Neural Networks
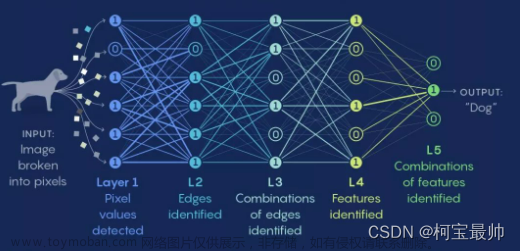
神经网络:一种计算模型,由大量的节点(或神经元)直接相互关联而构成。每个节点(除输入节点外)代表一种特定的输出函数(或者认为是运算),称为激励函数;每两个节点的连接都代表该信号在传输中所占的比重(即认为该信号对该节点的影响程度)
神经网络三要素:模型、策略、算法
概述
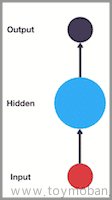
神经网络三层:
- 输入层:数据
- 隐藏层:模型
- 输出层:策略【reLU, sigmoid, tanh, softmax】
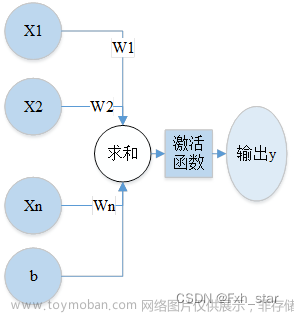
感知机
线性分类模型
\[f(x) = sign(w \cdot x + b)
\]
其中
\[sign(X)=\left\{
\begin{matrix}
+1, x \geqslant 0 \\
-1, x \lt 0
\end{matrix}
\right.
\]
BP算法
神经网络的三要素之算法——反向传播(关键是梯度下降)文章来源:https://www.toymoban.com/news/detail-618042.html
activation
linear activation
\[f(x) = w \mathbf{x} + b
\]
Sigmoid activation
\[f_{\mathbf{w},b}(x^{(i)}) = g(\mathbf{w}x^{(i)} + b)
\]
\[g(x) = sigmoid(x)
\]
ReLU Activation
\[a = max(0, z)
\]
build the network layer
使用Numpy文章来源地址https://www.toymoban.com/news/detail-618042.html
代码
# 建立单层神经网络
def my_dense(a_in, W, b, g):
"""
Computes dense layer
Args:
a_in (ndarray (n, )) : Data, 1 example
W (ndarray (n,j)) : Weight matrix, n features per unit, j units
b (ndarray (j, )) : bias vector, j units
g activation function (e.g. sigmoid, relu..)
Returns
a_out (ndarray (j,)) : j units|
"""
units = W.shape[1]
a_out = np.zeros(units)
for j in range(units):
w = W[:,j]
z = np.dot(w, a_in) + b[j]
a_out[j] = g(z)
return(a_out)
# 建立两层神经网络
def my_sequential(x, W1, b1, W2, b2):
a1 = my_dense(x, W1, b1, sigmoid)
a2 = my_dense(a1, W2, b2, sigmoid)
return(a2)
# 预测
def my_predict(X, W1, b1, W2, b2):
m = X.shape[0]
p = np.zeros((m,1))
for i in range(m):
p[i,0] = my_sequential(X[i], W1, b1, W2, b2)
return(p)
Multi-class Classification
preferred_model = Sequential(
[
# kernel_regularizer 正则化
Dense(120, activation = 'relu', kernel_regularizer=tf.keras.regularizers.l2(0.1), name="L1"),
Dense(40, activation = 'relu', kernel_regularizer=tf.keras.regularizers.l2(0.1), name="L2"), Dense(classes, activation = 'linear', name="L3")
], name="ComplexRegularized"
)
preferred_model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), #<-- Note
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3), # 优化Alpha
)
preferred_model.fit(
X_train,y_train,
epochs=10
)
到了这里,关于【机器学习】神经网络的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!