✨个人主页: 北 海
🎉所属专栏: C++修行之路
🎃操作环境: Visual Studio 2022 版本 17.6.5

🌇前言
注册账号是进行网络冲浪的第一步操作,而拥有一个具有个性且独一无二的用户昵称是非常重要的,很多人在填写昵称时,常常会看到 此昵称已存在 的提示,系统是如何快速知道当前昵称是否存在呢?总不能挨个去遍历对比吧,这时候就需要我们本文中的主角: 布隆过滤器

🏙️正文
1、字符串比较
常见的字符串比较方法是 按 ASCII 码值进行比较,直到两个字符串同时结束,说明两者一致
比如字符串1 abcdef 和字符串2 azbmcy
显然两个字符串不一样
这种比较方法很直接,也很可靠,但缺点也很明显:需要对字符串进行遍历
一个字符串还好,如果是几千万个字符串呢?不但需要消耗大量存储空间,查找效率也很低,此时填写个昵称,服务器都要跑一会才有反映,这是用户所无法容忍的
因此人们想出了另一个方法,利用哈希映射 的思想,计算出 哈希值,存储这个值即可,可以借此 标识字符串是否存在
在进行字符串(昵称)比较时,只需要计算出对应的 哈希值,然后看看该位置是否存在即可
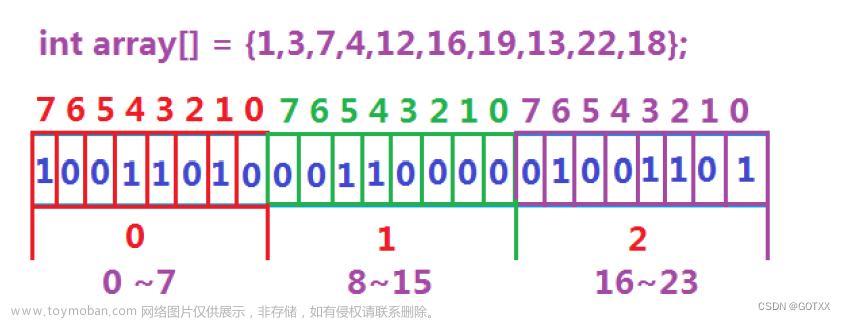
哈希值 也是一个整数啊,可以利用 位图 进行 设置,查找字符串时,本质上是在 查找哈希值是否在位图中存在
字符串有千万种组合,但字符是有限的,难免会出现 误判 的情况(此处的 哈希函数 为每个字符相加)

为了尽可能降低 误判率,在 位图 的基础之上设计出了 布隆过滤器
接下来看看什么是 布隆过滤器 吧

2、布隆过滤器的概念
这里是 布隆 可不是 英雄联盟中的 弗雷尔卓德之心 布隆,毕竟他也不能解决字符串比较问题,他只是 召唤师峡谷 中的一个坦克,主要负责 过滤(吸收) 敌方的伤害
布隆过滤器 是由 布隆(Burton Howard Bloom) 在 1970 年提出的一种 紧凑型的、比较巧妙 的 概率型数据结构,特点是 高效地插入和查询
布隆过滤器 的核心在于通过添加 哈希函数 来 降低误判率
举个例子,如果每个人的名字都只有一个字,那么肯定存在很多重名的情况,但如果把名字字数增多,重复的情况就会大大缓解
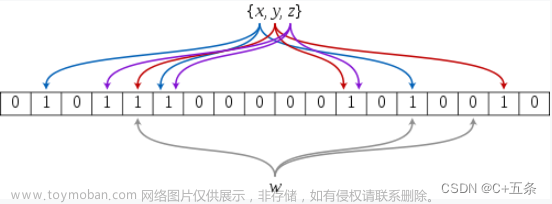
所以 布隆过滤器 其实很简单,无非就是映射字符串时,多安排几个不一样的 哈希函数,多映射几个 比特位,只有当每个 比特位 的为 1 时,才能验证这个字符串是存在的

