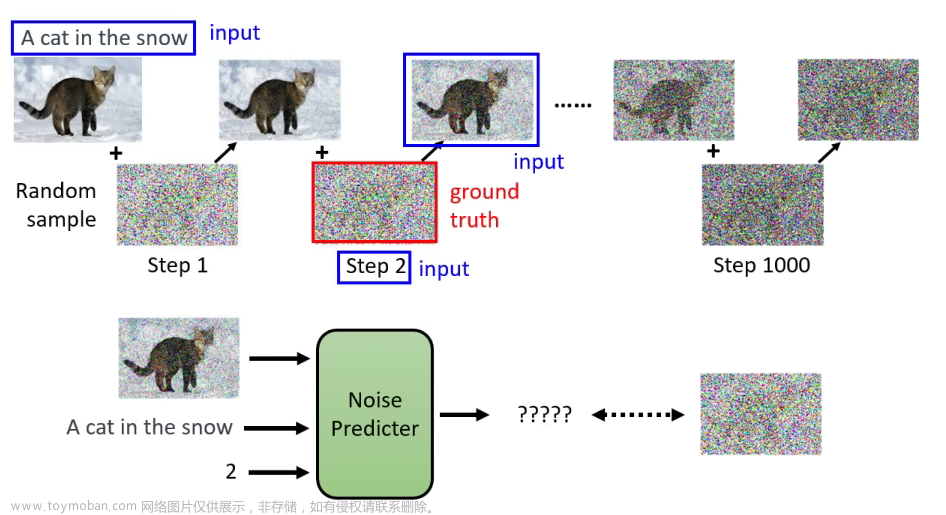
Stable Diffusion是一种基于神经网络的技术,通过输入提示词来生成相应的图片。为了获得高质量的图片输出,您需要选择合适的提示词,并确保它们能够激发模型的想象力和创造力。
以下是一些编写提示词的建议:
- 确定主题:首先,确定您希望生成的图片的主题或内容。例如,您可以选择自然风光、抽象艺术、科幻场景等。明确主题有助于引导模型生成与主题相关的内容。
- 使用简洁明了的语言:尽量使用简单、清晰的语言描述您的需求。避免使用过于复杂或模糊的词汇,以免引起困惑。
- 提供足够的细节:为模型提供足够的细节信息,以便它能够准确地理解您的要求。例如,如果您希望生成一幅描绘夜晚星空的图片,可以描述星星的数量、颜色和分布等。
- 利用形容词和副词:使用形容词和副词可以帮助模型更具体地理解您的想法。例如,您可以描述“明亮的星星”、“闪烁的流星”等。
- 避免限制性的词汇:尽量避免使用限制性的词汇,如“必须”、“只能”等。这可能会限制模型的想象力和创造力。相反,尝试使用开放性的问题,如“请想象一下…”。
- 使用示例:为了帮助模型更好地理解您的需求,可以提供一些实际的例子或样例图片作为参考。这样可以让模型更容易地抓住关键点,并生成符合预期的图片。
文字转图片
请先通过前文 [调参基础] 了解 SD-WebUI 网页应用提供的基本参数。
以下内容来源网络整理
如何书写提示词
这是一个通用的指南,内容是基本通用的,可能有例外情况,请读对应的章节了解不同应用的特性。
TIP
提示词是提示而不是判定依据,比如你输入质量判定词汇的时候,其实是在限制数据的范围,而不是 “要求” AI 出一张很好的图片。
单词标签
对于在标签单词上特化训练的模型,建议使用逗号隔开的单词作为提示词。
普通常见的单词,例如是可以在数据集来源站点找到的著名标签(比如 Danbooru)。单词的风格要和图像的整体风格搭配,否则会出现混杂的风格或噪点。
避免出现拼写错误。NLP 模型可能将拼写错误的单词拆分为字母处理。
自然语言
对于在自然语言上特化训练的模型,建议使用描述物体的句子作为提示词。
取决于训练时使用的数据集,可以使用英文,日文,特殊符号或一些中文。大多数情况下英文较为有效。
避免 with 之类的连接词或复杂的语法,大多数情况下 NLP 模型只会进行最简单的处理。
避免使用重音符(如 é 和 è)和德语 umlauts(如 ä 和 ö),它们可能无法被映射到正确的语义中。
不建议随意套用现成模板,尤其是无法经过人类理解的模板。
颜文字
对于使用 Danbooru 数据的模型来说,可以使用颜文字在一定程度上控制出图的表情。
例如:
:-) 微笑 :-( 不悦 ;-) 使眼色 :-D 开心 :-P 吐舌头 :-C 很悲伤 :-O 惊讶 张大口 :-/ 怀疑
空格
逗号前后的少量空格并不影响实际效果。
开头和结尾的额外空格会被直接丢弃。词与词之间的额外空格也会被丢弃。
标点符号
用逗号、句号、甚至是空字符(\0)来分隔关键词,可以提高图像质量。目前还不清楚哪种类型的标点符号或哪种组合效果最好。当有疑问时,只要以一种使提示更容易被阅读的方式来做。
对于部分模型,建议将下划线(_)转换为空格。
艺术风格词
可以通过指定风格关键词来创作带有特效或指定画风的图片。
运动和姿势
如果没有很大要求的话,选择只与少数姿势相关的提示。
