学习Kafka对于现代数据处理和分析至关重要。它能够帮助我们处理海量数据流,确保数据的可靠性,支持实时流处理,并且具有广泛的应用场景。通过掌握Kafka的知识和技能,我们可以在数据驱动的世界中更好地应对挑战,取得更大的成功。
kafka的优势
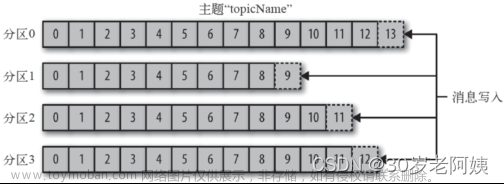
处理海量数据流:在当今数字化时代,数据量呈指数级增长。Kafka作为一种高性能的消息队列系统,可以处理海量数据流,并将其分发给多个消费者进行处理。学习Kafka可以让我们掌握处理大规模数据的能力,从而更好地应对数据爆炸式增长的挑战。
可靠性与容错性:Kafka具有高度可靠性和容错性。它能够确保数据不会丢失,并且能够在数据出现故障时进行自我修复。这使得Kafka成为处理重要数据的理想选择。学习Kafka可以让我们了解如何构建可靠的数据流管道,确保数据的安全性和完整性。
实时流处理:Kafka支持实时流处理,能够以毫秒级的延迟处理数据。这对于需要实时响应和即时决策的应用场景非常重要。通过学习Kafka,我们可以了解如何构建实时流处理系统,从而实现快速而准确的数据分析和决策。
应用广泛:Kafka被广泛应用于各种场景,包括日志收集、事件驱动架构、消息队列、数据集成等。学习Kafka可以让我们了解这些应用场景,并学会如何使用Kafka来解决实际问题。这将为我们提供更多的职业机会和发展空间。
课程目录
值得注意的是,我们在B站上发布了最新的kafka教程,5天的课程,从基础到实用,以下是完整的课程目录:
day1
01-课前回顾和今日内容
02-kafka的安装操作
03-kafka的安装操作_易错点说明
04-Kafka的安装操作_一键化脚本的配置和使用
05-Kafka的相关使用_shell操作命令的使用(上)
06-Kafka的相关使用_shell操作命令的使用(下)
07-上午内容的总结
08-Kafka的相关使用_基准测试操作
09-Kafka的相关使用_kafka的小工具使用
10-kafka的相关使用_kafka的生产者代码实现
11-Kafka的相关使用_kafka的消费者使用操作
12-Kafka的核心原理_分片和副本机制
13-回顾了HDFS的写入的流程
14-今日总结
day 2
01-课前回顾和今日内容
02-如何保证消息数据不丢失_生产者如何保证(上)
03-如何保证消息数据不丢失_生产者如何保证(中)
04-如何保证消息数据不丢失_生产者如何保证(下)
05-如何保证消息数据不丢失_模拟同步和异步发送
06-如何保证消息数据不丢失_broker端如何保证
07-上午内容的总结
08-如何保证消息数据不丢失_消费端如何保证
09-如何保证消息数据不丢失_消费端模拟自动提交和手动提交偏移量
10-kafka的消息存储机制(上)
11-kafka的消息存储机制(下)
12-kafka的消息查询机制
13-kafka的生产者的分发策略(概念描述)
14-kafka的生产者的数据分发策略(演示操作)
15-kafka的生产者的数据分发策略(轮询和粘性)
16-Kafka的消费者的负载均衡的机制
day 3
01-课前回顾和今日内容
02-Kafka-eagle的安装与启动操作
03-Kafka-eagle的简单介绍使用操作
04-Kafka数据积压的问题如何发现以及如何解决
05-Kafka的配额限速的机制
06-结构化流_什么是有界什么是无界
07-结构化流_基本介绍
08-结构化流的入门案例
09-上午内容的总结说明
10-结构化流的编程模型的基本介绍
11-结构化流的编程模型_source(File source)
12-结构化流的编程模型_source(rate source)
13-结构化流的编程模型_sink(输出模式介绍)
14-结构化流的编程模型_sink(输出模式 append)
15-结构化流的编程模型_sink(输出模式 compete)
16-结构化流的编程模型_sink(输出模式 update)
17-结构化流的编程模式_sink(输出 file sink)
18-今日总结
- day 4
01-课前回顾和今日内容
02-结构化流编程模型_触发器的使用操作
03-结构化流编程模型_sink输出_foreach
04-结构化编程模型_sink输出_foreachBatch
05-结构化编程模型_sink输出_memory sink
06-结构化编程模型_检查点的相关内容
07-消息的三种语义的介绍
08-上午内容的总结
09-Kafka和Spark的集成操作_jar包配置
10-Kafka和Spark的集成操作_source端集成
11-Kakfa和Spark集成_如何读取数据(流和批)
12-Kafka和Spark集群_如何写出数据到Kafka
13-综合案例_需求和数据说明
14-综合案例_需求实现_对接kafka
15-综合案例_需求实现_Json拉平实现
16-综合案例_需求实现
17-今日总结
- day 5
01-陌陌案例的需求说和数据模拟介绍
02-陌陌案例架构设置
03-Flume的基本介绍
04-Flume的安装操作
05-基于Flume完成陌陌案例消息数据采集工作
06-完成陌陌案例的数据统计分析操作
课程优势
通过学习这些应用场景,我们将会更好地理解Kafka在实际生产环境中的应用。
除了视频课程,课程还提供免费的课程资料和源码,帮助你更好的掌握Kafka框架的使用。
如果你想深入学习Kafka,并在实际生产环境中应用它,那么这门课程一定是你不容错过的!
课程将陆续上传,现在一键三连,开启你的Kafka学习之旅吧!扫码立即学习!文章来源:https://www.toymoban.com/news/detail-617154.html
https://www.bilibili.com/video/BV1U8411U7oK/?vd_source=704fe2a34559a0ef859c3225a1fb1b42&code=0719obGa1RtTFF0BDVIa1ZJFen19obGz&state=&wxfid=o7omF0RELrnx5_fUSp6D59_9ms3Y文章来源地址https://www.toymoban.com/news/detail-617154.html
到了这里,关于课程上新!5天学懂大数据框架Kafka的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!