目录
1.Segment anything
2.补充图像分割和目标检测的区别
1.Segment anything
定义:图像分割通用大模型
延深:可以预计视觉检测大模型,也快了。
进一步理解:传统图像分割对于下图处理时,识别房子的是识别房子的模型,识别草的是识别草的模型,识别人的是识别人的模型,而Segment anything可一次识别所有物体。可以这样说以前我们的模型是训练得到几个,几十个,几千个标签,而Segment anything可以得到所有标签,

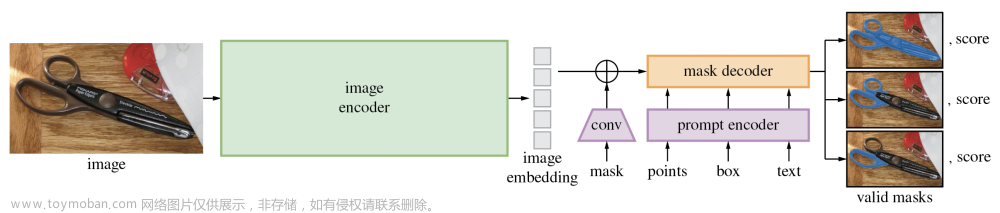
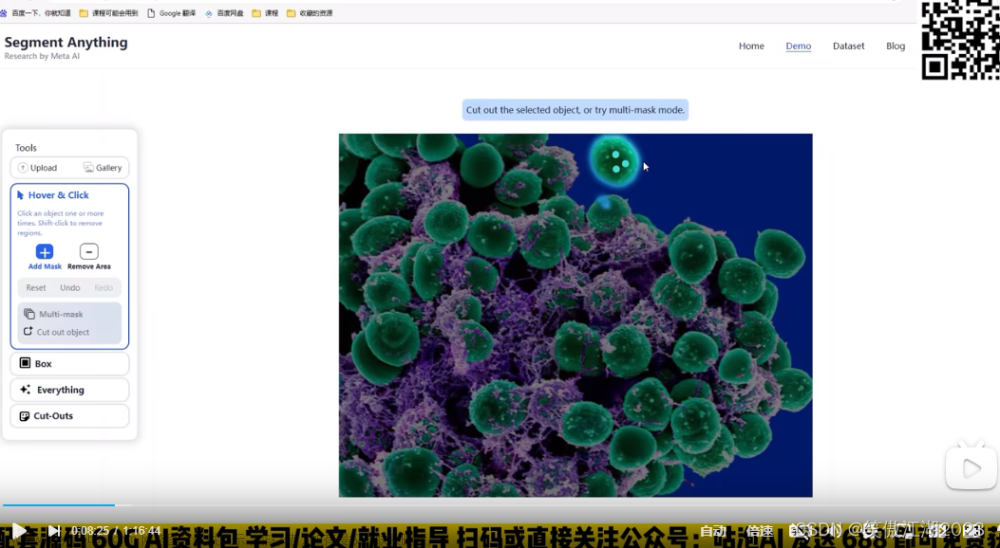
再进一步理解:chagpt在实现文本任务时我们发现,他同样是聚焦所有点,只需要几个提示词去引导它,对应下图,比方说,找到图中病毒或者找到图中蓝色区域。在 Segment anything同样是这个道理,我们对图中想要识别的对象,点三个点(提示词),模型便知道你想识别这个对象。也可以用一个框(提示词)对这个对象作为指导。通用大模型不用一次把所有东西都训练好,在有大模型后,有提示词,可以持续学习。
2.补充图像分割和目标检测的区别
定义:在这两个任务中,我们都希望找到图像中某些感兴趣的项目的位置,比如说图中人的位置。从输出理解两者区别:
1. 目标检测:预测包围盒(对于下面的狗只用框框起来即可)
YOLO,Fast-RCNN,似乎还有个SSD
输入:一个矩阵(输入图像),每个像素有 3 个值(红、绿、蓝),如果是黑色和白色,则每个像素有 1 个值。
输出:由左上角和大小定义的边框列表。
2. 图像分割:预测掩模(对下面的狗比方说,红色的狗,周边标注时要对每一个像素点标注,过于麻烦)
Mask RCNN,Unet,Segnet
输入:是一个矩阵(输入图像),每个像素有 3 个值(红、绿、蓝),如果是黑色和白色,则每个像素有 1 个值
输出:是一个矩阵(掩模图像),每个像素有一个包含指定类别的
结论:输出不同,从下图理解二者区别:简单理解目标检测在图中表现为框,图像分割是一种类别的颜色。

补充一下语义分割和实例分割:
语义分割:(图片分割)是对图像中的每一块像素都应该给出类别标签。
实例分割:(目标检测)只需要给出我们关注的物体的像素的类别标签。
结论:两者其实没有本质的区别。
参考文献
1.分割一切!刷爆CV圈子的视觉终极模型Segment Anything(SAM),唐宇迪博士两小时原理精讲、源码复现带你实操!_哔哩哔哩_bilibili
2.图像分割与目标检测与区别_图像分割和目标检测区别_必修居士的博客-CSDN博客文章来源:https://www.toymoban.com/news/detail-619393.html
3.计算机视觉:图像检测和图像分割有什么区别?_图像识别与分割_喜欢打酱油的老鸟的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-619393.html
到了这里,关于Segment anything(图片分割大模型)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!