这里的姿势是指某一事物的物理配置:图像主体相对于摄像机的位置和旋转,人类/机器人关节的角度,果冻块被压缩的方式,等等。你试图指定的事物中的差异越小,模型就越容易学习。
因为运动就其定义而言涉及到主体姿势的巨大变化,与运动相关的提示经常导致身体的扭曲,如重复的四肢。另外,因为人类的四肢,特别是人类的手和脚有很多关节,他们可以采取许多不同的、复杂的姿势。这使得他们的可视化特别难学,对于人类和神经网络都是如此。
简而言之:人类站着/坐着的好形象很容易,人类跳着/跑着的好形象很难。
如何写?
模板
先想一下要画什么,例如 主题,外表,情绪,衣服,姿势,背景 一类,然后参考数据集标签表(如果有的话,比如 Danbooru, Pixiv 等)。
然后将想要的相似的提示词组合在一起,请使用英文半角 , 做分隔符,并将这些按从最重要到最不重要的顺序排列。
一种模板示例如下:
(quality), (subject)(style), (action/scene), (artist), (filters)
-
(quality)代表画面的品质,比如low res结合sticker使用来 “利用” 更多数据集,1girl结合high quality使用来获得高质量图像。 -
(subject)代表画面的主题,锚定画面内容,这是任何提示的基本组成部分。 -
(style)是画面风格,可选。 -
(action/scene)代表动作/场景,描述了主体在哪里做了什么。 -
(artist)代表艺术家名字或者出品公司名字。 -
(filters)代表一些细节,补充。可以使用 艺术家,工作室,摄影术语,角色名字,风格,特效等等。
大小写
CLIP 的标记器在标记之前将所有单词转为小写。其他模型,如 BERT 和 T5,将大写的单词与非大写的单词区别对待。
但避免涉及特殊语法,以防被解释为其他语义,例如 AND。
词汇顺序
似乎 VAE 使用了一种称为贝叶斯定理的统计方法。在计算标记的去向时,前几个单词似乎锚定了其余单词标记在潜在空间中的分布。
早期的标记具有更一致的位置,因此神经网络更容易预测它们的相关性。在贝叶斯推理中,矩阵中的第一个标记或证据很重要,因为它设置了初始概率条件。但是后面的元素只是修改了概率条件。因此,至少在理论上,最后的令牌不应该比前面的令牌具有更大的影响。
但是解析器理解事物的方式是不透明的,因此没有办法确切地知道词法顺序是否具有“锚”效应。
提示词长度
避免过长的提示词。
提示词放入的顺序就是优先级。由于提示词的权重值从前向后递减,放置在特别靠后的提示词已经对图片的实际生成影响甚微。
不堆叠提示词是一个好习惯,但是如果你确实有很多内容要写,可以适当提高生成步数,以便在生成过程中更好地利用提示词。
SD-WebUI 突破最多 75 个词组限制的方式是将每 20 + 55 个词分为一组。选项 Increase coherency by padding from the last comma within n tokens when using more than 75 tokens 让程序试图通过查找最后 N 个标记中是否有最后一个逗号来缓解这种情况,如果有,则将所有经过该逗号的内容一起移动到下一个集合中。该策略可适当缓解提示词过多无法处理的问题,但可能破坏提示词之间的权重关系。
除了 WebUI 对此情况进行了特殊处理外,由于 GPT-3 模型限制,提示词处理空间并不是无限的,大多在在 75-80 之间,75 字符后的内容会被截断。
特异性
