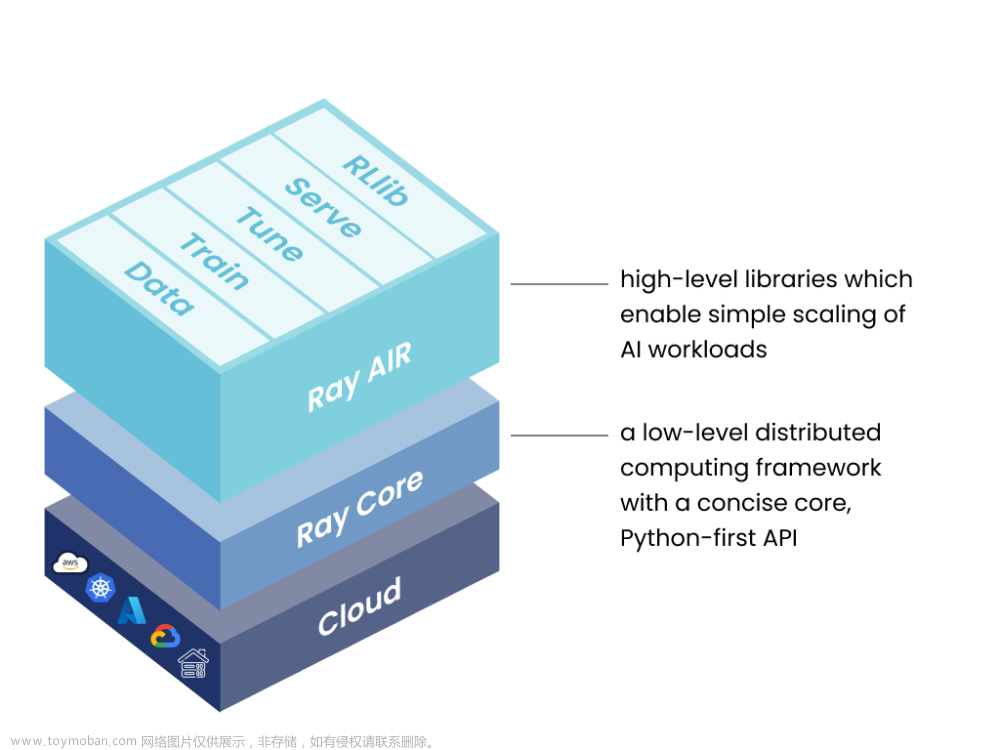
Ray是一个开源的分布式计算框架,专门用于构建高性能的机器学习和深度学习应用程序。它的目标是简化分布式计算的复杂性,使得用户能够轻松地将任务并行化并在多台机器上运行,以加速训练和推理的速度。Ray的主要特点包括支持分布式任务执行、Actor模型、异步任务执行、分布式数据集、超参数优化以及多框架支持。首先,Ray允许用户将计算任务拆分成多个小任务,并在分布式环境下并行执行。通过充分利用多台机器的计算资源,Ray显著提高了任务的执行效率。其次,Ray采用了Actor模型,这是一种并发编程模型,可以简化分布式应用程序的设计和编程。Actors是独立的、状态可变的对象,可以并行运行,从而提高了分布式计算的效率。Ray还支持异步任务执行,用户可以提交任务并继续进行其他操作,而无需等待任务完成。这种机制提高了计算资源的利用率,同时增加了灵活性。此外,Ray提供了分布式数据集的支持,自动将数据分布在多台机器上,从而支持数据并行训练和处理大规模数据集。Ray整合了Tune库,可以用于超参数优化和自动调参。通过优化模型的超参数配置,用户可以更快地找到最佳模型性能。最后,Ray与常见的机器学习和深度学习框架(如TensorFlow和PyTorch)无缝集成,为用户提供了灵活的选择,使得开发者可以更加便捷地构建复杂的分布式应用程序。总之,Ray是一个强大且易用的分布式框架,特别适用于需要处理大规模数据和资源密集型机器学习任务的场景。它为用户提供了高性能的分布式计算能力,帮助加速机器学习模型的训练和推理过程,为构建分布式机器学习应用程序提供了便利和效率。
以下是使用 Ray 来并行训练 XGBoost 模型的示例代码,可以作为使用 Ray 并行训练模型的一般指南。
以下是逐步指南:
-
**初始化Ray:**启动Ray以启用分布式计算。
-
**加载数据:**加载您的数据集。
-
**划分数据:**将数据集划分为训练集和测试集。
-
**定义XGBoost训练函数:**创建一个函数,用于在给定数据集上训练XGBoost模型。
-
**使用Ray进行并行训练:**使用Ray启动多个并行训练任务,每个任务使用不同的数据集。
-
**收集模型:**从不同的任务中收集训练好的XGBoost模型。
-
**模型集成:**使用集成方法(例如平均预测)来合并所有模型的预测结果。
-
**评估集成模型:**在测试集上评估集成模型的性能。
-
**关闭Ray:**关闭Ray会话以释放资源。
首先,你需要安装必要的包:
pip install ray[xgboost] xgboost以下是一个简单的示例,演示了如何使用 Ray 来并行训练 XGBoost 模型:
import ray
import xgboost as xgb
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 在给定数据分割上训练 XGBoost 模型的函数
def train_xgboost(data, labels):
dtrain = xgb.DMatrix(data, label=labels)
params = {
'objective': 'reg:squarederror',
'eval_metric': 'rmse',
'max_depth': 3,
'eta': 0.1,
'num_boost_round': 100
}
model = xgb.train(params, dtrain)
return model
if __name__ == "__main__":
# 初始化 Ray(确保有足够的资源可用)
ray.init(ignore_reinit_error=True)
# 加载数据集
data, labels = load_boston(return_X_y=True)
# 将数据划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
# 使用 Ray 进行并行训练
train_results = ray.get([ray.remote(train_xgboost).remote(X_train, y_train) for _ in range(4)])
# 使用训练好的模型在测试集上进行预测
predictions = [model.predict(xgb.DMatrix(X_test)) for model in train_results]
# 对所有模型的预测结果求平均
avg_predictions = sum(predictions) / len(predictions)