3、布隆过滤器的实现
3.1、基本结构
布隆过滤器 离不开 位图,此时可以搬出之前实现过的 位图结构
既然需要增加 哈希函数,我们可以在模板中添加三个 哈希函数 的模板参数以及待存储的数据类型 K
namespace Yohifo
{
template<size_t N,
class K,
class Hash1,
class Hash2,
class Hash3>
class BloomFilter
{
public:
//……
private:
Yohifo::bitset<N> _bits; //位图结构
};
}
显然,这三个 哈希函数 的选择是十分重要的,我们在这里提供三种较为优秀的 哈希函数(字符串哈希算法),分别是 BKDRHash、APHash 以及 DJBHash
函数原型如下(写成 仿函数 的形式,方便传参与调用):
struct BKDRHash
{
size_t operator()(const std::string& str)
{
size_t hash = 0;
for (auto e : str)
{
hash = hash * 131 + (size_t)e;
}
return hash;
}
};
struct APHash
{
size_t operator()(const std::string& str)
{
size_t hash = 0;
for (auto e : str)
{
if (((size_t)e & 1) == 0)
{
hash ^= ((hash << 7) ^ (size_t)e ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ (size_t)e ^ (hash >> 5)));
}
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const std::string& str)
{
if (str.empty())
return 0;
size_t hash = 5381;
for (auto e : str)
{
hash += (hash << 5) + (size_t)e;
}
return hash;
}
};
因为 布隆过滤器 中最常存储的数据类型是 字符串,并且三个 哈希函数 我们也已经有了,所以可以将 布隆过滤器 中模板添加上 缺省值
template<size_t N,
class K = std::string,
class Hash1 = BKDRHash,
class Hash2 = APHash,
class Hash3 = DJBHash>
如何创建一个布隆过滤器?
BloomFilter<100> bf; //最大值为 100 的布隆过滤器
3.2、插入
插入 无非就是利用三个 哈希函数 计算出三个不同的 哈希值,然后利用 位图 分别进行 设置 就好了
void set(K& key)
{
size_t HashI1 = Hash1()(key) % N; //% N 是为了避免计算出的哈希值过大
_bits.set(HashI1);
size_t HashI2 = Hash2()(key) % N;
_bits.set(HashI2);
size_t HashI3 = Hash3()(key) % N;
_bits.set(HashI3);
}
注意:布隆过滤器的插入操作是一定会成功的,因为不管是什么字符串,都可以在其对应的位置留下痕迹
3.3、查找
查找 某个字符串时,需要判断它的每个 哈希值 是否都存在,如果有一个不存在,那么这个字符串必然是不存在的
bool test(const K& key)
{
//过滤不存在的情况,至于是否存在,还得进一步判断
size_t HashI1 = Hash1()(key) % N;
if (_bits.test(HashI1) == false)
return false;
size_t HashI2 = Hash2()(key) % N;
if (_bits.test(HashI2) == false)
return false;
size_t HashI3 = Hash3()(key) % N;
if (_bits.test(HashI3) == false)
return false;
//经过层层过滤后,判断字符串可能存在
return true;
}
查找 函数可以很好的体现 过滤 的特性
如何判断一个人是否存在
不能盲目去查找,而是应该根据姓名,查询身份证号、住址等个人信息,如果这些信息都没有,那么就说明这个人不存在,因为这些信息足够过滤出结果了;如果出现重名或信息重复的情况,则需要进一步判断,这就是说明 通过过滤判断 “存在” 是不准确的,但判断 “不存在” 是准确的
布隆过滤器判断 “不在” 是准确的,判断 “在” 是不准确的
比如,字符串1映射了 1、6、7 号位置,字符串2映射了 2、4、5 号位置,字符串3映射了 1、3、4 号位置,虽然这三个字符串不会相互影响,但如果此时字符串4映射的是 1、2、3 号位置,会被误断为 存在,理论上 字符串存储位置越密集,误判率越高

所以对于一些敏感数据,如果要判断是否存在,不能只依靠 布隆过滤器,而是使用 布隆过滤器 + 数据库 的方式进行双重验证
当然,如果 布隆过滤器 判断字符串不存在,那么就是真的不存在,因为这是绝对准确的
布隆过滤器 能容忍误判的场景:注册时,判断昵称是否存在
3.4、删除
一般的 布隆过滤器 不支持删除,一旦进行了删除(重置),会影响其他字符串

