一、插入数据优化
1.1 批量插入
如果有多条数据需要同时插入,不要每次插入一条,然后分多次插入,因为每执行一次插入的操作,都要进行数据库的连接,多个操作就会连接多次,而一次批量操作只需要连接1次
1.2 手动提交事务
因为Mysql默认每执行一次操作,就会提交一次事务,这样就会涉及到频繁的事务的开启与关闭
start transaction; insert into 表名 values(),(),(); insert into 表名 values(),(),(); insert into 表名 values(),(),(); commit;
1.3 主键顺序插入
主键一般是默认自增的,但是也可以手动增加,这里不建议手动乱序增加,而是使用默认的顺序增加,原因会在后面解释。
1.4 大批量插入数据
如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用Mysql数据库提供的load指令进行插入,
首先在连接数据库的时候需要加上 --local-infile 参数
mysql --local-infile -u root -p
在使用本地文件加载功能的时候,需要先查看本地加载文件选项是否开启的
mysql> select @@local_infile; +----------------+ | @@local_infile | +----------------+ | 0 | +----------------+ 1 row in set (0.00 sec)
说明1:0表示本地加载文件并未开启
开启本地加载文件的语句
mysql> set global local_infile = 1; Query OK, 0 rows affected (0.01 sec) mysql> select @@local_infile; +----------------+ | @@local_infile | +----------------+ | 1 | +----------------+ 1 row in set (0.00 sec)
创建一个空表tb_user,其表结构如下
mysql> desc tb_user; +----------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | username | varchar(50) | NO | UNI | NULL | | | password | varchar(50) | NO | | NULL | | | name | varchar(20) | NO | | NULL | | | birthday | date | YES | | NULL | | | sex | char(1) | YES | | NULL | | +----------+-------------+------+-----+---------+----------------+ 6 rows in set (0.01 sec)
使用load加载本地文件 'tb_user_data.sql' 内容到新创建的表中,其中tb_user_data.sql中的测试数据如下
houlei@houleideMacBook-Pro Desktop % cat tb_user_data.sql 1,a,aa,aaa,2023-07-01,1 2,b,bb,bbb,2023-07-02,0 3,c,cc,ccc,2023-07-03,1 4,d,dd,ddd,2023-07-04,0 5,e,ee,eee,2023-07-05,1 6,f,ff,fff,2023-07-06,0 7,g,gg,ggg,2023-07-07,1 houlei@houleideMacBook-Pro Desktop %
使用load加载本地文件 'tb_user_data.sql' 内容到新创建的表中
mysql> load data local infile '/Users/houlei/Desktop/tb_user_data.sql' into table tb_user fields terminated by ',' lines terminated by '\n'; Query OK, 7 rows affected (0.01 sec) Records: 7 Deleted: 0 Skipped: 0 Warnings: 0
说明1: load data local infile 是加载本地文件的意思,
说明2:'/Users/houlei/Desktop/tb_user_data.sql'是文件路径
说明3:into table tb_user 是将文件中的数据,插入到tb_user表中
说明4:fields terminated by ',' 是说每个字段之间的数据是使用','分割的
说明5:lines terminated by '\n' 是说每一行之间的数据使用的是‘\n’分割的
说明6:本方法只是举例,在实际运用大数据量插入时100万条数据的插入至少要数分钟,如果使用load方法只需要十几秒
文章来源地址https://www.toymoban.com/news/detail-616244.html
二、主键优化
2.1 数据组织方式
在InnoDB储存引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table)IOT

说明1:在索引的B+数中所有的数据保存在叶子节点上,非叶子节点只保存主键key的值
说明2:索引中的各个节点都是保存在逻辑结构页上面的,一页默认大小16K
2.2 页分裂
页可以为空,也可以填充一半,也可以填充100%,每个页包含了2至N行数据,根据主键排列
情况1:主键顺序插入

说明1:row是行数据,每一页上可以存放多个行数据。
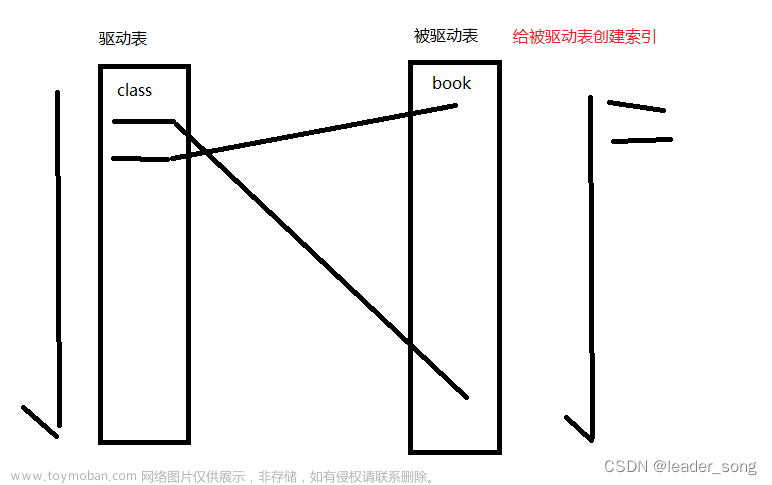
情况2:主键乱序插入

说明1:当我们想要在插入一个id=50的数据时,会发生页分裂

说明2:这时会将 1#page 页里面的数据超过 50% 的数据,移动到新开辟的 3#page 页中
说明3:然后将 id=50 的数据也拼接到 3#page 页中
说明4:这时就会出现一个问题,3#page 中的索引比 2#page 页中的索引小,所以还需要将 3#page 页前置,这就叫页分裂

2.3 页合并
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用
当页中删除的记录达到 merge_threshold (默认为页的50%),InnoDB 会开始寻找最靠近的页(前或者后)看看是否可以合并以优化空间使用

说明1:这时在 2#page 删除了13,14,15,16数据后,该页空余空间超过50%时就会寻找前一页或者后一页,是否同样有不满足50%,可以合并的

说明2:这时 1#page 页是满的,不能合并,3#page 页不满可以合并,所以 3#page 页迁移到 2#page 页中

说明3:这时如果在有数据20插入就可以直接插入到3#page页上了,这就是页合并。
2.4 主键设计原则
-
- 满足业务需求的情况下,尽量减低主键的长度。
- 插入数据时,尽量选择顺序插入,选择使用auto_incerment自增主键,
- 尽量不要用uuid作主键或者其他自然主键如身份证号,因为这个值是无需的,会存在页分裂情况。
三、order by优化