# 计算均方根误差(RMSE)
rmse = mean_squared_error(y_test, avg_predictions, squared=False)
print(f"Ensemble RMSE: {rmse}")
# 关闭 Ray
ray.shutdown()
代码实现了使用Ray进行XGBoost模型的并行训练,并通过模型集成(ensemble)来提高预测性能。让我们逐行解释代码的功能:
import ray
import xgboost as xgb
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
首先,导入所需的库:ray用于并行计算,xgboost用于构建和训练XGBoost模型,load_diabetes用于加载糖尿病数据集,train_test_split用于将数据集分为训练集和测试集,mean_squared_error用于计算均方根误差。
def train_xgboost(data, labels):
dtrain = xgb.DMatrix(data, label=labels)
params = {
'objective': 'reg:squarederror',
'eval_metric': 'rmse',
'max_depth': 3,
'eta': 0.1,
'num_boost_round': 100
}
model = xgb.train(params, dtrain)
return model
定义了一个名为train_xgboost的函数,该函数用于训练XGBoost模型。函数中的data是特征数据,labels是对应的标签数据。函数首先将特征数据和标签数据转换为xgb.DMatrix对象,然后定义了一些XGBoost模型的训练参数,并使用这些参数训练了一个XGBoost模型。最后,函数返回训练好的模型。
if __name__ == "__main__":
ray.init(ignore_reinit_error=True)
在主程序中,初始化Ray并忽略重新初始化的错误。这个if __name__ == "__main__":部分确保只有当该文件作为主程序运行时才会执行以下代码。
data, labels = load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
加载糖尿病数据集,并将数据集划分为训练集和测试集,其中测试集占总数据集的20%。
train_results = ray.get([ray.remote(train_xgboost).remote(X_train, y_train) for _ in range(4)])
使用Ray进行并行训练,启动4个并行任务来训练4个XGBoost模型。每个任务都会调用train_xgboost函数进行训练,其中训练集数据作为参数传递给函数。ray.remote修饰器将函数调用封装为Ray任务,ray.get用于收集并返回任务的结果。
predictions = [model.predict(xgb.DMatrix(X_test)) for model in train_results]
使用训练好的模型对测试集X_test进行预测,并将预测结果存储在predictions列表中。
avg_predictions = sum(predictions) / len(predictions)
对所有模型的预测结果进行平均,这是模型集成的一种方式。通过将多个模型的预测结果平均化,可以获得更稳定和准确的预测。
rmse = mean_squared_error(y_test, avg_predictions, squared=False)
print(f"Ensemble RMSE: {rmse}")
计算模型集成后的均方根误差(RMSE),mean_squared_error函数用于计算均方根误差。最后,打印模型集成的均方根误差。
ray.shutdown()
关闭Ray会话,释放资源。文章来源:https://www.toymoban.com/news/detail-616079.html
这段代码的目标是使用并行计算和模型集成的方法来改进XGBoost模型的性能,特别是在大规模数据集上,通过并行训练多个模型可以加快训练速度,而模型集成则有望提高预测的准确性和稳定性。文章来源地址https://www.toymoban.com/news/detail-616079.html
到了这里,关于机器学习分布式框架ray运行xgboost实例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!