一、说明
语音识别是一种技术,通过计算机和软件系统,将人们的口头语言转换为计算机可读的文本或命令。它使用语音信号处理算法来识别和理解人类语言,并将其转换为计算机可处理的格式。语音识别技术被广泛应用于许多领域,如语音助手、语音控制、语音翻译、语音搜索、电话自动接听等。
二、基本问题提出
回到语音识别,我们的目标是根据声学和语言模型找到与音频对应的最佳单词序列。

为了创建声学模型,我们的观察X由一系列声学特征向量(x₁,x₂,x₃,...)表示。在上一篇文章中,我们了解了人们如何表达和感知语音。在本文中,我们将讨论如何从我们学到的内容中提取音频特征。
三、语音识别要求
让我们首先定义 ASR(自动语音识别器)中特征提取的一些要求。给定一个音频片段,我们使用 25ms 宽的滑动窗口来提取音频特征。

这个 25 毫秒的宽度足以让我们捕获足够的信息,但这个框架内的特征应该保持相对静止。如果我们用 3 部手机每秒说 4 个单词,并且每个电话将细分为 3 个阶段,那么每秒有 36 个状态或每个状态 28 毫秒。所以 25ms 窗口大约是正确的。

源
语境在言语中非常重要。发音根据电话前后的发音而变化。每个滑动窗口相距约10毫秒,因此我们可以捕获帧之间的动态以捕获适当的上下文。
音高因人而异。然而,这对识别他/她说的话几乎没有作用。F0 与音高有关。它在语音识别中没有价值,应将其删除。更重要的是共振峰F1,F2,F3,...对于那些在遵循这些条款方面有问题的人,我们建议您先阅读上一篇文章。
我们还希望提取的特征能够对扬声器是谁以及环境中的噪音具有鲁棒性。此外,像任何 ML 问题一样,我们希望提取的特征独立于其他特征。开发模型和使用独立特征训练这些模型更容易。
一种流行的音频特征提取方法是梅尔频率倒谱系数 (MFCC),它具有 39 个特征。特征计数足够小,足以迫使我们学习音频信息。12个参数与频率幅度有关。它为我们提供了足够的频率通道来分析音频。
下面是提取 MFCC 特征的流程。

主要目标是:
- 删除声带激励 (F0) — 音高信息。
- 使提取的特征独立。
- 适应人类感知声音响度和频率的方式。
- 捕获手机的动态(上下文)。
四、梅尔频率倒谱系数
让我们一次介绍一个步骤。
模数转换
A/D 转换对音频剪辑进行采样并对内容进行数字化,即将模拟信号转换为离散空间。通常使用8或16 kHz的采样频率。

源
预加重
预加重可提高高频中的能量。对于元音等浊音段,较低频率的能量高于较高频率。这称为频谱倾斜,与声门源(声带如何产生声音)有关。提高高频能量使更高共振峰中的信息更容易被声学模型获得。这提高了手机检测的准确性。对于人类来说,当我们听不到这些高频声音时,我们开始出现听力问题。此外,噪声具有很高的频率。在工程领域,我们使用预加重使系统不易受到以后过程中引入的噪声的影响。对于某些应用程序,我们只需要在最后撤消提升即可。
预加重使用滤波器来提升更高的频率。以下是关于如何增强高频信号的前后信号。

朱拉夫斯基和马丁,图。9.9
窗口
窗口化涉及将音频波形切成滑动帧。

但我们不能只是在框架的边缘把它砍掉。突然下降的振幅会产生很多噪声,这些噪声出现在高频中。要对音频进行切片,振幅应在帧边缘附近逐渐下降。

假设 w 是应用于时域中原始音频剪辑的窗口。

w的一些替代方案是汉明窗和汉宁窗。下图显示了如何使用这些窗口斩断正弦波形。如图所示,对于汉明和汉宁窗口,振幅在边缘附近下降。(汉明窗的边缘有轻微的突然下降,而汉宁窗则没有。

w 的相应方程为:

