🐱作者:一只大喵咪1201
🐱专栏:《网络》
🔥格言:你只管努力,剩下的交给时间!

🏀认识HTTP协议
上篇文章中,本喵带着大家对HTTP有了一个初步的认识,今天就来详细讲解一下这个应用层协议。
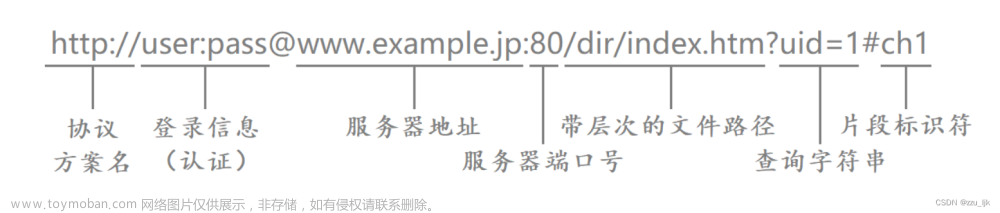
⚽urlencode和urldecode

如上图所示的url(网址),里面包含有/以及?等字符。
- 像这样的字符,已经被url当做特殊意义理解了,因此这些字符不能随意出现。
如果url中要包含这些特殊意义的字符,就需要对其做转义处理,就类似C语言中的转义字符一样。但是这里是网络,转义的规则不和C语言一样,它有自己的规则:取出字符的ASCII码:
- 转成16进制,然后前面加上百分号即可。
比如,+号被转义后成为%2B,这个过程就叫做encode,而将%2B转回到+号就叫做decode。
这个过程并不需要我们自己去做,有需要进行编码和解码的需求在网上直接查就可以,URL编码/解码。

如上图,将字符C++进行urlencode后的结果是C%2B%2B,同样也可以进行urldecode进行解码。

上图是本喵在百度上搜索C++后跳转到的网页的URL(网址),可以看到红色框中的wd=C%2B%2B,其中wd表示关键字,=号后面的内容就是encode后的结果。
当服务器收到url请求后,会自行对特殊字符%xx进行decode。包括汉字也需要进行encode和decode。
⚽HTTP协议宏观格式
- HTTP是基于请求和响应的应用层协议,使用的是
TCP套接字,客户端向服务端发送request请求,服务端收到请求后会作response响应返回给客户端。

如上图所示,是HTTP协议的宏观格式,包括客户端的request和服务端的response。
- 客户端:
请求行: 如上图红色框中所示,包含GET方法,url,还有http协议的版本,如http/1.0或者http/1. 1,这三部分构成请求行,必须使用\r\n来结束这一行。
请求报头: 如上图绿色框中所示,包含的都是请求属性,采用的是键值对的形式,name表示属性的名称,如HOST等,value是属性的内容,如具体的一个网址。每一个属性必须以\r\n来结束。
空行: 如上图紫色框中所示,这一行什么内容都没有,只有\r\n用来表示空行。
请求正文: 如上图最下面的黑色框中所示,包含请求的正文,如username用户名,passwd密码等,同样每个正文后面必须以\r\n来结束。
- 正文可以省略不写,但是其他三部分必须有,以空行为界,空行后面的是请求正文,空行前面的是请求行和请求报头。
- 每一部分都是以字符串形式放在报文中,如
GET url http/1.0\r\nname: value\r\n\r\n,这一个报文中,包含请求行,一行属性以及空行。
请求行和请求报头两部分可以看成我们自定义协议中的报头,请求正文是有效载荷。
- 服务端:
状态行: 如上图红色框中所示,包含http/1.1HTTP协议版本,状态码以及状态码描述,最后是\r\n。
响应报头: 如上图绿色框中所示,包含响应属性,和request的请求报头类似。
空行: 如上图紫色框中所示,也是只有一个\r\n。
响应正文: 如上图黑色框中所示,包含服务器要给客户端返回的数据内容,如html/css/js以及图片,视频,音频等网络资源。
- 状态行和响应报头同样类似我们自定义协议中的报头,响应正文是有效载荷。
-
服务端的
response和客户端的request格式相同,只是每一块的内容有所差异。 - 每一部分中具体名词的含义后面本喵会讲解。
按照上面HTTP协议的宏观格式,存在几个细节问题:
- 应用层怎么保证完整的读取了一个请求或者响应?
首先肯定可以完整的读完一行,因为每一行都是以\r\n结尾的,所以使用while(完整读取一行)的循环可以读完请求行+请求报头,直到空行再停止。
按照我们自定义协议中的逻辑,此时报头(请求行+请求报头)完全读完了,还剩下有效载荷(请求正文)。同样地,在请求报头中有一个属性`Content-Length:XXX正文长度``,根据这个正文长度就可以将所有的请求正文读取完毕。
此时一个完整的请求request就读取到了,同样的方式也可以读取到一个完整的响应response。
- 请求和响应是怎么做到序列化和反序列化的?
序列化和反序列化是由HTTP自己实现的,因为协议中的内容都是字符串,第一行(请求行/状态行) + 请求/响应报头,只要按照\r\n为判断条件,一直循环下去,就可以拼接(序列化)或者拆分(反序列化)。
正文不用进行序列化和反序列化,因为它本身就是字符串,根据Content-Length:XXX正文长度读取相应字节数就可以。
🏀验证HTTP协议格式
上面都是本喵在说HTTP是这样的格式,那么到底是不是呢?下面写代码来看一下。
服务器底层连接代码仍然用之前TCP套接字写好的:

其他代码本喵就不截图了,在本喵文章TCP网络通信有详细讲解,这里就直接拿来用了,如上图所示,handlerEnter是服务器处理任务的入口。

如上图所示,不一样的地方还有在增加了一个回调函数,包装器类型:using func_t= function<bool(const request& req, response& resp)>。除此之外,类名也变成了httpServe。
重点在于下面的代码,服务器是处理任务的:

先在protocol.hpp中定义请求request和响应response,如上图所示,此时请求和响应中只有一个string类型的成员变量。

当服务器在执行handlerEnter的时候,首先从网络中读取数据,这里假设recv一次就能完整读取一个请求(后面再进行优化),然后将读取到的报文完整赋值到请求req的字符串inbuffer中,再通过_func回调函数根据请求req构建响应resp,再将响应发送到网络中。

如上图所示的DealReq就是服务器调用的回调函数,用来处理请求并构建响应的,这里本喵暂时仅打印请求req的inbuffer中的内容。
- 该函数在构造服务器
httpServe对象的时候就被作为参数传给了构造函数,服务器中的回调函数掉的就是该函数。
由于从网络中读取到的数据,也就是客户端的请求request并没有经过反序列化,也没有去除过报头,所以此时req的inbuffer中的内容就是一个完整的报文(字符串),包括报头和有效载荷。

先将我们的服务端程序运行起来,如上图序号1所示,然后在windows端打开浏览器,在输入网址的地方输入http://服务端公网IP+端口号,如上图序号2所示,然后访问这个url。

此时windows的浏览器就是客户端,当访问这个url的时候,客户端就向服务端发起了请求,使用的协议是http协议。在服务端将收到的请求完整打印出来,结果如上图所示。
-
打印出来的
http请求的格式符合本喵前面介绍的宏观格式,并且将每一块中的具体信息都打印了出来。
下面本喵就来介绍一下,http请求中每一行的具体内容是什么。
⚽请求的格式
请求行:
请求行中的内容是GET / HTTP/1.1。
-
GET:表示请求方法,后面详细讲解。 -
/:表示url,也就是要访问服务器上文件所在的具体路径。
这里本喵在windows端输入网址的时候,并没有指定路径,所以在客户端(浏览器)的http协议会将请求路径默认构建成\表示根目录。