表面上只删除了 “腾讯”,但实际上影响了 “百度”,在验证 “百度” 是否存在时,会被判断为 不存在,此时只有三个字符串,如果有更多呢?造成的影响是很大的,所以对于一般的 布隆过滤器,是不支持删除操作的
如何让布隆过滤器支持删除?
关于共用同一份资源这个问题,我们以前就已经见过了,比如 命名管道,当我们试图多次打开同一个 命名管道 时,操作系统实际上并不会打开多次,因为这样是很影响效率的,实际每打开一次 命名管道,其中的 计数器++,当关闭 命名管道 时,计数器--,直到 计数器 为 0 时,命名管道 才会被真正关闭
这不就是 引用计数 的思想吗?
我们可以给每一个 比特位 带上一个 引用计数器,用来表示当前位置存在几个映射关系,这样 布隆过滤器 就能支持 删除 操作了
但这未免也太本末倒置了,位图 的优点是 高效且空间利用率高,如果给每一个 比特位 都挂上一个 引用计数器,会导致 位图 占用的内存资源膨胀,浪费很多不必要的空间,并且 删除 操作需求不大,没必要添加
3.5、测试
接下来测试一下 布隆过滤器 是否有用
void TestBloomFilter1()
{
BloomFilter<100> bf; //最大值为 100 的布隆过滤器
bf.set("aaaaa");
bf.set("bbbbb");
bf.set("ccccc");
bf.set("ddddd");
bf.set("eeeee");
std::cout << "bbbbb: " << bf.test("bbbbb") << std::endl;
std::cout << "ddddd: " << bf.test("ddddd") << std::endl;
std::cout << "============" << std::endl;
std::cout << "aaaa: " << bf.test("aaaa") << std::endl; //相似字符串
std::cout << "CCCCC: " << bf.test("CCCCC") << std::endl;
std::cout << "zzzzz: " << bf.test("zzzzz") << std::endl; //不相似字符串
std::cout << "wwwww: " << bf.test("wwwww") << std::endl;
}

可以正确进行判断,接下来看看 设置 的每个字符串的 哈希值 是多少

同时在三个 哈希值 的叠加下,误判 的概率被大大降低了,尽管如此,在判断字符串存在时,仍然存在较高的 误判率,可以通过下面的程序计算 误判率
测试方法:插入约 10 w 个字符串(原生),对原字符串进行微调后插入(近似),最后插入等量的完全不相同的字符串(不同),分别看看 原生 与 近似,原生 与 不同 字符串之间的误判率
void TestBloomFilter2()
{
//测试误判率
//构建一组字符串 + 一组相似字符串 + 一组完全不同字符串
//通过 test 测试误判率
const size_t N = 100000; //字符串数
std::string str = "https://blog.csdn.net/weixin_61437787?spm=1000.2115.3001.5343";
//构建原生基本的字符串
std::vector<std::string> vsStr(N);
for (size_t i = 0; i < N; i++)
{
std::string url = str + std::to_string(i);
vsStr[i] = url; //保存起来,后续要用
}
//构建相似的字符串
std::vector<std::string> vsSimilarStr(N);
BloomFilter<N> bfSimilarStr;
for (size_t i = 0; i < N; i++)
{
std::string url = str + std::to_string(i * -1);
vsSimilarStr[i] = url;
bfSimilarStr.set(url);
}
//构建完全不一样的字符串
str = "https://leetcode.cn/problemset/all/";
std::vector<std::string> vsDiffStr(N);
BloomFilter<N> bfDiffStr;
for (size_t i = 0; i < N; i++)
{
std::string url = str + std::to_string(i);
vsDiffStr[i] = url;
bfDiffStr.set(url);
}
//误判率检测:原生 <---> 近似
double missVal = 0;
for (auto e : vsStr)
{
if (bfSimilarStr.test(e) == true)
missVal++;
}
//误判率检测:原生 <---> 不同
double diffVal = 0;
for (auto e : vsStr)
{
if (bfDiffStr.test(e) == true)
diffVal++;
}
std::cout << "原生 <---> 近似 误判率:" << missVal / N * 100 << "%" << std::endl;
std::cout << "原生 <---> 不同 误判率:" << diffVal / N * 100 << "%" << std::endl;
}

显然,此时存在很高的误判率
3.6、优化方案
可以从两个方面进行优化:
- 增加哈希函数的个数(不是很推荐)
- 扩大布隆过滤器的长度,使数据更分散
因此我们可以控制 布隆过滤器 的长度,降低 误判率
如何理解空间扩大后,误判率会降低?
想想 地广人稀的西伯利亚 和 地狭人稠的香港,人口越稠密,找人时越有可能发生误判