3.1 Using filesort
通过表的索引或者全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer 中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫FileSort排序
3.2 Using index
通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外的排序,操作效率高,即排序的列表字段符合覆盖索引。
3.3 案例
emp表结构:
mysql> desc emp; +-----------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-----------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | age | int | YES | | NULL | | | job | varchar(20) | YES | | NULL | | | salary | int | YES | | NULL | | | entrydate | date | YES | | NULL | | | managerid | int | YES | | NULL | | | dept_id | int | YES | MUL | NULL | | +-----------+-------------+------+-----+---------+----------------+ 8 rows in set (0.01 sec)
emp表中索引情况
mysql> show index from emp; +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | emp | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | YES | NULL | | emp | 1 | fk_dept | 1 | dept_id | A | 3 | NULL | NULL | YES | BTREE | | | YES | NULL | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
案例1:对查询结果进行按 salary 和 age 都进行升序排序
mysql> explain select salary,age from emp order by salary, age; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+ | 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 7 | 100.00 | Using filesort | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+ 1 row in set, 1 warning (0.00 sec)
说明1:Extra 中值为 Using filesort 说明是先查出来需要的数据,然后再排序的,效率不高。
说明2:为什么会出现Using filesort呢?因为查询的这些字段在查询之前是无须的,索引需要先将数据查询出来,然后再做排序,这样才能得到想要的排序好的数据。
案例2:给 salary 和 age 添加一个联合排序
mysql> create index salary_age_idx on emp(salary,age); Query OK, 0 rows affected (0.07 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show index from emp; +-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | emp | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | YES | NULL | | emp | 1 | fk_dept | 1 | dept_id | A | 3 | NULL | NULL | YES | BTREE | | | YES | NULL | | emp | 1 | salary_age_idx | 1 | salary | A | 7 | NULL | NULL | YES | BTREE | | | YES | NULL | | emp | 1 | salary_age_idx | 2 | age | A | 7 | NULL | NULL | YES | BTREE | | | YES | NULL | +-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ 4 rows in set (0.00 sec)
说明1:联合索引 salary_age_idx 中 salary 是第一索引字段,age 是第二索引字段
说明2:Collation 中A 代表升序,D 代表降序
案例3:再次使用 order by 对 salary 和 age 进行升序排序
mysql> explain select salary,age from emp order by salary,age; +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+-------------+ | 1 | SIMPLE | emp | NULL | index | NULL | salary_age_idx | 10 | NULL | 7 | 100.00 | Using index | +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select salary,age from emp order by salary; +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+-------------+ | 1 | SIMPLE | emp | NULL | index | NULL | salary_age_idx | 10 | NULL | 7 | 100.00 | Using index | +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
说明1:在做升序排列时,无论 order by 后面是组合索引的全部字段,还是只有部分字段,这时 Extra 的值都是Usind index,所以其查询的结果直接就是排序好的结果
说明2:为什么呢?因为这个时候 salary和age是一个联合索引,索引在文件中是一个带顺序的b+数结构,所以将这个字段建立一个联合索引,就意味着使用索引查询的时候,就已经是带着顺序的数据了,所以这个时候就不需要在将数据从新在排序了,这样的查询效率就会更高。
案例4: order by 中的字段顺序和索引顺序不一致的情况
