors)”。 这对于图像搜索、产品推荐和异常检测等用例特别有用,在这些用例中,你可以将项目表示为向量,并且希望查找向量空间中相似的其他项目。
KNN 搜索的工作原理是对每个向量进行索引,然后使用距离函数(例如 Euclidean 距离或余弦相似度)来查找最接近给定向量的向量。 这是相似性搜索的一种形式,其目标是查找与给定项目相似的项目。
Elasticsearch 中的 ELSER
另一方面,ELSER 是由 Elastic 训练的检索模型,使你能够执行语义搜索以检索更相关的搜索结果。 此搜索类型为您提供基于上下文含义和用户意图的搜索结果,而不是精确的关键字匹配。
ELSER 是一种域外(out-of-domain)模型,这意味着它不需要对你自己的数据进行微调,使其能够开箱即用地适应各种用例。 它将索引和搜索的段落扩展为术语集合,这些术语在不同的训练数据集中经常同时出现。 这些扩展术语不是搜索术语的同义词; 他们是 learned association。
比较
虽然 KNN 和 ELSER 都可用于提高搜索结果的相关性,但它们是针对不同类型的数据和用例而设计的。 KNN 最适合以下用例:你可以将条目表示为向量,并且你希望根据其向量表示找到相似的条目。 另一方面,ELSER 专为你想要查找与给定查询语义相关的搜索结果的用例而设计,即使它们不共享精确的关键字匹配。
在性能方面,KNN 搜索可能是计算密集型的,尤其是在高维空间中,并且可能需要大量资源来提供快速搜索结果。 另一方面,ELSER 使用学习模型来扩展搜索词,这可以更有效,但可能需要合适的订阅级别或试用期激活。
总之,KNN 和 ELSER 之间的选择取决于您的用例的具体要求和数据的性质。
代码示例
在 Kibana 中,你可以从 Machine Learning > Trained Models、Enterprise Search > Indices 或使用开发控制台下载和部署 ELSER。你可以参考文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR” 来在自己的电脑上部署 ELSER 模型。
使用开发控制台
在 Kibana 中,导航到开发控制台并通过运行以下 API 调用来创建 ELSER 模型配置:
PUT _ml/trained_models/.elser_model_1
{
"input": {
"field_names": [
"text_field"
]
}
}上述命令返回:
{
"model_id": ".elser_model_1",
"model_type": "pytorch",
"model_package": {
"packaged_model_id": "elser_model_1",
"model_repository": "https://ml-models.elastic.co",
"minimum_version": "8.8.0",
"size": 438123276,
"sha256": "95f645a3ab8dc66a33de7892391a41ef4fc609a74d21d7b3f7fdd973d58dfe06",
"metadata": {},
"tags": [],
"vocabulary_file": "elser_model_1.vocab.json"
},
"created_by": "api_user",
"version": "8.8.2",
"create_time": 1690432777746,
"model_size_bytes": 0,
"estimated_operations": 0,
"license_level": "platinum",
"description": "Elastic Learned Sparse EncodeR v1 (Tech Preview)",
"tags": [
"elastic"
],
"metadata": {},
"input": {
"field_names": [
"text_field"
]
},
"inference_config": {
"text_expansion": {
"vocabulary": {
"index": ".ml-inference-native-000001"
},
"tokenization": {
"bert": {
"do_lower_case": true,
"with_special_tokens": true,
"max_sequence_length": 512,
"truncate": "first",
"span": -1
}
}
}
},
"location": {
"index": {
"name": ".ml-inference-native-000001"
}
}
}使用带有部署 ID 的启动训练模型 deployment API 来部署模型:
POST _ml/trained_models/.elser_model_1/deployment/_start?deployment_id=for_search上述命令返回:
{
"assignment": {
"task_parameters": {
"model_id": ".elser_model_1",
"deployment_id": "for_search",
"model_bytes": 438123276,
"threads_per_allocation": 1,
"number_of_allocations": 1,
"queue_capacity": 1024,
"cache_size": "438123276b",
"priority": "normal"
},
"routing_table": {
"Gbl69vadQgK1nOqxUT8LaQ": {
"current_allocations": 1,
"target_allocations": 1,
"routing_state": "started",
"reason": ""
}
},
"assignment_state": "started",
"start_time": "2023-07-27T04:40:19.531125Z",
"max_assigned_allocations": 1
}
}部署完成后,我们可以通过 Kibana 来查看部署的结果:

ELSER 就可以在摄取管道或 text_expansion 查询中使用来执行语义搜索。
在摄取管道中使用 ELSER:
PUT _ingest/pipeline/my_pipeline
{
"description": "ELSER pipeline",
"processors": [
{
"inference": {
"model_id": ".elser_model_1",
"target_field": "ml",
"field_map": {},
"inference_config": {
"text_expansion": {
"results_field": "tokens"
}
}
}
}
]
}使用管道索引文档。设置管道后,你可以使用它索引文档:
PUT my_index
{
"mappings": {
"properties": {
"ml.tokens": {
"type": "rank_features"
},
"text_field": {
"type": "text"
}
}
}
}
PUT my_index/_doc/1?pipeline=my_pipeline
{
"text_field": "This is a sample document for ELSER."
