HDFS异构存储类型
- 冷,热,温,冻数据
- 通常,公司或者组织总是有相当多的历史数据占用昂贵的粗处空间。典型的数据使用模式是新传入的数据被应用程序大量使用,从而该数据被标记为“热”数据。随着时间的推移,存储的数据每周被访问几次,而不是一天几次,这是认为其是“暖”数据。在接下来的几周和几个月中,数据使用率下降的更多,成为“冷”数据,。如果很少使用数据,例如每年查询一次或两次,这是甚至可以根据其年龄创建第四个数据风雷,并将这组很少被铲讯的旧数据被称为“冻结数据”
- Hadoop允许将不是热数据或者活跃数据的数据分配到比较便宜的存储上,用于归档或冷存储。可以设置存储策略,将较旧的数据从昂贵的高性能存储上转移到性价比较低(较便宜)的存储设备上。
- Hadoop2.5及以上版本都支持存储策略,在该策略下,不仅可以在默认的传统磁盘上存储hdfs数据,还可以在SSD(固态硬盘)上存储数据。
什么是异构存储
异构存储是Hadoop2.6.0版本出现的新特性,可以根据各个存储介质读写特性不同进行选择。
例如冷热数据的存储,对冷数据采取容量大,读写性能不高的存储介质如机械硬盘,对于热数据,可使用SSD硬盘存储。
异构存储类型
RAM_DISK(内存)
SSD(固态硬盘)
DISK(机械硬盘)默认使用
ARCHIVE(高密度存储介质,存储档案历史数据)
如何让HDFS知道集群中的数据存储目录是那种类型存储介质
- 配置属性时主动声明。 HDFS并没有自动检测的能力
- 配置参数dfs.datanode.data.dir = [SSD] file:///grid/dn/ssd0
- 如果目录前没有带上[SSD][DISK][ARCHIVE][RAM_DISK]这4种类型中的任何一种,则默认时DISK类型。
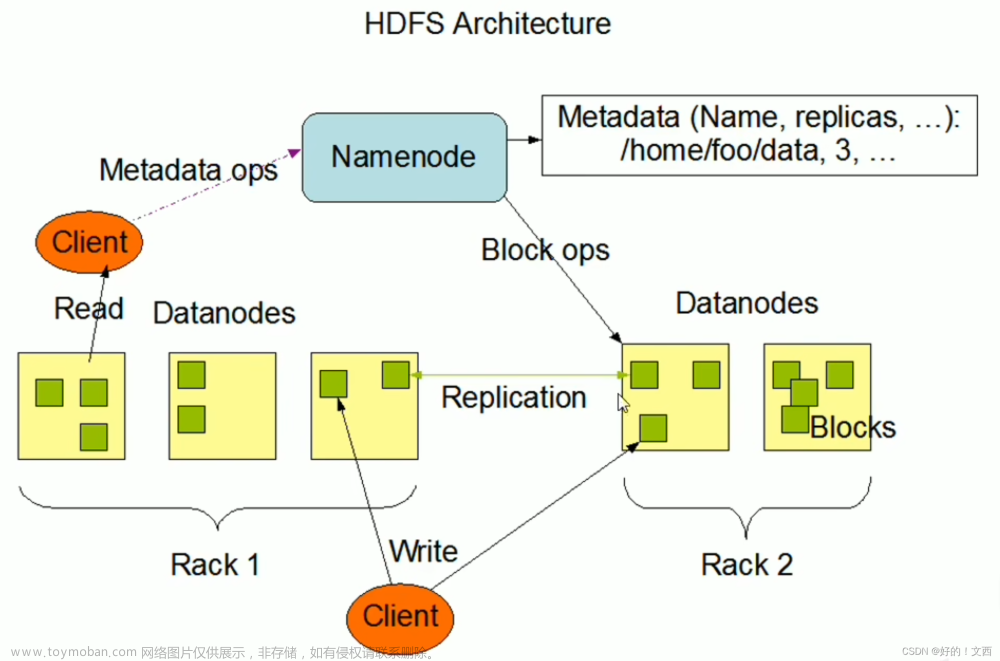
块存储选择策略
- 块存储指的是对HDFS文件的数据块副本存储
- 对于数据的存储介质,HDFS的BlockStoragePolicySuite类内部定义了6种策略
HOT(默认策略)
COLD
WARM
ALL_SSD
ONE_SSE
LAZY_PERSIST - 前三种根据冷热数据区分,后三种根据磁盘性质区分