在windows浏览器中输入网址的时候,加上请求地址/a/b/c,如上图红色框中所示,在客户端发起请求时,服务端收到的http请求的请求行中也会有相应的请求地址。
请求地址中的第一个/就表示根目录,和默认请求路径中的根目录是一个路径,但是这个根目录并不是Linux服务器上的根目录,而是web根目录。

如上图红色框所示,存在一个目录wwwroot,这个目录就是web根目录,它位于当前服务端进程所在的当前目录,所以说,/根目录可以是任何一个目录,因为wwwroot可以创建在任何地方。

在windows客户端发起请求的时候,输入网址中的路径/a/b/c访问的就是上图红色框中所示的c.html文件。
-
HTTP/1.1表示http协议的版本号是1.1,常用的版本号还有1.0。
之所以在请求行中要包含http协议的版本号,是为了服务器能够合理的给客户端提供对应的服务。由于客户端的更新情况不一致,有的是1.0版本的,有的是1.1版本的,此时服务端根据请求行中的版本号就能够给不同版本的客户端提供不同的服务。
请求报头:
请求报头中包含许多请求属性,每一条属性为一行,使用\r\n结尾。
-
Host:43.143.106.44:8080,表示客户端所请求服务端是套接字(IP地址 + 端口号)。 -
Connection: keep-alive,表示长连接,后面详细讲解。 -
Upgrade-Insecure-Requests: 1,表示浏览器(客户端)支持自动将HTTP请求升级到HTTPS请求。在学习了https协议后才能感受到这一属性的作用。 -
User-Agent: 相关信息: 用于表示客户端的相关信息。

如上图所示,User-Agent后面的内容包括客户端的操作系统和使用的浏览器等信息。
-
Accept: 相关信息:表示该请求要请求的资源类型。

由于本喵使用的是windows端的浏览器向服务端发起的请求,并且没有设置Accept属性,也就是没有指定要请求的资源类型,所以浏览器默认将http能请求的所有资源类型都加在了Accept属性中。
-
Accept-Encoding: gzip, deflate:表示客户端支持两种encode格式。
服务器可以根据客户端的支持情况采用不同的压缩算法进行内容压缩。常见的压缩算法有gzip和deflate。
-
Accept-Language: zh-CN,zh;q=0.9:表示客户端支持的语言格式。
请求报头中的所有属性都是采用name: val的键值对形式,并且是一个字符串。
之后就是一个空行,只有一个\r\n。
⚽响应的格式

在处理请求构建响应的函数DealReq中,先打印出请求的内容,和之前一样。之后开始构建响应,按照HTTP的宏观格式构建响应:
- 构建状态行,包括
HTTP版本,状态码,状态码描述,最后以\r\n结束。 - 构建响应报头,也就是响应属性,这里本喵暂时只写一个属性
Content-Type: text/html\r\n,暂时不用管它是什么意思。 - 构建空行,只有
\r\n但是这个空行必须有。 - 构建响应正文:本喵暂时不写任何响应正文。
构建好了响应response之后就是将其序列化,也就是将这些不同类型的字符串拼接在一起,如上图绿色框中所示,最后由服务器发送到网络中。
如何看到服务器构建的响应呢?使用一个telnet工具,如果你的Linux服务器上没有的话,使用yum下载一个即可。

- 使用
telnet工具,通过本地环回的IP地址和端口号向服务器发起请求。 - 键盘上按
ctrl + 回车,出现telnet>,再按一下回车跳到下一行。 - 输入
GET / HTTP/1.1,手动输入请求行,然后按回车。
此时就向服务端发起了请求,会收到服务端的响应,如上图绿色框中所示,这部分内容就是我们上面代码中构建的响应内容,可以看到有状态行,响应报头,还有空行。
此时我们已经验证了http的请求和响应和本喵前面介绍的宏观合适是相一致的。
🏀理解HTTP协议
上面本喵已经通过代码让大家看到了HTTP的请求和响应,从而也验证了HTTP宏观格式,接下来就对HTTP协议做一个更深入的理解。

