Self-supervised Learning Framework

不用标注数据就能学习的任务,比如Bert之类的。但最早的方法是Auto-encoder。
Outline

Auto-encoder

encoder输出的向量,被decoder还原的图片,让输出的图片与输入的图片越接近越好。
将原始的高维向量变成低维向量,将该新的特征用于下游任务。
相关的类似方法:
- PCA: youtu.be/iwh5o_M4BNU
- t-SNE: youtu.be/GBUEjkpoxXc

图片的变化是有限的:
- 3x3的图,可能只需要用两个维度表示就行


auto-encoder 不是一个新的想法, 2006年提出。


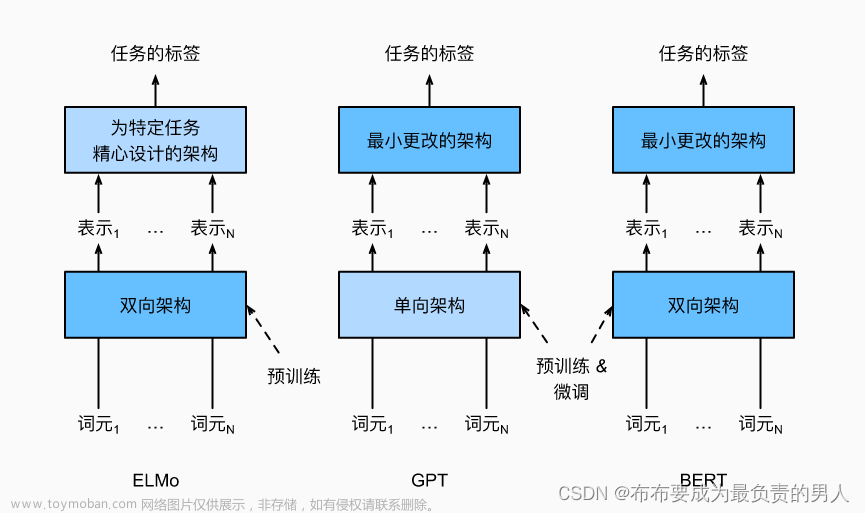
Bert也是一个加噪声的auto-encoder
Feature Disentanglement

Disentanglement 把纠缠的特征解开。


embedding的哪些维度代表了哪些信息。比如前50维表示内容信息,后50维表示说话人的信息。
应用变身器。
在过去需要读相同的句子才能进行转换,现在只需要给声音就行,不需要同样的内容就可以进行声音转换。




不同语种都可以,只是分拆内容和说话人特征然后再混合decoder输出
Discrete Represention

binary的好处,每一个维度表示这个地方特征是否存在,便于解释embedding。
如果是one-hot的话,可以做到无监督分类。
codebook一排向量,然后用中间算出的embedding与这一排向量算相似度,谁的相似度最大就把那个向量拿出来,然后丢到decoder中。

文字中的embedding用字符串表示,是不是就是摘要那?模型是seq2seq。
这样生成的中间内容不懂,是暗号类的那种文章,此时借鉴于GAN的思想,加一个鉴别器:
用RL硬训练,有点像cycleGAN

更多应用

生成

压缩
 文章来源:https://www.toymoban.com/news/detail-619983.html
文章来源:https://www.toymoban.com/news/detail-619983.html
异常检测



cancer细胞检测,就一类,可以使用auto-encoder算法。
使用真实人脸训练encoder-decoder,得到正常的输出
然后用假脸送进去预测,得到的重构的图比较差,说明这种人脸是模型训练没有看过的。
更多异常检测的介绍资料: 文章来源地址https://www.toymoban.com/news/detail-619983.html
文章来源地址https://www.toymoban.com/news/detail-619983.html
到了这里,关于机器学习:自动编码器Auto-encoder的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!