问题体现在语义偏移上。对于神经网络的训练来说,特征的质量很重要:输入和输出之间的联系越强,神经网络就越容易学习这种联系。
换句话说,如果一个关键词有非常具体的含义,那么学习它与图像之间的联系要比一个关键词有非常广泛的含义容易得多。
这样一来,即使是像 “Zettai Ryouiki” 这样很少使用的关键词也能产生非常好的结果,因为它只在非常具体的情况下使用。另一方面,“动漫” 即使是一个比较常见的词,也不会产生很好的结果,这可能是因为它被用于许多不同的情况,即使是没有字面意思的动漫。如果你想控制你的图片的内容,选择具体的关键词尤其重要。另外:你的措辞越不抽象越好。如果可能的话,避免留下解释空间的措辞,或需要 “理解” 不属于图像的东西。甚至像 “大” 或 “小” 这样的概念也是有问题的,因为它们与物体离相机近或远是无法区分的。理想情况下,使用有很大可能逐字出现在你想要的图像标题上的措辞。
语义失衡
每一个提示词就像染料一样,它们的 “亲和性“ 不同,如果更常见的提示词,比如 loli (和其他提示词并列放置)的影响就大于其他提示词。
比如,如果你想生成动漫图片,使用了 星空 startrail 标签,相比你期望出现的动漫星空,会有更多来自真实照片的星空元素。
许多词汇在基准上的权重就不一样,所以要根据效果进行合理调节。
否定提示词
SD-WebUI 网页应用会在生成时 避免生成否定提示词提及的内容。
否定提示是一种使用 Stable-Diffusion 的方式,允许用户指定他不想看到的内容,而不对模型本身做额外的要求。
通过指定 unconditional_conditioning 参数,在生成中采样器会查看去噪后符合提示的图像(城堡)和去噪后看起来符合负面提示的图像(颗粒状、雾状)之间的差异,并尝试将最终结果远离否定提示词。
权重系数
权重系数可改变提示词特定部分的比重。
更多资料详见 Wiki:Attention Emphasis
对于 SD-WebUI,具体规则如下:
-
(word)- 将权重提高 1.1 倍 -
((word))- 将权重提高 1.21 倍(= 1.1 * 1.1),乘法的关系。 -
[word]- 将权重降低 90.91% -
(word:1.5)- 将权重提高 1.5 倍 -
(word:0.25)- 将权重减少为原先的 25% -
\(word\)- 在提示词中使用字面意义上的 () 字符
使用数字指定权重时,必须使用 () 括号。如果未指定数字权重,则假定为 1.1。指定单个权重仅适用于 SD-WebUI。
无论使用何种具体的脚本,重复某个关键词似乎都会增加其效果。文章来源:https://www.toymoban.com/news/detail-620172.html
值得注意的是,你的提示中存在越多的提示词,任何单一提示词的影响就越小。你还会注意到,由于这个原因,在增加新的提示词时,风格会逐渐消失。强烈建议随着提示符长度的增加改变风格词的强度,以便保持一致的风格。文章来源地址https://www.toymoban.com/news/detail-620172.html
扩展阅读 来源网络
- 有用的电影术语
- 镜头类型
- 电视术语
- 摄影类型
- 摄影术语
- 极限运动
- 构图艺术
到了这里,关于Stable Diffusion 文字生成图片如何写提示词的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!