mysql> explain select salary,age from emp order by age, salary; +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+-----------------------------+ | 1 | SIMPLE | emp | NULL | index | NULL | salary_age_idx | 10 | NULL | 7 | 100.00 | Using index; Using filesort | +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+-----------------------------+ 1 row in set, 1 warning (0.00 sec)
说明1:这个时候order by 是age在前,salary在后,和索引的顺序不一致,仍然会触发索引,使用Using index,但是也会使用Using filesort,所以推荐大家使用正确的索引顺序的字段来进行排序
案例5:对salary和age做降序查询
mysql> explain select salary,age from emp order by salary desc, age desc; +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+----------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+----------------------------------+ | 1 | SIMPLE | emp | NULL | index | NULL | salary_age_idx | 10 | NULL | 7 | 100.00 | Backward index scan; Using index | +----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+----------------------------------+ 1 row in set, 1 warning (0.00 sec)
mysql> explain select id,salary,age from emp order by salary desc;
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+----------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+----------------------------------+
| 1 | SIMPLE | emp | NULL | index | NULL | salary_age_idx | 10 | NULL | 7 | 100.00 | Backward index scan; Using index |
+----+-------------+-------+------------+-------+---------------+----------------+---------+------+------+----------+----------------------------------+
1 row in set, 1 warning (0.00 sec)
说明1:无论是对salary和age同时做降序还是对其中一个字段做降序排列,都会出现 Backward index scan; Using index,其中 Backward index scan 是反向扫描索引
说明2:这是因为索引中默认的顺序是升序的,而做降序排列,就需要反向扫描索引了
案例7:创建一个 salary 和 age 都是降序的索引
create index salary_age_desc_idx on emp(salary desc, age desc); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0
查询目前所有的索引
mysql> show index from emp; +-------+------------+---------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-------+------------+---------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | emp | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | YES | NULL | | emp | 1 | fk_dept | 1 | dept_id | A | 3 | NULL | NULL | YES | BTREE | | | YES | NULL | | emp | 1 | salary_age_desc_idx | 1 | salary | D | 7 | NULL | NULL | YES | BTREE | | | YES | NULL | | emp | 1 | salary_age_desc_idx | 2 | age | D | 7 | NULL | NULL | YES | BTREE | | | YES | NULL | | emp | 1 | salary_age_idx | 1 | salary | A | 7 | NULL | NULL | YES | BTREE | | | YES | NULL | | emp | 1 | salary_age_idx | 2 | age | A | 7 | NULL | NULL | YES | BTREE | | | YES | NULL | +-------+------------+---------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ 6 rows in set (0.01 sec)
说明1:这里 salary_age_desc_idx 就是根据 salary 和 age 做的降序索引,其Collation中的D即降序的意思
案例8:使用salary_age_desc_idx索引然后在使用order by降序查询
mysql> explain select salary,age from emp use index(salary_age_desc_idx) order by salary desc, age desc; +----+-------------+-------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+ | 1 | SIMPLE | emp | NULL | index | NULL | salary_age_desc_idx | 10 | NULL | 7 | 100.00 | Using index | +----+-------------+-------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.01 sec)
说明1:这个时候的Extra 中显示的 Using index,效率就会比较高了
说明2:这是因为salary_age_desc_idx索引的顺序就是降序排列的,所以使用该索引做降序排列的时候,就不需要在做反向扫描
说明3:在实际的业务中,我们可以根据自己的查询需要,创建升序或者降序的索引。