在请求中增加几个成员变量,包括请求访问method,请求的url,请求的http版本httpversion,以及一个请求路径。
再通过成员函数parse对请求进行反序列化,首先使用getOneLine读取请求中的请求行,然后将请求行中的三个字段分离出来。

创建一个工具类Util,将一些公用的工具类函数放在里面,如上图所示,获取请求一行内容的函数getOneLine就放在里面。

再在服务器的处理入口handlerEnter中调用请求的成员函数parse进行反序列化。

在处理请求,构建响应的函数DealReq中,将请求行中的三个字段打印出来,由于通过parse已经反序列化了,所以直接打印req中的字段成员变量即可。
在构建响应正文的时候,添加一段html的代码,如上图所示,并且将代码以字符串的形式拼接到响应上。

使用telnet工具向服务端发起请求,此时就会得到服务端的响应,如上图所示,包括响应正文(html的代码)。

在服务端就可以看到telnet在发送请求是输入的请求行中的三个字段,如上图红色框中所示。
-
telnet发起请求后,得到的响应正文中的html代码到底是什么意思呢?

用windows上的浏览器来访问服务器,可以得到如上图所示的一个网页,网页中有一个字符串Hello HTTP,而这个字符串在响应正文的html代码中也出现过。
- 响应正文中的
html代码就是一个网页,是服务端响应给客户端的一个网页。- Linux中使用
telnet得到响应正文并没有被解释,所以是完整的html代码,使用Windows的浏览器得到响应正文会被浏览器做解释,解释后得到的就是一个网页。
关于html的知识,用到的去查一下即可,本喵这里就直接用了。
⚽服务器和网页分离
上面代码中,服务器构建响应正文时,直接将html代码放在了string resp_body中,这种将前端代码嵌入到后端代码中的方式是不妥的,所以要将前端的html代码和后端分离开来。

如上图所示,在wwwroot根目录下创建几个文件,其中404.html和index.html直接位于根目录中,a.html和b.hmtl位于wwwroot/test目录下。
这四个html的文件内容不同,表示的网页也不同,作用也不同。
404.html:

如上图代码所示,当客户端发起的请求中url错误或者无效时,会将该文件中的内容作为响应正文返回给客户端,告知客户端访问资源不存在,并且显示404错误。
index.html:

如上图代码所示,当客户端发起的请求中url为\时,例如http://127.0.0.1:8080/,此时会将该文件中的内容作为响应正文给客户端返回。
因为此时客户端访问的就是web根目录,也就是./wwwroot目录,所以当用户访问根目录的时候,本喵将该目录下的index.html作为响应返回。
a.htmlh和b.html:

如上图代码所示,当客户端发起的请求中url为/test/a.html和/test/b.html的时候,服务器就会将这两个文件的没人作为响应正文返回给客户端,客户端就会得到两个网页。
上面4个文件中的代码都是html代码,如果将文件内容响应给Windows的浏览器,就会以网页的形式展现,这点本喵在前面展示过。
虽然是网页,但是归根到底,仍然是存在于Linux服务器磁盘上的四个文件,只是后缀是.html而已。
所以服务端要想将文件中的内容作为响应正文返回给客户端,就需要将文件中的内容读出来,并且以字符串的形式拼接到响应中。

在Util.hpp中再增加一个工具函数,如上图所示的readFile,该函数专门用来读取文件中的内容,并且以二进制的方式读取到缓冲区buffer中。
- 必须以二进制的方式,如果以文本的形式读取图片就会出现bug。