选择策略说明
- HOT:用于存储和计算。流行且仍用于处理的数据保留在此策略中。所有副本都存储在DISK中。
- COLD:仅适用于计算量中有限的存储。不再使用的数据或需要归档的数据从热存储移动到冷存储。所有副本都存储在ARCHIVE中。
- WRAM:部分热和部分冷。热时,其某些副本存储在DISK中。其余副本存储在ARCHIVE中。
- ALL_SSD:将所有副本存储在SSD中
- one_SSD:用于将副本之一存储在SSD中。其余副本存储在DISK中。
- Lazy_Persist:用于在内存中写入具有单个副本的块。首先将副本写入RAM_DISK,然后将其延迟保存到DISK中

选择策略的命令
- 列出所有存储策略
hdfs storagepolicies -listPolicies

- 设置存储策略
hdfs storagepolicies -setStoragePolicy -path-policy

- 取消存储策略
hdfs storagepolicies -unsetStoragePolicy -Path
在执行unset命令之后,将应用当前目录最近的祖先存储策略,如果没有任何祖先的策略,则将应用默认的存储策略 - 获取存储策略
hdfs storagepolicies -getStoragePolicy -path
案例:冷热温数据异构存储
为了更加充分的利用存储资源,我们可以将数据分为冷,热,温三个阶段来存储。具体规划如下:
对应步骤
- step1:配置DataNode存储目录,指定存储介质类型(hdfs-site.xml)

- step2:重启HDFS集群,验证配置

- step3:创建测试目录
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/hot
hdfs dfs -mkdir -p /data/hdfs_test/data_phase/warm
hdfs dfs -mkdir -p /data/hdfs_test/data_phase/cold

- step4:分别设置三个目录的存储策略
hdfs storagepolicies -setStoragePolicy - path /data/hdfs-test/data_phase/hot -policy HOT
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/warn -policy WARN
hdfs storagepolicies -setStoragePolicy -path /data/hdfs -test/data_phase/cold -policy COLD
- step5:查看三个目录的存储策略
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data-phase/hot
hdfs sotragepolicies -getStoragePolicy -path /data/hdfs-test/data-phase/warm
hdfs soragepolicies -getStoragePolidy -path /data/hdfs-test/data-phase/cold
- step6:上传文件测试异构存储
hdfs dfs -put /etc/profile/data/hdfs-test/data_phase/hot
hdfs dfs -put /etc/profile/data/hdfs-test/data_phase/warm
hdfs dfs -put /etc/profile/data/hdfs-test/data_phase/ cold
- step7:查看不同存储策略文件的block位置
hdfs fsck /data/hdfs-test/data_phase/hot/profile -files -blocks -locations

HDFS内存存储策略支持-- LAZY PERSIST
介绍
- HDFS支持把数据写入由DataNode管理的对外内存
- DataNode异步地将内存中数据刷新到磁盘,从而减少代价较高的磁盘IO操作,这种写入被称为Lazy Persist写入
- 该特性从Apache Hadoop 2.6.0开始支持

执行
- 对目标文件目录设置StoragePolicy为LAZY_PERSIST的内存存储策略
- 客户端进程向NameNode发起创建/写入文件
- 客户端请求到具体的DataNode后DataNode会把这些数据块回写入RAM内存中,同时启动异步线程服务将内存数据持久化写到磁盘上。
- 内部的异步持久化存储是指数据不是马上落盘,而是懒惰的,延时的尽心处理
使用
- step1:虚拟内存盘配置
mount -t tmpfs -o size=1g tmpfs /mnt/dn-tmpfs/
将tmpfs挂载到目录/mnt/dn-tmpfs/,并且限制内存使用大小为1GB
-
step2:内存存储介质设置
将机器中已经完成好的虚拟内存盘配置到dfs.datanode.data.dir中,其次还要带上RAM_DISK标签
-
step3:参数设置优化
dfs.storage.policy.enabled
是否开启异构存储,默认true开启
dfs.datanode.max. locked.memory
用于在数据节点上的内存中缓存副本的内存量(以字节为单位)。默认情况下,此参数设置为0,这将禁用内存中缓存。内存值过小会导致内存中的总的可存储的数据块变小,但如果超过DataNode能承受的最大内存大小的话,部分内存块会被直接移出。文章来源:https://www.toymoban.com/news/detail-619720.html -
step4:在目录上设置存储策略文章来源地址https://www.toymoban.com/news/detail-619720.html
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST
到了这里,关于HDFS异构存储详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![【Hadoop】-HDFS的存储原理[4]](https://imgs.yssmx.com/Uploads/2024/04/858768-1.png)