3.4 order by总结
-
- 根据排序字段建立合适的索引,多字段排序是,也遵循最左前缀法则
- 尽量使用覆盖索引
- 多字段排序,如果有升序有降序,此时需要注意联合索引在创建时的规则,也应该有对应的升序和降序
- 如果不可避免的出现filesort,大数据量排序的时候,可以适当增大排序缓冲区的大小,sort_buffer_size(默认256K)
四、group by优化
为了测试数据的准确性,这是我先把除了主键以外的索引都删除了,然后根据需要在重新创建
mysql> show index from emp; +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | emp | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | YES | NULL | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ 2 rows in set (0.01 sec)
案例1:根据job做聚合查询
mysql> select job, count(*) from emp group by job;; +--------------+----------+ | job | count(*) | +--------------+----------+ | 董事长 | 1 | | 项目经理 | 1 | | 开发 | 3 | | 财务 | 1 | | 出纳 | 1 | | 人事 | 1 | +--------------+----------+ 6 rows in set (0.00 sec)
我们使用explain查看一下执行计划
mysql> explain select job, count(*) from emp group by job; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+ | 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 7 | 100.00 | Using temporary | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+ 1 row in set, 1 warning (0.00 sec)
说明1:通过Extra字段:Using temporary,说明在这次的查询中创建了一张临时表,这是无论是空间上还是速度上都会影响到查询效率的。
这时我们给 job 创建一个索引,再次使用explain查看一下执行计划
mysql> create index job_idx on emp(job); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show index from emp; +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | emp | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | YES | NULL | | emp | 1 | job_idx | 1 | job | A | 6 | NULL | NULL | YES | BTREE | | | YES | NULL | +-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
mysql> explain select job, count(*) from emp group by job; +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ | 1 | SIMPLE | emp | NULL | index | job_idx | job_idx | 83 | NULL | 7 | 100.00 | Using index | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
说明2:这是查询中就使用到了索引查询,而没有建立临时表
这时我们在对 job 和 age 同时做分组查询
mysql> explain select job,age, count(*) from emp group by job,age; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+ | 1 | SIMPLE | emp | NULL | ALL | NULL | NULL | NULL | NULL | 7 | 100.00 | Using temporary | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-----------------+ 1 row in set, 1 warning (0.00 sec)
说明3:这时Extra字段的值,仍然是Using temporary,那是因为没有一个与之对应的联合索引。
我们继续创建一个 job 和 age 的联合索引,然后再看一下 explain 的执行计划
mysql> create index job_age_idx on emp(job,age); Query OK, 0 rows affected (0.05 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show index from emp; +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | emp | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | YES | NULL | | emp | 1 | job_idx | 1 | job | A | 6 | NULL | NULL | YES | BTREE | | | YES | NULL | | emp | 1 | job_age_idx | 1 | job | A | 6 | NULL | NULL | YES | BTREE | | | YES | NULL | | emp | 1 | job_age_idx | 2 | age | A | 6 | NULL | NULL | YES | BTREE | | | YES | NULL | +-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ 5 rows in set (0.00 sec)