}
PUT my_index/_doc/2?pipeline=my_pipeline
{
"text_field": "Elastic is a great company"
}最后,你可以使用匹配查询来查询索引文档:
GET my_index/_search
{
"_source":false,
"fields": [
"text_field"
],
"query": {
"text_expansion": {
"ml.tokens": {
"model_id": ".elser_model_1",
"model_text": "Sample"
}
}
}
}上面的搜索结果为:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 5.2040906,
"hits": [
{
"_index": "my_index",
"_id": "1",
"_score": 5.2040906,
"fields": {
"text_field": [
"This is a sample document for ELSER."
]
}
},
{
"_index": "my_index",
"_id": "2",
"_score": 0.028514616,
"fields": {
"text_field": [
"Elastic is a great company"
]
}
}
]
}
}我们再做一次搜索:
GET my_index/_search
{
"_source":false,
"fields": [
"text_field"
],
"query": {
"text_expansion": {
"ml.tokens": {
"model_id": ".elser_model_1",
"model_text": "Elastic Stack"
}
}
}
}上面显示的结果为:
{
"took": 73,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 13.001609,
"hits": [
{
"_index": "my_index",
"_id": "2",
"_score": 13.001609,
"fields": {
"text_field": [
"Elastic is a great company"
]
}
}
]
}
}我们再做一次搜索:
GET my_index/_search
{
"_source":false,
"fields": [
"text_field"
],
"query": {
"text_expansion": {
"ml.tokens": {
"model_id": ".elser_model_1",
"model_text": "ELK"
}
}
}
}上面的搜索结果为:
{
"took": 48,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.054624833,
"hits": [
{
"_index": "my_index",
"_id": "2",
"_score": 0.054624833,
"fields": {
"text_field": [
"Elastic is a great company"
]
}
}
]
}
}最后一个搜索:
GET my_index/_search
{
"_source":false,
"fields": [
"text_field"
],
"query": {
"text_expansion": {
"ml.tokens": {
"model_id": ".elser_model_1",
"model_text": "demo doc"
}
}
}
}结果为:文章来源:https://www.toymoban.com/news/detail-615849.html
{
"took": 56,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 4.6410522,
"hits": [
{
"_index": "my_index",
"_id": "1",
"_score": 4.6410522,
"fields": {
"text_field": [
"This is a sample document for ELSER."
]
}
},
{
"_index": "my_index",
"_id": "2",
"_score": 0.09583376,
"fields": {
"text_field": [
"Elastic is a great company"
]
}
}
]
}
}商业用例
ELSER(Elastic 的学习稀疏编码器)可以有效地用于以语义理解和上下文相关性为关键的各种用例。 这里有一些例子:文章来源地址https://www.toymoban.com/news/detail-615849.html
- 信息检索:在大型数据库或文档存储库中,ELSER 可用于检索与给定查询在语义上相关的文档,即使它们不共享精确的关键字匹配。 这在精确的信息检索至关重要的法律、学术或企业环境中特别有用。
- 电子商务搜索:电子商务平台可以使用 ELSER 来改进其搜索功能。 当客户搜索产品时,ELSER 可以根据搜索查询的语义上下文提供更相关的结果,从而改善购物体验并有可能增加销售额。
- 客户支持:ELSER 可用于客户支持系统,以更好地了解客户查询并提供更相关的解决方案。 例如,客户描述问题的方式可能与支持数据库中的措辞不完全匹配。 ELSER 可以帮助弥合这一差距并找到最相关的支持文档。
- 内容推荐:媒体平台可以使用 ELSER 来推荐与用户正在查看或已经查看的内容在语义上相关的内容。 这可以通过提供更多符合用户兴趣的内容来帮助保持用户的参与度。
- 社交媒体监控:公司可以使用 ELSER 监控社交媒体并了解有关其品牌的讨论背景。 这可以提供有关客户情绪和新兴趋势的宝贵见解。
- 语义 SEO(Search Engine Optimization):ELSER 可用于理解 Web 内容的语义上下文并针对搜索引擎进行优化。 这可以通过将网站内容与相关搜索查询的语义上下文更紧密地结合起来,帮助提高网站的搜索引擎排名。
到了这里,关于Elasticsearch:使用 ELSER 释放语义搜索的力量:Elastic Learned Sparse EncoderR的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[2.项目讲解篇],支持Linux/Windows部署安装](https://imgs.yssmx.com/Uploads/2024/02/776562-1.png)
![释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[1.安装部署篇],支持Linux/Windows部署安装](https://imgs.yssmx.com/Uploads/2024/02/744663-1.png)
![释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[1.安装部署篇--简洁版],支持Linux/Windows部署安装](https://imgs.yssmx.com/Uploads/2024/02/738297-1.jpeg)