链表
补充知识
typedef
给类型换名字,比如
typedef struct Student
{
int sid;
char name[100];
char sex;
}ST;//ST就代表了struct Student
//即这上方一大坨都可以用ST表示
//原先结构体定义对象是通过下面这种方式实现的
struct Student st;
//现在使用typedef后,即可用下方方式定义
ST st;
或者来一个结构体指针定义。
typedef struct Student
{
int sid;
char name[100];
char sex;
}*PST;
//这样PST等价于struct Student *
//这样初始化后就可以直接初始化一个结构体指针
PST ps = &st;
//之后ps进行指针的调用就行,例如下所示
ps->sid = 99;
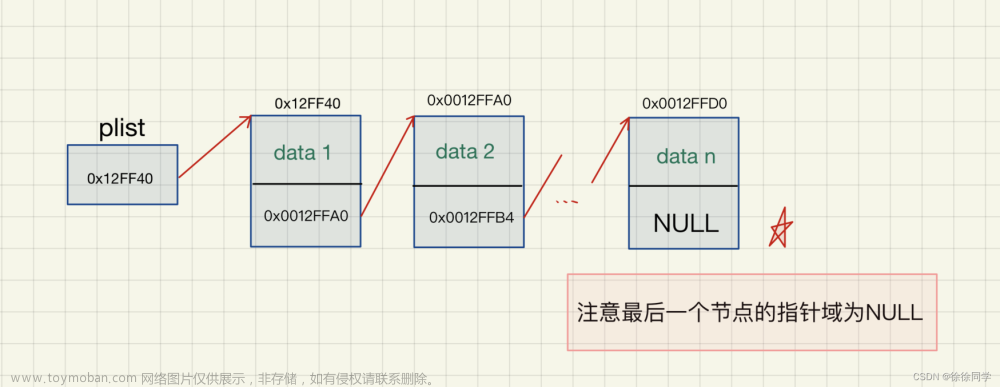
离散存储
离散的含义,任何一个点到其他点之间是有间距的。
定义
n个节点离散分配,彼此通过指针相连接,每个节点只有一个前驱节点,每个节点只有一个后继节点,首节点没有前驱节点,尾节点没有后继节点。
专业术语
- 首节点:第一个有效的节点。
- 尾节点:最后一个有效节点。
- 头结点:在首节点的前面加上这个结点,即第一个有效节点前的节点叫做头结点。头结点里面没有存放有效数据,也没有存放链表有效节点的个数,其真正含义是可以方便我们对链表进行操作(增删改查)。
- 头指针:指向头结点的指针变量(存放了头结点的地址)。
- 尾指针:指向尾节点的指针变量。
确定一个链表需要几个参数?
首节点可以通过头结点推出来,所以不是必须的,尾指针是0,因为没有后继节点,所以尾指针也不是必须的。尾节点也不是必须的,找到最后空的就知道尾节点,所以也不是必须的。头指针包含了指向头结点的地址,所以头结点也不是必须的,记下头指针就行。首节点可以由头结点推出来,所以首节点也不是必须的。所以综上,只要知道头结点的地址,就可以把整个链表的所有信息都找到。所以说确定一个链表只需要一个参数,即为头指针。
头结点的数据类型和首节点的数据类型是一样的。
代码
通过代码来模拟链表。
每一个节点的数据类型都是一模一样的,一个节点可以分成两部分,一部分是存放有效的数据,另有一部分是存放指针,指向后面的一个节点。这样就造成了每一个节点的数据类型是一样的。这里面的指针指向的是第二个节点的整体。
所以现在是包含了一个数据域一个指针域,
typedef struct Node{
int data;//数据域
struct Node *pNext;//指针域
//这里的指针域指向的是与其数据类型一致,但是另外一个节点。(下一节点的地址)(本节点的指针指向了下一节点)
}NODE, *PNODE;
//NODE是struct Node类型,*PNODE是struct Node *类型,记住struct Node是包含了整个整体的,要带上花括号{},即struct Node{}
链表分类
- 单向链表
- 双向链表:这下相比单链表,每个节点分成了三个部分,分别有指向自己的前驱和后继的指针,以及存放有效值。
- 循环链表:能通过任何一个节点找到其他所有的节点,就是首尾节点连接了。
- 非循环链表
常见算法
- 遍历
- 查找
- 清空
- 销毁
- 求长度
- 排序
- 删除节点
- 插入节点
狭义的算法是与数据的存储方式密切相关的,广义的算法是与数据的存储方式无关。泛型是利用某种技术达到的效果就是,不同的存存储方式,执行的操作时是一样的。(泛型是一种假象)
插入节点伪代码:
r = p->next;
p->next = q;
q->next = r;
//
q->next = p->next;
p->next = q;
//以上两种方法都能实现q节点插入到p和p.next中间
删除节点的伪代码:
r = p->next;
p->next = p-next->next;
free(r);
//C当中不会自动释放内存,所以得手动释放内存,free
//C++当中是delete
链表创建和常用算法
#include <iostream>
#include <cmalloc>
using namespace std;
typedef struct Node{
int data;//数据域
struct Node *pNext;//指针域
}Node, *PNODE;
//现在就是定义了这么一个数据类型,叫做struct Node。
//函数声明
PNODE create_list(void);
void traverse_list(PNODE pHead);//遍历
bool is_empty(PNODE pHead);//判断是否为空,就看pHead->pNext == nullptr的结果