如上图代码所示,在DealReq中构建响应时,使用readFile工具函数读取请求中用户所指定路径中html文件中的内容。
如果读取失败,说明没有用户指定的文件,则读取404.html文件中的内容作为响应正文返回给客户端。
在调用readFile的时候,会传入req.path客户端指定的路径,以及resp_body,还有req.size,那么path和size是怎么来的呢?
可以看到,这两个参数都是req的成员变量,所以要在httprequest中处理:
获取客户端指定路径:
首先将web根目录定义出来,如上图代码所示的default_root就表示web根目录。
在parse函数中,先给path赋值为default_root,path的值为./wwwroot。再拼接请求中的url,例如请求是http://127.0.0.1:8080/test/a.html,将/test/a.html拼接到path中以后就成为./wwwroot/test/a.html。
如果请求中没有写url也就是采用默认的/,那么拼接以后path的值就是./wwwroot/表示访问web根目录,此时让其访问home_page首页。
获取html文件大小:

Linux中存在一个系统调用stat,就是用来获取文件大小的,如上图所示。
参数:
- path:目标文件的路径。
- buf:是一个struct stat类型的自定义变量,它的成员变量就有文件的大小(以字节为单位)。
- 返回值:调用成功返回0,调用失败返回-1。

上图所示就是struct stat的定义,成员包含很多文件的属性,如文件的inode,硬链接数等等,而我们需要的就是st_size文件大小。
所以在httpRequest中通过系统调用stat来获取文件的大小,如上图代码中紫色框所示。
- 如果文件不存在,就获取
404.html文件的大小。
此时我们前端的网页以及后端的服务器都写好了,接下来就可以运行了。

在Windows上的浏览器访问根目录,就会出现上图大喵咪网址首页,而在服务端可以看到这次请求,其中url是/,path./wwwroot/index.html。

用浏览器访问根目录下的test/a.html,如上图所示,会得到网页我是a网页。同样可以在服务端看到url是/test/a.html,path是./wwwroot/test/a.html。
访问b.html和上面一样,只是最后的文件名不一样而已。

当访问一个不存在的网络资源时,就会得到404错误的网页,表示访问资源不存在。
此时就做到了服务器和网页的分离。
⚽请求方法
请求方法非常多,但是常用的就两种,分别是GET和POST方法。

在Windows上的浏览器,百度的搜索框对应的html代码如上图所示。我们之所以能够搜索东西,是因为这个搜索框本质上是一个form表单,如上图红色框所示。
我们搜索的关键字就填入这个表单中,然后再将表单的内容一起通过HTTP协议发送请求到服务端,服务端再做出相应的响应。
- 我们进行数据提交的时候,本质是前端要通过
form表单提交,浏览器会自动将form表单中的内容转化成为GET/POST方法请求。
GET方法:

在index.html中增加form表单,如上图代码所示,其中action是客户端提交信息后要服务端执行的动作,本喵这里是让服务端执行/test/a路径下的python程序。
method是请求方法,这里本喵设置为GET方法。
提交的form表单中,第一行是姓名,第二行是密码,第三行是登录按钮。

在浏览器访问根目录,也就是在访问服务器的index.html文件,如上图所示。此时是客户端第一次发起请求,所以服务端会将index.html的内容返回给客户端,此时返回的网页中包含form表单。

如上图所示,服务端收到的第一次请求是请求./wwwroot/index.html路径下的文件。
- 第一次默认采用
GET方法。

填好姓名和密码后登陆就会弹出如上图所示的网页,此时是客户端向服务端发送的第二次请求。
- 提交后的
action是让服务器执行/test/a/c.py下的文件,由于不存在,所以返回资源不存在。 -
form表单中的姓名和密码以xname=damiaomi&ypwd=123456的形式拼接在了url中,如上图网址中的绿色框。

如上图是服务器在客户端提交form表单后收到的请求,可以看到,表单中的内容被拼接到了url中。
POST方法:

如上图代码所示,将index.html中的method改成POST方法,其他内容不变。进行前面那样的操作:

第一次发起请求时同样访问服务端的根目录,上图所示的网页是服务端给客户端的第一次响应,也是包含一个form表单。

从服务器中看到,此次请求的方法仍然是GET方法,因为这是第一次请求,我们指定的POST方法是在提交表单时使用的,也就是在第二次请求中使用的。

输入姓名密码后点击登录,输入的内容和前面一样,同样会出现资源不存在的网页,原因也是action的文件不存在。
-
此时
form表单中的内容没有拼接到url中,如上图红色框中所示。