那么如何选择 布隆过滤器 的长度,做到 平衡误判率与空间占用呢?
《详解布隆过滤器的原理,使用场景和注意事项》


经过计算得出,长度为 3~8 时,效果最好
- 实际位图的大小为
N * _len
对原来的 布隆过滤器 进行修改,结合 误判率 与 空间,选择较为折中的 6 作为 布隆过滤器 的长度
template<size_t N,
class K = std::string,
class Hash1 = BKDRHash,
class Hash2 = APHash,
class Hash3 = DJBHash>
class BloomFilter
{
static const int _len = 6; //布隆过滤器的长度
static const int _size = N * _len; //位图的大小
public:
void set(const K& key)
{
size_t HashI1 = Hash1()(key) % _size; //% N 是为了避免计算出的哈希值过大
_bits.set(HashI1);
size_t HashI2 = Hash2()(key) % _size;
_bits.set(HashI2);
size_t HashI3 = Hash3()(key) % _size;
_bits.set(HashI3);
}
bool test(const K& key)
{
//过滤不存在的情况,至于是否存在,还得进一步判断
size_t HashI1 = Hash1()(key) % _size;
if (_bits.test(HashI1) == false)
return false;
size_t HashI2 = Hash2()(key) % _size;
if (_bits.test(HashI2) == false)
return false;
size_t HashI3 = Hash3()(key) % _size;
if (_bits.test(HashI3) == false)
return false;
//经过层层过滤后,判断字符串可能存在
return true;
}
private:
Yohifo::bitset<_size> _bits; //位图结构
};
此时再来看看之前的测试:

误判率降至 5% 左右
对于 用户登录时检测昵称是否存在 这件事上,已经足够用了
如果想要最求更高的准度,可以使用 布隆过滤器 + 数据库 双重验证
4、布隆过滤器小结
总的来说,作为 哈希思想 的衍生品,布隆过滤器 实现了字符串的 快速查找与极致的空间利用,在需要判断字符串是否存在的场景中,判断 “不在”,是值得信赖的
优点:
- 查找效率极高,为
O(K),其中K表示哈希函数的个数 - 哈希函数之间并没有直接关系,方便进行硬件计算
- 数据量很大时,布隆过滤器可以表示全集
- 可以利用多个布隆过滤器进行字符串的 交集、并集、差集运算
- 在可以容忍误判率的场景中,布隆过滤器优于其他数据结构
- 布隆过滤器中存储的数据无法逆向复原,具有一定的安全性
缺点:
- 存在一定的误判性
- 无法对元素本身进行操作,仅能判断存在与否
- 一般不支持删除功能
- 采取计数删除的方案时,可能存在 计数回绕 的问题
实际应用场景:
- 注册时对于 昵称、用户名、手机号的验证
- 减少磁盘
IO或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求
总之,能被 布隆过滤器 拦截(过滤)下来的数据,一定是不存在的
5、海量数据面试题(哈希切割)
5.1、题目一
给两个文件,分别有
100亿个query,我们只有1 GB内存,如何找到两个文件交集?分别给出
精确算法和近似算法
query 指 查询语句,比如 网络请求、SQL 语句等,假设一个 query 语句占 50 Byte,单个文件中的 100 亿个 query 占 500 GB 的空间,两个文件就是 1000 GB
下面来看看解法
近似解法:借助布隆过滤器,先存储其中一个文件的 query 语句,这里给每个 query 语句分配 4 比特位,100 亿个就占约 1 GB 的内存,可以存下,存储完毕后,再从另一个文件读取 query 语句,判断是否在 布隆过滤器 中,“在” 的就是交集。因为 布隆过滤器 判断 “在” 不准确,符合题目要求的 近似算法
精确解法:对于这种海量数据,需要用到哈希分割,我们这里把单个文件(500 GB 数据)分割成 1000 个小文件,平均每个文件大小为 512 Mb,再将小文件读取到内存中;另一个文件也是如此,读取两个大文件中的小文件后,可以进行交集查找,再将所有小文件中的交集统计起来,就是题目所求的交集了

此时存在一个问题:如果我们是直接平均等分成 1000 个小文件的话,我们也不知道小文件中相似的 query 语句位置,是能把每个小文件都进行匹配对比,这样未免为太慢了
所以不能直接平均等分,需要使用 哈希分割 进行切分
i = HashFunc(query) % 1000
不同的 query 会得到不同的下标 i,这个下标 i 决定着这条 query 语句会被存入哪个小文件中,显然,一样的 query 语句计算出一样的下标,也就意味着它们会进入下标相同的小文件中,经过 哈希切割 后,只需要将 大文件 A 中的小文件 0 与 大文件 B 中的小文件 0 进行求 交集 的操作就行了,这样能大大提高效率