int length_list(PNODE);//链表长度
bool insert_list(PNODE, int, int);
bool delete_list(PNODE, int, int*);
//可以把删除的结点放到第三个参数当中去,也就是delete删除的元素可以暂存到第三个参数当中去。delete_list(pHead, 3, &val);
void sort_list(PNODE);//排序
int main(void){
PNODE pHead = nullptr;
//等价于struct Node *pHead = nullptr;
pHead = create_list();
//create_list()函数的功能就是创建一个非循环单向链表,然后把单向链表的首地址赋给pHead。
//创建一个非循环单向链表,并将该链表的头结点地址,赋给pHead。
sort_list(pHead);
traverse_list(pHead);
//insert_list(pHead, 4, 33);
int len = length_list(pHead);
cout << "链表长度是: " << endl;
//这是代表遍历的意思,之前也说了,推出链表的所有参数只需要一个头结点指针(头指针)就行。
if (is_empty(pHead))
cout << "链表为空" << "\n" << endl;
else
cout << "链表非空" << "\n" << endl;
return 0;
}
//因为动态内存管理,在一个函数当中申请的内存可以在另外一个函数当中调用。
//创建函数
PNODE create_list(void)//最后只要分配好的内存地址就行
{
int len;//存放有效节点的个数
int val;//临时存放用户输入的结点的值
//分配了一个不存放数据的头结点
PNODE pHead = (PNODE)malloc(sizeof(NODE));
if (pHead == nullptr)
{
cout << "分配失败,程序终止" << endl;
return -1;
}
PNODE pTail = pHead;
pTail->pNext = nullptr;//这样永远指向尾节点
cout << "请输入您需要生产的链表节点的个数:len = " << endl;
cin >> len;
for(int i = 0; i < len; ++i)
{
cout << "请输入第 " << i+1 << " 个节点的值: " << endl;//i+1是因为链表从1开始的,这里的i是从0开始的
cin >> val;
//每循环一次,就用pNew造出一个新的节点
PNODE pNew = (PNODE)malloc(sizeof(NODE));//临时节点
if (pNew == nullptr)
{
cout << "分配失败,程序终止" << endl;
return -1;
}
//总而言之就是利用pHead生成一个临时节点,然后把数值放到临时节点的数据域当中去,再把临时节点挂到之前一个节点的后面,最后再把临时节点清空。但是这样有问题,每次新生成的结点都会挂到之前一个节点的后面,造成“一对多”的现象,所以解决方法就是,每次新生成的结点都要挂到整个链表的尾节点的后面。所以定义一个pTail永远指向尾节点。
pNew->data = val;
pTail->pNext = pNew;
pNew->pNext = nullptr;
pTail = pNew;
}
return pHead;//返回头结点地址
}
//遍历函数
//主要思路,先定义一个指针p,指向第一个有效的结点,如果此时指向的结点不为空,就把数据域给输出就行,再往后移一个。
void travese_list(PNODE pHead)
{
PNONDE p = pHead->pNext;
while(p != nullptr)
{
cout << p_data << endl;
p = p->pNext;//一定要往后移,往后移才能指向下一个
}
cout << "\n" << "输出完毕" << endl;
return;
}
//判断是否为空的函数
bool is_empty(PNODE pHead)
{
if(pHead->pNext == nullptr)
return true;
else
return false;
}
//长度函数
int length_list(PNODE pHead)
{
PNODE p = pHead->pNext;
int cnt = 0;
while(p->pNext != nullptr)
{
++cnt;