如上图所示是服务器收到的第二次请求内容,可以看到,此时使用的是POST请求方法,url以及path都是截止到action指定的路径处,如上图红色框中所示。
-
form表单中的内容以请求正文的形式提交给了服务器,如上图橘色框中所示。
通过上面对比我们发现,GET/POST请求方法的区别在于:
-
GET方法通过url提交参数。 -
POST方法通过HTTP请求正文提交参数。
站在客户端的角度,如果使用GET方法,在提交form表单的时候,内容会拼接到url中,在浏览器的网址栏中可以看到,如果是账号密码的话其他人就能够直接看到。
如果使用POST方法,在提交form表单的时候,内容是通过请求正文提交的,在浏览器的网址栏中看不到。
所以,如果提交的数据是比较私密的,如账号密码等,就使用POST方法,如果无所谓的数据就使用POST/GET哪个都行。
- 本喵并不是说
POST方法比GET方法安全,仅仅是POST方法无法直观的看到提交的数据。POST/GET两种方法都是不安全的。
⚽常见报头属性

在使用POST方法发起HTTP请求后,多了几个GET方法中没有的属性,如上图所示。
Content-Type: xxx\r\n
表示连接类型,请求和响应中都有。
上图所示的是请求中的Content-Type,由于会用表单提交数据所以它的值如上图红色框中所示。这是浏览器在告诉服务器,它提交的请求类型是form,服务器需要按照表单的处理方式来处理。

上图所示是响应中的Content-Type,本喵在处理请求构建响应时,响应报头中只有一个属性Content-Type: text/html\r\n。
由于服务器响应给客户端浏览器的是一个html文件的内容,查阅一下Content-Type对照表:

如上图红色框中所示,html对应的Content-Type的值必须是text/html,这是在告诉浏览器,服务器给它的响应是html类型的数据,浏览器需要按照html的处理方式来解释。
Content-Length: XXX\r\n
使用POST方法发起请求时,服务器收到的请求中就有Content-Length这一属性,用来表示请求正文的长度,以字节为单位。
同样的,在构建响应的时候,也可以将这属性作为响应报头加进去,表示响应正文的长度,浏览器可以自动识别这一属性。

在DealReq函数中构建响应的时候,添加Content-Length: xxx属性,如上图红色框中所示,该属性的值就是服务器返回给客户端的文件大小,存放在req中。
然后将响应正文长度属性拼接到相应报头中,一起发出去。

此时使用telnet工具向服务器发起请求时,得到响应中包含Content-Length,如上图红色框中所示。在使用浏览器发起请求时,浏览器能自动识别Content-Length这一响应属性,并作相应处理。
⚽Connection: keep-alive

