1、元字符:
. ------- 匹配除换行符外的任意字符
\w ------- 匹配字母或数字或下划线或汉字
\s ------- 匹配任意的空白符
\d ------- 匹配数字
\b ------- 匹配单词的开始或结束
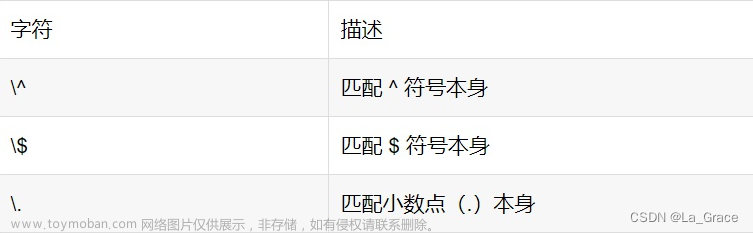
^ ------- 匹配字符串的开始
$ ------- 匹配字符串的结束
2、字符转义 \
3、重复次数{}
* ------- 重复零次或更多次
+ ------- 重复一次或更多次
? ------- 重复零次或一次
{n} ------- 重复n次
{n,} ------- 重复n次或更多次
{n, m} ------- 重复n次到m次
4、字符类[]
[aeiou] --------------- 匹配a,e,i,o,u中的任意字符
[.?!]-------------------- 匹配.,?,!中的任意字符
[0-9]------------------- 匹配0-9中的任意数字
[a-z0-9A-Z]---------- 匹配a-z0-9A-Z中的任意数字
(?0\d{2}[)-]?\d{8}
5、分支条件—从左往右进行|
0\d{2}-\d{8}|0\d{3}-\d{7}
(?0\d{2})?[-]?\d{8}|0\d{2}[-]?\d{8}
6、分组()
(\d{1,3}.){3}\d{1,3}
((2[0-4]\d|25[0-5]|[01]?\d\d?).){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)
7、反义
\W \ 匹配任意不是字母或数字或下划线或汉字的字符
\S \ 匹配任意不是空白符的字符
\D \ 匹配任意非数字的字符
\B \ 匹配不是单词的开始或结束的位置
[^x] \ 匹配除了x以外的任意字符
[^abc] \ 匹配除了abc以外的任意字符
8、后向引用
捕获 (exp) \ 匹配exp,并捕获文本到自动命名的组里
捕获 (?exp) \ 匹配exp, 并捕获文本到名称为name的组里
捕获 (?:exp) \ 匹配exp, 不捕获匹配的文本,也不给此分组分配组号
零宽断言 (?=exp) \ 匹配exp前的位置
零宽断言 (?<=exp) \ 匹配exp后面的位置
零宽断言 (?!exp) \ 匹配后面不是跟着exp的位置
零宽断言 (?<!exp) \ 匹配前面不是exp的位置
注释 (?#comment)
9、零宽断言
查找某些内容之前或之后的东西,也就是说他们像\b,^,$那样用于指定一个位置,这个位置满足一定的条件(即断言)—零宽断言
断言用来声明一个应该为真的事实。正则表达式中只有断言为真时才会继续进行匹配。
(?=exp) \b\w+(?=ing)\b,匹配ing结尾的单词的前面部分。
(?<=exp) (?<=\bre)\w+\b, 匹配以re开头的单词的后半部分
((?<=\d)\d{3})+\b
10、贪婪匹配和懒惰匹配
a.*b \a开始b结束的最长字符
a.*b? \ a开始b结束的最短字符
*? \ 重复任意次,但尽可能少的重复
+? \ 重复一次或多次,但尽可能少的重复
?? \ 重复零次或一次,但尽可能少的重复
{n, m}? \重复n到m次,但尽可能少的重复
{n,}? \重复n次以上,但尽可能少的重复
11、注释
(?#comment) 2[0-4]\d(?#200-249)|250-5|[01]?\d\d?(?#0-199)文章来源:https://www.toymoban.com/news/detail-618128.html
12、平衡组/递归匹配
(?‘greap’)
(?‘-greap’)
(?(group)yes|no)
(?!)文章来源地址https://www.toymoban.com/news/detail-618128.html
到了这里,关于正则表达式简略记录的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!