右上方是时域中的声波。它主要仅由两个频率组成。如图所示,与矩形窗口相比,汉明和汉宁的斩波框架可以更好地保持原始频率信息,噪声更少。

源右上:由两个频率组成的信号
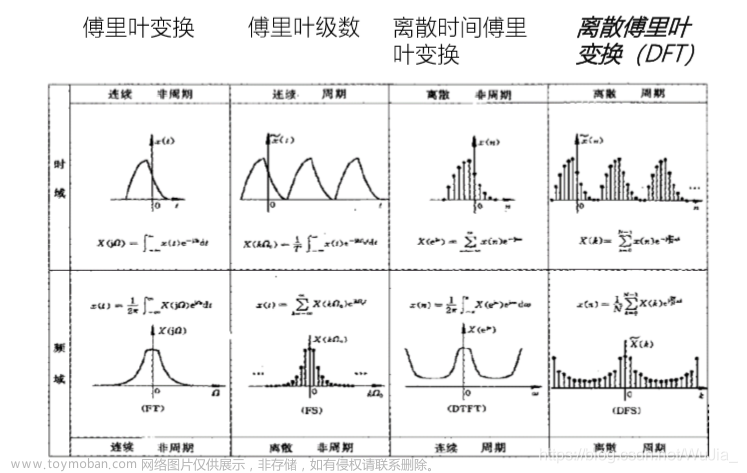
离散傅里叶变换 (DFT)
接下来,我们应用DFT提取频域中的信息。

梅尔过滤器组
如上一篇文章所述,设备测量与我们的听觉感知不同。对于人类来说,感知的响度会根据频率而变化。此外,感知频率分辨率随着频率的增加而降低。即人类对更高的频率不太敏感。左图显示了 Mel 刻度如何将测量的频率映射到我们在频率分辨率背景下感知的频率。

源
所有这些映射都是非线性的。在特征提取中,我们应用三角带通滤波器来隐藏频率信息以模仿人类的感知。

源
首先,我们对DFT的输出进行平方。这反映了每个频率(x[k]²)的语音功率,我们称之为DFT功率谱。我们应用这些三角形梅尔尺度滤波器组将其转换为梅尔尺度功率谱。每个梅尔级功率谱槽的输出表示其覆盖的多个频段的能量。此映射称为梅尔分箱。插槽 m 的精确方程为:

Trainang角带通在较高频率下较宽,以反映人类的听力,而在高频下灵敏度较低。具体来说,它在 1000 Hz 以下线性间隔,然后以对数方式转动。
所有这些努力都试图模仿我们耳朵中的基底膜如何感知声音的振动。出生时,基底膜在耳蜗内有大约15,000根毛发。下图显示了这些毛发的频率响应。因此,下面的曲线形状响应只是由 Mel 滤波器组中的三角形近似。

我们模仿我们的耳朵如何通过这些头发感知声音。简而言之,它由使用 Mel 过滤组的三角形滤波器建模。

源
日志
梅尔滤波器组输出功率谱。人类对高能量下的微小能量变化不如低能量水平下的微小变化敏感。事实上,它是对数的。因此,我们的下一步将从 Mel 过滤器组的输出中删除日志。这也减少了对语音识别不重要的声学变体。接下来,我们需要解决另外两个要求。首先,我们需要删除 F0 信息(音高),并使提取的特征独立于其他特征。
倒谱 — IDFT
下面是语音产生的模型。

源
我们的发音控制声道的形状。源过滤器模型将声带产生的振动与我们的发音产生的过滤器相结合。声门源波形将通过声道的形状在不同频率下被抑制或放大。
Cepstrum 是单词“spectrum”中前 4 个字母的反面。我们的下一步是计算分离声门源和过滤器的倒谱。图(a)是光谱,其中y轴是幅度。图(b)取了量级的对数。仔细观察,波浪在 8 到 1000 之间波动约 2000 次。实际上,每 8 个单位波动约 1000 次。这大约是125赫兹 - 声带的源振动。

保罗·泰勒〔2008〕
如观察所示,对数频谱(下面的第一张图)由与电话(第二张图)和音高(第三张图)相关的信息组成。第二个图中的峰值标识区分电话的共振峰。但是我们如何将它们分开呢?