mysql> select job,age,count(*) from emp group by job,age; +--------------+------+----------+ | job | age | count(*) | +--------------+------+----------+ | 人事 | 27 | 1 | | 出纳 | 25 | 1 | | 开发 | 22 | 2 | | 开发 | 24 | 1 | | 董事长 | 43 | 1 | | 财务 | 25 | 1 | | 项目经理 | 38 | 1 | +--------------+------+----------+ 7 rows in set (0.00 sec) mysql> explain select job,age,count(*) from emp group by job,age; +----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+ | 1 | SIMPLE | emp | NULL | index | job_age_idx | job_age_idx | 88 | NULL | 7 | 100.00 | Using index | +----+-------------+-------+------------+-------+---------------+-------------+---------+------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
说明4:当我们group by后面的分组字段,存在于某一个联合索引中的时候,group by会使用索引查询,而不会建立临时表
案例2:我们根据job做过滤然后再根据age排序
mysql> select job,age from emp where job="开发" group by age; +--------+------+ | job | age | +--------+------+ | 开发 | 22 | | 开发 | 24 | +--------+------+ 2 rows in set (0.01 sec) mysql> explain select job,age from emp where job="开发" group by age; +----+-------------+-------+------------+------+---------------------+-------------+---------+-------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------------+-------------+---------+-------+------+----------+-------------+ | 1 | SIMPLE | emp | NULL | ref | job_idx,job_age_idx | job_age_idx | 83 | const | 3 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------------+-------------+---------+-------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
说明1:当where后面的条件和group by 后面的条件一起组合成连锁索引,也不会建立临时表,也会直接走连个查询索引的。效率同样比较高
总结:
-
- 在分组操作时,可以通过索引来提高效率
- 分组操作时,索引的使用也满足最左前缀法则
五、limit优化
account_transaction表数据量展示
mysql> select count(*) from account_transaction; +----------+ | count(*) | +----------+ | 2261942 | +----------+ 1 row in set (8.40 sec)
说明1:account_transaction总数据量有226万+
案例1:分别采用分页查询,第一页,第1万页,200万页的数据
mysql> select * from account_transaction limit 1,2; +----+--------------------+--------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ | id | trade_no | type | method | time | payment | out_trade_no | amount | balance | trader_staff_id | operator_staff_id | device_id | remark | +----+--------------------+--------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ | 2 | 156384294742000250 | TOP_UP | CASH | 2019-07-23 00:49:07.072256 | LOCAL_ACCOUNT | | 10000 | 10000 | 250 | 12 | 6 | | | 3 | 156384301875000251 | TOP_UP | CASH | 2019-07-23 00:50:18.059192 | LOCAL_ACCOUNT | | 10000 | 10000 | 251 | 12 | 6 | | +----+--------------------+--------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ 2 rows in set (0.00 sec) mysql> select * from account_transaction limit 10000,2; +-------+--------------------+---------------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ | id | trade_no | type | method | time | payment | out_trade_no | amount | balance | trader_staff_id | operator_staff_id | device_id | remark | +-------+--------------------+---------------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ | 10054 | 156506391300003827 | CONSUME_LUNCH | | 2019-08-06 03:58:33.000000 | LOCAL_ACCOUNT | | 200 | 9800 | 3827 | 0 | 27 | | | 10055 | 156506391300002816 | CONSUME_LUNCH | | 2019-08-06 03:58:33.000000 | LOCAL_ACCOUNT | | 200 | 9800 | 2816 | 0 | 19 | | +-------+--------------------+---------------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ 2 rows in set (0.02 sec) mysql> select * from account_transaction limit 2000000,2; +---------+--------------------+---------------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ | id | trade_no | type | method | time | payment | out_trade_no | amount | balance | trader_staff_id | operator_staff_id | device_id | remark | +---------+--------------------+---------------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ | 5524352 | 163539315991003043 | CONSUME_LUNCH | | 2021-10-28 03:52:39.000000 | LOCAL_ACCOUNT | | 200 | 3800 | 3043 | 0 | 34 | | | 5524354 | 163539342290003077 | CONSUME_LUNCH | | 2021-10-28 03:57:02.000000 | LOCAL_ACCOUNT | | 200 | 1500 | 3077 | 0 | 19 | | +---------+--------------------+---------------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ 2 rows in set (2.51 sec)
说明1:我们对1页,1万页,200万页的数据分别查询,发现随着查询数据量的增加,查询的时间也在增加
说明2:当我们查询limit 2000000,2时,此时需要Mysql排序钱2000002条记录,但是仅仅需要返回200001-20002的记录,前2000000条记录丢弃,查询排序的代价非常大
查询优化
mysql> select a.* from account_transaction as a, (select id from account_transaction order by id limit 2000000,2) as at where a.id = at.id; +---------+--------------------+---------------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ | id | trade_no | type | method | time | payment | out_trade_no | amount | balance | trader_staff_id | operator_staff_id | device_id | remark | +---------+--------------------+---------------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ | 5524352 | 163539315991003043 | CONSUME_LUNCH | | 2021-10-28 03:52:39.000000 | LOCAL_ACCOUNT | | 200 | 3800 | 3043 | 0 | 34 | | | 5524354 | 163539342290003077 | CONSUME_LUNCH | | 2021-10-28 03:57:02.000000 | LOCAL_ACCOUNT | | 200 | 1500 | 3077 | 0 | 19 | | +---------+--------------------+---------------+--------+----------------------------+---------------+--------------+--------+---------+-----------------+-------------------+-----------+--------+ 2 rows in set (0.51 sec)
说明3:同样是分页查询2000000页以后的数据,该查询仅好事0.51秒,比直接使用limit分页查询快了几倍
说明4:Mysql官方针对大数据量的分页查询给出的方案是,建议使用覆盖查询加子查询形式进行优化
说明5:该插叙的子查询:select id from account_transaction order by id limit 2000000,2,首先这是根据id查询到需要数据的id,本身根据id查找就是比较快的。
mysql> select id from account_transaction order by id limit 2000000,2; +---------+ | id | +---------+ | 5524352 | | 5524354 | +---------+ 2 rows in set (0.45 sec)
说明6:将该子查询的结果当做一张表,与account_trasaction做子查询,这样效率就会比直接使用limit速度快很多。
六、count优化
6.1 count() 原理
是一个聚合函数,对于返回的结果集,一行一行的判断,如果count函数的参数不为NULL,累计值就+1,否则不加1,最后返回累计值
6.2 count的几种用法
count(*):
InnoDB引擎并不会把全部的字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加,mysql 对count(*)做了优化。
count(主键)
InnoDB引擎会遍历整张表,把每一行的主键id值都取出来,返回给服务层,服务层那个主键后,直接按行进行累加(主键不可能为空)
count(普通字段):
没有not null 约束:InnoDB引擎会遍历整张表,把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数+1.
有not null 约束:InnofDB引擎会遍历整张表,把每一行的字段值都取出来,返回给服务层,直接按行累加
count(1)
InnoDB引擎遍历整张表,但不取值,服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。
6.3 效率排序
count(*) ≈count(1)>count(id)>count(普通字段)
七、update优化
7.1 案例1:根据索引修改数据,仅仅会触发行锁

说明1:因为左边和右边都是根据id修改的不同数据,这时id是主键索引,所以这里的修改都只会触发行锁,不会影响其他行的修改。
7.2 案例2:根据非索引字段同时修改记录数据

说明1:update的时候,如果条件是索引字段,则只会触发行索引
说明2:updae的时候,如果条件是非索引字段,则会触发表索引,即在update的时候,整张表处于锁住的状态。
说明3:主需要对update的字段创建一个索引值,就可以在update的时候将表锁降低为行锁。
7.3 总结:
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁。文章来源:https://www.toymoban.com/news/detail-616244.html
到了这里,关于Mysql高级5-SQL优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!