此时index.html中有内容,有跳转网页,有图片,还有表单等等内容,如上图所示。

浏览器访问根目录时,得到的网页中有这么多内容,如上图所示。

在浏览器上本喵只输入了一次网址,然后回车,但是服务器上却收到了多个请求,如上图所示(本喵仅截图几个)。不同请求的url和path不同。
- 一个网页中有多种类型的资源,而一次请求只能获取一种类型资源。
- 虽然我们在浏览器中只访问一次,但是浏览器会通过多个线程发起多次请求。
- 多次请求的多个响应共同组成了一个网页。
我们知道HTTP协议使用的是TCP网络通信那一套,所以客户端的每一个请求,服务器都会创建一个套接字。
像上面这种请求,仅访问一个网页就会创建多个套接字,会导致套接字资源紧张,所以就出现了长连接的解决方案。
长连接:
- 一个客户端对应一个套接字,客户端的一个请求响应完后,套接字不关闭,只有客户端退出了,或者指定关闭时,套接字才关闭。
- 一个客户端无论有多少个请求,都通过一个套接字和服务器进行网络通信。
这里本喵仅能从概念上来给大家讲解,无法做出具体的实验现象。
⚽会话保持(Cookie和Session)
Cookie技术:
假设访问CSDN使用的是HTTP协议。
CSDN在第一次登录后,之后打开CSDN就不用再进行登陆了。根据前面学习我们知道,登录时输入的信息其实就是form表单,然后将数据提交给服务器,让服务器进行鉴权,如果权限符合就会返回对应的响应。
- HTTP实际上是一种无状态协议,每次请求并不会记录它曾经请求了什么。
所以,在第一次登录CSDN后,在站内进行网页跳转(从一篇文章到另一篇文章)时,理论上需要再次输入账号密码进行登录,让服务器进行鉴权,因为HTTP的每次请求/响应之间是没有任何关系的。
- 但我们在使用浏览器访问CSDN的时候发现并不是这样的,只需要登录一次即可。
这是因为浏览器在我们第一次登录CSDN的时候,将我们的账号密码等登录信息保存了下来。
当我们进行网页跳转或者再次打开CSDN的时候,浏览器自动将保存的用户登录信息添加到了请求报头中,并通过HTTP协议发送给了服务器,服务器进行鉴权并返回对应的响应。
- 登录还是需要的,只是浏览器帮我们做了这个事。
- 这种技术就叫做Cookie技术。

如上图所示,点击网址前面的小锁,可以查看当前浏览器正在使用的Cookie。
当我们将上图中和CSDN有关的Cookie数据删除后就需重新输入账号密码来登录了。
- 用户在第一次输入账号和密码时,浏览器会进行保存(Cookie),近期再次访问同一个网站(发送http请求),浏览器会自动将用户信息添加到报头中推送给服务器。
- 这样只要用户首次输入密码,一段时间内将不用再做登录操作了。
Cookie又分为内存级和文件级:
- 内存级
Cookie:将信息保存在浏览器的缓冲区中,当浏览器被关闭时,意味着进程结束,保存的信息也就没有了,重新打开浏览器后还需要重新登录。 - 文件级
Cookie:将信息保存在文件中,文件是放在磁盘上的,无论浏览器怎么打开关闭,文件中的信息都不会删除,在之后发送HTTP请求时,浏览器从该文件中读取信息并加到请求报头中。
根据日常使用浏览器的情况,我们可以知道,大部分情况下的Cookie都是文件级别的,因为关闭了浏览器下次打开不用再重新登录。
Cookie文件也是存在我们电脑上的,具体路径有兴趣的小伙伴可以去找一下。
Session:
如果我们电脑上的Cookie文件被不法份子盗取,那么它就能以我们的身份去登录我们的CSDN,并且进行一些非法操作。
- 为了保证信息安全,新的做法是将用户的账号密码信息以及浏览痕迹等信息保存在服务器上。
- 每个用户对应一个文件,这个文件被叫做
Session文件,由于存在很多的Session文件,所以给每个文件一个名字,叫做Session id。- 服务器将
Session id作为响应返回给用户,此时用户的Cookie中保存的就是这个id值。

如上图所示,当第一次登录时,浏览器的form表单中的用户信息提交到了服务器,服务器创建Session文件并保存用户信息,然后再生成一个id返回给浏览器。
此时浏览器的Cookie保存的就是这个id值。当进行站内页面跳转或者再次打开CSDN的时候,浏览器自动将Cookie中Session id加到请求报头中提交给服务端。
服务端收到请求后,拿到请求报头中的Session id找到对应的Session文件进行鉴权,看看身份是否符合。
鉴权完毕后做出相应的响应返回给浏览器。
- 服务端存储用户信息的技术就叫做
Session技术。
为什么新的会话保持(Cookie和Session)技术能够提高用户信息的安全性呢?
- 服务端是由专业的人员维护的,服务器中存在病毒以及流氓软件的可能想更小,所以用户信息在服务端会更安全。
- 如果客户端的
Cookie中的Session id被盗用,不法分子使用该id向服务端发起请求时,会因为常用IP地址不一样而被服务端强制下线,此时只有手里真正有账号密码的人才能够再次登录。
保证Session安全的策略非常多,有兴趣的小伙伴可以自行了解。
写入Cookie信息:
我们知道,浏览器的Cookie信息是服务端响应返回的,所以在我们构建响应的时候也可以构建Cookie信息让浏览器去保存。