但是,此时存在一个 问题:如果因哈希值一致,而导致单个小文件很大呢?
此时如果小文件变成了 1GB、2GB、3GB 甚至更大,就无法被加载至内存中(算法还有消耗)
解决方法很简单:借助不同的哈希函数再分割
即使在同一个小文件中,不同的 query 语句经过不同的 哈希函数 计算后,仍可错开,怕的是 存在大量重复的 query,此时 哈希函数 就无法 分割 了,因为计算出的 哈希值 始终一致

所以面对小文件过大的问题,目前有两条路可选:
- 大多都是相同、重复的
query,无法分割,只能按照大小,放到其他小文件中 - 大多都是不相同的
query,可以使用 哈希函数 再分割
这两条路都很好走,关键在于如何选择?
小文件中实际的情况我们是无法感知的,但可以通过特殊手段得知:探测
对于大于 512 Mb 的小文件,我们可以对其进行读取,判断属于情况1、还是情况2
- 首先准备一个
unorder_set,目的很简单:去重 - 读取文件中的
query语句,存入unordered_set中 - 如果小文件读取结束后,没有发生异常情况,说明属于情况1:大多都是相同、重复的
query语句,把这些重复率高的数据打散,放置其他512 Mb的小文件中 - 如果小文件读取过程中,出现了一个异常,捕获结果为
bad_alloc,说明读取到的大多都是不重复的query语句,因为我们内存只有1 GB,抛出的异常是内存爆了,异常的抛出意味着这个小文件属于情况2,可以使用其他的 哈希函数 对其进行再分割,分成512 Mb的小文件
如此一来,这个文件就被解决了,核心在于:利用哈希切割将数据分为有特性的小文件、利用抛异常得知小文件的实际情况
5.2、题目二
给一个超过
100 GB大小的log file,log中存着IP地址, 设计算法找到出现次数最多的IP地址?
这题本质上也是在考 哈希分割,将 log file 文件中的 IP 地址看作上一题中的 query 语句,得知文件大小约为 500 GB
因为这里没有内存限制,我们可以将其分为 500 个小文件,每个小文件大小为 1 GB

这里分为小文件的目的是 让相同的 IP 分至同一个小文件中
针对较大的小文件,依然采取 其他哈希函数继续分割 或 分给其他小文件的做法
读取单个小文件时,利用 unordered_map 统计 IP 地址的出现次数,读取完毕后,遍历 unordered_map 即可得知出现次数最多的 IP 地址
与上题条件相同,如何找到
Top K的IP?如何直接用Linux系统命令实现?
涉及 Top K 的问题都可以通过 优先级队列(堆) 解决,在第一问的基础上,构建一个大小为 K 的 小堆,将高频出现的 IP 地址入堆,筛选出 Top K 个 IP 即可
至于如何利用 Linux 命令解决?
sort log_file | uniq -c | sort -nrk1,1 | head -K
解释:
-
sort log_file表示对log_file文件进行排序 -
uniq -c表示统计出其中每个IP的出现次数 -
sort -nrk1,1表示按照每个IP的出现次数再进行排序 -
head -k表示选择前k个IP地址显示
注意:以上操作都需要借助管道 | 因为它们都是有关联性的
🌆总结
以上就是本次关于 C++ 哈希的应用【布隆过滤器】的全部内容了,在本文中我们主要学习了布隆过滤器的相关知识,再一次对哈希思想有了更深层次的理解(多组映射),在简单模拟实现布隆过滤器之后,顺便解决了几道海量数据面试题,从中学到了哈希分割这一重要思想,哈希是一个被高频使用的工具,因为它实在是太香了,想要玩的更溜,还需要勤加练习

文章来源地址https://www.toymoban.com/news/detail-619252.html
相关文章推荐 文章来源:https://www.toymoban.com/news/detail-619252.html
C++ 进阶知识
C++ 哈希的应用【位图】
C++【哈希表的完善及封装】
C++【哈希表的模拟实现】
C++【初识哈希】
C++【一棵红黑树封装 set 和 map】
到了这里,关于C++ 哈希的应用【布隆过滤器】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[C++]哈希应用之位图&布隆过滤器](https://imgs.yssmx.com/Uploads/2024/04/852662-1.gif)