源
回想一下,时域或频域中的周期在变换后是反转的。

回想一下,音高信息在频域中的周期很短。我们可以应用傅里叶逆变换将螺距信息与共振峰分离。如下图所示,音高信息将显示在中间和右侧。中间的峰值实际上对应于F0,手机相关信息将位于最左侧。

这是另一个可视化效果。左图上的实线是频域中的信号。它由虚线绘制的电话信息和音高信息组成。在IDFT(逆离散傅里叶变换)之后,具有1/T周期的音高信息被转换为右侧T附近的峰值。

源
因此,对于语音识别,我们只需要最左侧的系数并丢弃其他系数。事实上,MFCC 只取前 12 个倒谱值。还有另一个与这 12 个系数相关的重要属性。对数功率谱是真实且对称的。它的反DFT等效于离散余弦变换(DCT)。

DCT 是一种正交变换。在数学上,变换会产生不相关的特征。因此,MFCC 功能高度不相关。在 ML 中,这使我们的模型更容易建模和训练。如果我们使用多元高斯分布对这些参数进行建模,则协方差矩阵中的所有非对角线值都将为零。在数学上,此阶段的输出为

以下是倒谱 12 个倒谱系数的可视化。

源
动态要素(增量)
MFCC 有 39 个功能。我们最终确定了 12 个,其余的是什么。第 13 个参数是每帧中的能量。它可以帮助我们识别手机。

在发音中,上下文和动态信息很重要。止动闭合和释放等衔接可以通过共振峰过渡来识别。表征随时间变化的功能可提供电话的上下文信息。另外 13 个值计算下面的增量值 d(t)。它测量从上一帧到下一帧的特征变化。这是特征的一阶导数。

最后 13 个参数是 d(t) 从最后一帧到下一帧的动态变化。它充当 c(t) 的二阶导数。
因此,39 个 MFCC 特征参数是 12 个倒谱系数加上能量项。然后我们还有 2 个对应于增量和双精度增量值的集合。

倒谱均值和方差归一化
接下来,我们可以执行特征规范化。我们用其均值归一化特征,并将其除以其方差。均值和方差是使用单个语句中所有帧的特征值 j 计算的。这使我们能够调整值以对抗每个记录中的变体。

但是,如果音频剪辑很短,这可能不可靠。相反,我们可以根据说话人甚至整个训练数据集计算平均值和方差值。这种类型的功能规范化将有效地取消前面所做的预加重。这就是我们提取MFCC特征的方式。最后要注意的是,MFCC对噪声的抵抗力不是很强。
五、感知线性预测 (PLP)
PLP与MFCC非常相似。受听觉感知的激励,它使用相等响度预加重和立方根压缩而不是对数压缩。

源
它还使用线性回归来最终确定倒谱系数。PLP具有稍好的精度和稍好的噪声鲁棒性。但也有人认为MFCC是一个安全的选择。在本系列中,当我们说提取 MFCC 特征时,我们也可以提取 PLP 特征。
六、后记
ML 为问题域构建模型。对于复杂的问题,这是非常困难的,并且该方法通常非常启发式。有时,人们认为我们正在入侵系统。本文中的特征提取方法在很大程度上依赖于实证结果和观察结果。随着深度学习的引入,我们可以用更少的黑客攻击来训练复杂的模型。但是,某些概念对于 DL 语音识别仍然有效且重要。文章来源:https://www.toymoban.com/news/detail-616686.html
下一个:为了更深入地了解语音识别,我们需要详细研究两种 ML 算法。文章来源地址https://www.toymoban.com/news/detail-616686.html
到了这里,关于语音识别 — 特征提取 MFCC 和 PLP的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!