Meta-Transformer是一个用于多模态学习的新框架,用来处理和关联来自多种模态的信息,如自然语言、图像、点云、音频、视频、时间序列和表格数据,虽然各种数据之间存在固有的差距,但是Meta-Transformer利用冻结编码器从共享标记空间的输入数据中提取高级语义特征,不需要配对的多模态训练数据。该框架由统一的数据标记器、模式共享编码器和用于各种下游任务的任务头组成。它是在不同模式下使用未配对数据执行统一学习的第一次努力。实验表明,它可以处理从基础感知到实际应用和数据挖掘的广泛任务。
Meta-Transformer

数据到序列的令牌标记

研究人员提出了一种元标记化方案,将来自不同模式(如文本、图像、点云和音频)的数据转换为共享空间中的标记嵌入。
对于自然语言,他们使用了带有30000个标记词汇表的WordPiece 嵌入,它将单词分割成子单词,并将每个输入文本转换成一组标记嵌入。
对于图像,他们将图像重塑为一系列平坦的2D补丁,然后利用投影层投影嵌入维度。该操作也可用于红外图像,而线性投影用于高光谱图像。他们用3D卷积代替2D卷积层用于视频识别。
对于点云,采用最远点采样(FPS)操作将原始点云从原始输入空间转换为标记嵌入空间,以固定采样比对原始点云的代表性骨架进行采样。然后,使用k -最近邻(KNN)对相邻点进行分组,并构建邻接矩阵来捕获3D物体和场景的结构信息。
对于音频频谱图,使用Mel滤波器组和Hamming窗口对音频波形进行预处理,以将波分割成间隔。然后将频谱图从时间和频率维度分割成补丁,然后将其平面化为标记序列。
统一的编码器
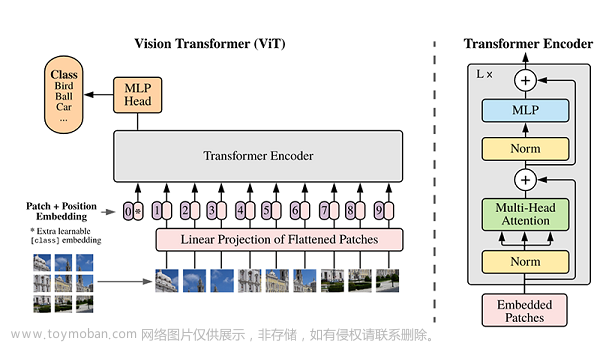
在将原始输入从各种模式转换为标记(令牌)嵌入后,研究人员使用了一个统一的Transformer 编码器,其中包含了固定的参数来编码这些令牌。基于ViT模型的编码器在LAION-2B数据集上进行对比学习预训练,提高编码器的通用标记编码能力。对于文本理解,他们使用来自CLIP的预训练文本标记器将句子转换为子词,然后转换为词嵌入。
论文中作者提到的“模态不可知学习”,一个可学习的标记(xCLS)被添加到标记嵌入序列的开始。该令牌的最终隐藏状态充当输入序列的摘要表示,通常用于识别任务。位置嵌入也会被添加到标记嵌入中。
Transformer 编码器由多个堆叠的多头自关注层和MLP块组成,对这些嵌入序列进行处理。作者指出,添加更复杂的2d感知位置嵌入并不能显著提高图像识别性能。
实验结果





Meta-Transformer模型在各种语言和图像理解任务中虽然并不总是优于其他先进的方法,但也表现出了很好的效果。
在GLUE基准测试的文本理解任务中,Meta-Transformer在情感、释义、复制、推理和回答任务方面得分相对较高。虽然它的表现不如BERT、RoBERTa和ChatGPT等模型,但它在理解自然语言方面表现出了新的希望,尤其是在微调之后。
在图像理解任务上,Meta-Transformer在几个方面优于Swin Transformer系列和interimage等模型。当与CLIP文本编码器相结合时,它在零样本分类方面提供了强有力的结果。它在目标检测和语义分割任务上也优于其他模型,显示了它在图像理解方面的熟练程度。
Meta-Transformer在处理红外和高光谱图像识别任务方面也被证明是有效的,分别在RegDB和Indian Pine数据集上进行了测试。尽管Meta-Transformer没有登顶排行榜,但其结果也很不错,展示了处理与红外图像和高光谱图像相关的挑战的潜力。
在x射线图像处理方面,Meta-Transformer取得了94.1%的性能,表明其在医学图像分析方面的实用性。





在点云理解任务中,Meta-Transformer在ModelNet-40、S3DIS和ShapeNetPart数据集上与其他模型相比,它在可训练参数较少的情况下获得了较高的准确率分数,强调了它在这一领域的效率。
在音频识别任务中,Meta-Transformer具有与AST和SSAST等现有音频Transformer模型竞争的优势,在调整参数时达到97.0%的高精度。尽管AST的性能很好,但像AST这样的模型具有更多可训练的参数。
在视频理解任务中,正如在UCF101数据集上测试的那样,Meta-Transformer在准确性方面并不优于其他最先进的方法。但是它的突出之处在于其明显较少的可训练参数,这表明了统一的多模式学习和较低的体系结构复杂性的潜在好处。
在时间序列预测任务中,Meta-Transformer在ETTh1、Traffic、Weather和Exchange数据集等基准测试上优于几种现有方法,同时只需要很少的可训练参数。
在表格数据理解任务中,Meta-Transformer在成人普查和银行营销数据集上表现出色。它在银行营销数据集上的表现优于其他模型,这表明它在理解复杂数据集方面具有潜力。
在PCQM4M-LSC数据集的图理解任务中,当前的Meta-Transformer架构在结构数据学习方面表现并不好,graphhormer模型的表现优于它,这方面还要改进。
在Ego4D数据集的分类任务中,Meta-Transformer的准确率达到73.9%。总的来说,这些发现突出了Meta-Transformer在不同领域的多功能性和有效性。
上面有几个结果都表明Meta-Transformer的参数少,模型效率更高,它的其中一个主要的限制是计算复杂度为O(n²x D)。
作者:Andrew Lukyanenko
最后论文地址和源代码:文章来源:https://www.toymoban.com/news/detail-617187.html
https://avoid.overfit.cn/post/27688397b91a48f680d3e5e3ca9e9f86文章来源地址https://www.toymoban.com/news/detail-617187.html
到了这里,关于Meta-Transformer 多模态学习的统一框架的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!