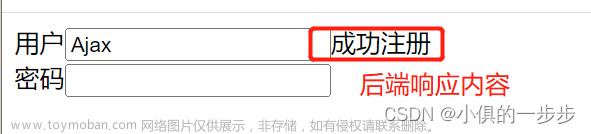
我们要获取这里的响应的JSON数据,但是它的请求头里面带有加密数据,需要js逆向,或者RPC才能拿到,现在介绍一种方法,免去以上过程就可以轻松拿到响应数据。


显然上面的红框是加密数据。
下面正式开始
下载browsermob-proxy文件
首先要检查电脑是否安装了JDK8,高版本的好像不行,如果没有安装,则需要进行安装。这里不介绍了。下面下载两个东西:
(1)python包的安装:pip3 install browsermob-proxy
(2)组件下载地址:https://github.com/lightbody/browsermob-proxy/releases,下载之后解压,后面会用到文章来源:https://www.toymoban.com/news/detail-618346.html
完整代码:文章来源地址https://www.toymoban.com/news/detail-618346.html
import time
from browsermobproxy import Server
from selenium import webdriver
server = Server(".\\browsermob-proxy-2.1.4\\bin\\browsermob-proxy.bat")
server.start()
proxy = server.create_proxy()
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))
browser = webdriver.Chrome(options=chrome_options) # 打开浏览器
browser.maximize_window() # 最大化窗口
url = '所要访问的网址'
# 这里要开一个新的har,用来记录下面打开网址的请求记录,起名为log
# 如果重复访问很多网站,那么每次都得新开一个har,不然一直用一个har,
# 它会累积记录所有的访问和请求数据,每次新开一个再去访问,它只会记录
# 当前的网页的请求
proxy.new_har("log", options={'captureHeaders': True, 'captureContent': True, 'captureBinaryContent': True})
browser.get(url)
time.sleep(60)
# 此处最好暂停几秒等待页面加载完成,不然会拿不到结果,我这里等待的是秒,自己根据情况调整
result = proxy.har
for entry in result['log']['entries']:
_url = entry['request']['url']
# entry每一个请求URL都对应着一个response,我们只需要判断URL找出自己想找的那个JSON就好
if "这里放你需要拿到的JSON数据的请求头中的URL" == _url: #如果两个相等,则可能是我们想要的数据,因为这个URL可能有多个,
# 在后面拿到数据之后再进一步判断即可
_response = entry['response']
_content = _response['content']
print(_content)
server.stop()
browser.quit()到了这里,关于抓取网络请求Network中的响应JSON数据,不用JS逆向和RPC,python selenium+browser-proxy的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!