在DealReq函数中构建响应时,设置Cookie信息,内容是name=123456abc,有效时间是三分钟,然后加到响应报头中返回给客户端,如上图所示。

使用浏览器访问根目录的时候,如上图所示,会得index.html文件表示的网页,查看该网页的Cookie信息,可以看到name是123456abc,有效时间是3分钟,和我们在服务端构建响应时写的内容一模一样。
-
浏览器将我们在响应中设置的
Cookie内容当作了Session id。
真正生成Session id是有一套复杂的算法的,它能够保证每一个Session文件的id都是独一无二的。
Cookie和Session两种技术共同组成了HTTP的会话保持。
⚽HTTP状态码

本喵在DealReq中构建响应的时候,状态行中的状态码直接写的200,状态码描述是OK。那么状态码到底有哪些呢?它们代表的意义是什么?
状态码有五种类型,分别以1~5开头:
| 状态码 | 类别 | 原因短语 |
|---|---|---|
| 1XX | informa(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常且处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
最常见的一些状态码,如200(OK),404(Not Found),403(Forbidden请求权限不够),302(Redirect),504(Bad Gateway)。
重定向状态码(3XX):
这些状态码没啥好说的,重点说一下重定向。
- 重定向就是将网络请求重新定个方向转到其它位置(跳转网站),此时这个服务器相当于提供了一个引路的服务。
相信都有过这样的经历,打开一个网址以后,自动就弹出一些广告网页,这就是一种重定向。
-
浏览器发送请求给服务端,服务端返回一个新的
url,并且状态码是3XX,浏览器会自动用这个新的url向新地址的服务端发起请求。
所以说,重定向是由客户端完成的,当客户端浏览器收到的响应中状态码是3XX后,它就会自动从响应中寻找返回的新的url并发起请求。
重定向又有两种:
- 永久重定向:状态码为
301。 - 临时重定向:状态码为
302和307。
临时重定向和永久重定向本质是影响客户端的标签,决定客户端是否需要更新目标地址。
如果某个网站是永久重定向,那么第一次访问该网站时由浏览器帮你进行重定向,但后续再访问该网站时就不需要浏览器再进行重定向了,此时直接访问的就是重定向后的网站。
而如果某个网站是临时重定向,那么每次访问该网站时都需要浏览器来帮我们完成重定向跳转到目标网站。

如上图代码所示,在DealReq函数中构建响应时,状态行中的状态码设为307,状态码描述为Temporary Redirect,表示临时重定向。
设置属性Location: XXX,其值是重定向后的地址,这里是本喵CSDN的首页地址。
然后将属性Location拼接到响应报头中,最后再发送给客户端。

在浏览器中访问index.html,但是发起请求后,返回的并不是index.html中的内容,而且属性Location的值所指向的网页,也就是本喵CSDN的首页。

当浏览器发起请求访问index.html的时候,收到的响应中,状态码是307,所以浏览器不解释index.html,而是根据响应报头中的Location属性,得到新的url,再向新的url发起请求,得到新的响应,也就是本喵的CSDN首页。文章来源:https://www.toymoban.com/news/detail-618657.html
- 永久重定向无法演示出来,效果和临时重定向一样。
🏀总结
这篇文章的思路是,先宏观介绍HTTP协议的格式,然后通过代码去验证这个格式,然后再把验证结果中的具体属性进行讲解。一些重点属性会单独举例进行讲解。文章来源地址https://www.toymoban.com/news/detail-618657.html
到了这里,关于【网络】应用层——HTTP协议的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!