重新学习了一下,整理了一下笔记
论文:《Attention Is All You Need》
代码:http://nlp.seas.harvard.edu/annotated-transformer/
地址:https://arxiv.org/abs/1706.03762v5
翻译:Transformer论文翻译
特点:
- 提出一种不使用 RNN、CNN,仅使用注意力机制的新模型 Transformer;
- 只关注句内各 token 之间的关系;
- 使用矩阵计算长程token之间的关联,提升注意力的计算效率;
- 使用位置嵌入,为不同位置的token赋予不同的含义。
核心贡献:
- Self-Attention
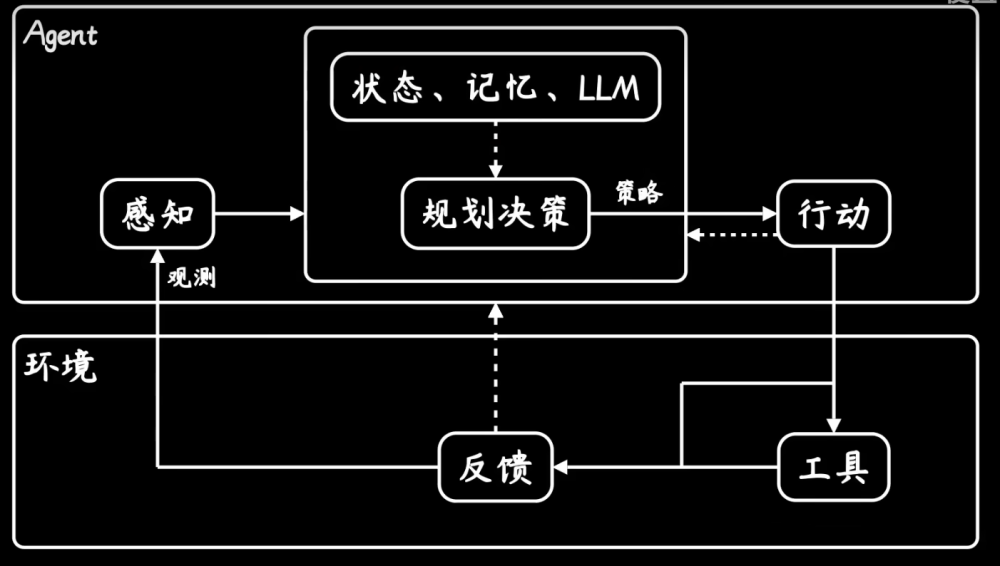
Transformer 的基本结构

如图,其结构主要分为 Encoder 与 Decoder 两部分,基本单元是 Multi-Head Attention、Layer Norm、Residual Connect、Feed Forward Network,其中 Decoder 每一子块的输入处还有一个 Masked Multi-Head Attention。
Encoder 的输出会被送到 Decoder 的每一个子块中。
Self-Attention

Self-Attention ( K , Q , V ) = softmax ( Q K T d ) V \text{Self-Attention}(K,Q,V)=\text{softmax}(\frac{QK^T}{\sqrt{d}})V Self-Attention(K,Q,V)=softmax(dQKT)V
- 上图 左侧是 Self-Attention 的计算流程;
- 从计算图以及共识来看,Self-Attention 是被 d \sqrt{d} d Scaled 过的,原因是:该因子可以抑制 Q K T QK^T QKT 中过大的值,以防止梯度消失现象的出现;
- softmax 负责计算概率化的注意力分布,该分布负责在 V 中选择与 Qi 关联度较高的 values;
- Q K T QK^T QKT 的目的是利用矩阵运算一次性计算出每个 Q i Q_i Qi 与所有 keys 的点积,同理,后面也一次性地为每个 Q i Q_i Qi 筛选出相应的 values。这种方法优点是 Self-Attention 可以无视句中 token 之间的距离,以此获得更高的性能,缺点是计算量庞大;
- 上图 右侧是 Multi-Head Self-Attention 的计算流程,原因是:Multi-Head 增加了特征子空间的数量,使模型能够获取更加丰富的语义信息;
- 文本信息是有先后顺序的,为了防止 Decoder 在处理 LLM 任务时出现信息向“历史”方向传播的现象,需要对一些与 illegal 连接关联的 values 采用 mask out 的操作,即屏蔽掉(设置为 − ∞ -\infin −∞),即只能用前面的token预测后面的token,不能反过来。
Self-Attention 的一个缺点及修补方式
缺点:点积运算无法对序列中 token 出现的位置进行建模,这样会导致模型无法充分地利用数据上下文中所蕴含的丰富的语义信息。
解决方式:引入位置嵌入(Position Embedding、Position Encoding)
P
E
p
o
s
,
2
i
=
sin
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
P
E
p
o
s
,
2
i
+
1
=
cos
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{pos,2i}=\sin(pos/10000^{2i/d_{model}})\\ PE_{pos,2i+1}=\cos(pos/10000^{2i/d_{model}})
PEpos,2i=sin(pos/100002i/dmodel)PEpos,2i+1=cos(pos/100002i/dmodel)
使用三角函数的原因:模型借此可为每个token获取相对位置信息(对任意偏移量 k k k, P E p o s + k PE_{pos+k} PEpos+k 都可以作为 P E p o s PE_{pos} PEpos 的线性函数),此外它还可以把模型外推到比训练中最长的序列更长的序列中去。文章来源:https://www.toymoban.com/news/detail-619924.html
Self-Attention 的复杂度: 文章来源地址https://www.toymoban.com/news/detail-619924.html
文章来源地址https://www.toymoban.com/news/detail-619924.html
到了这里,关于Transformer 论文学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!