p = p->pNext;
}
return cnt;
}
//排序函数
//依次把数每次和后面的数进行比较,这下就是升序排序的
void sort_list(PNODE pHead)
{
int i, j, t;
int len = length_list(pHead);
PNODE p, q;
for (i = 0 ,p = pHead->pNext; i<len-1; ++i, p = p->pNext)
{
for (j = j+1, q = p->pNext; j<len; ++j, q = q->pNext)
{
if (p->data > q->data) //类似于数组中的a[i]>a[j]
{
t = p->data;//t = a[i];
p->data = q->data;//a[i] = a[j];
q->data = t;//a[j] = t;
}
}
}
return;
}
//听完郝老师讲的这里,我才真正知道在C++当中函数重载的具体意思,operator之类的醍醐灌顶。
//插入函数
//在pHead所指向的链表的第pos个节点的前面插入一个新的节点,该节点的值是val,并且pos的值是从1开始。记住pos不包含头结点,而是从首节点(有效节点)开始。
bool insert_list(PNODE pHead, int pos, int val)
{
int i = 0;
PNODE p = pHead;
while(p != nullptr && i < pos-1)
//这里的p是代表不是最后一个,i<pos-1表示找到插入位置之前的结点。
//while函数的作用是将p移动到pos-1的位置,画图就好理解。
{
p = p->pNext;
++i;
}
if (i > pos-1 || p == nullptr)
//这里的if是判断要插入的位置是否超出了链表多一个位置
//i>pos-1是判断pos是否为小于1的数,若是则直接false
//p = nullptr是为了处理插入的位置,例如有5个节点,现在在第7个节点位置插入。因为这是接着while循环的,所以多一层if判断经过while循环后的p的变化,同时还能判断是否为空链表的存在。
return false;
PNODE pNew = (PNODE)malloc(sizeof(NODE));
if (pNew == nullptr)
{
cout << "动态内存分配失败" << "\n" << endl;
return -1;
}
//以上pos等于1的时候,不执行前面两个表达式,即while和if,直接执行后面的,此时将新元素插入到头结点和第一个有效节点之间。
pNew->data = val;
PNODE q = p->pNext;
p->pNext = pNew;
pNew->pNext = q;
return true;
}
//删除函数
bool delete_list(PNODE p, int pos, int*pVal)
{
int i = 0;
PNODE p = pHead;
while(p->pNext != nullptr && i < pos-1)
{
p = p->pNext;
++i;
}
if (i > pos-1 || p->pNext == nullptr)
return false;
PNODE q = p->pNext;
*pVal = q->data;
//删除p节点后面的结点
p->pNext = p->pNext->pNext;
free(q);
q = nullptr;
return true;
}
链表总结
狭义的讲:数据结构是专门研究数据存储的问题,数据的存储包含两方面,个体的存储,以及个体关系的存储。算法是对存储数据的操作。
广义的讲:数据结构既包含数据的存储也包含数据的操作,对存储数据的操作就是算法。
算法:
狭义的讲:算法是和数据的存储方式密切相关。
广义的讲:算法和数据的存储方式无关。
这就是泛型的思想。
数据的存储结构有几种:
线性:连续存储【数组】,离散存储【链表】,线性结构的应用—栈,队列。
链表的优缺点:文章来源:https://www.toymoban.com/news/detail-616747.html
- 插入和删除快
- 存取元素速度慢
- 存储容量无限
数组的优缺点:文章来源地址https://www.toymoban.com/news/detail-616747.html
- 存取速度很快
- 但事先必须知道数组的长度
- 插入删除元素很慢
- 空间通常是有限制的
- 需要大块连续的内存块
到了这里,关于Linked List的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!