一、强化学习之Q-learning算法
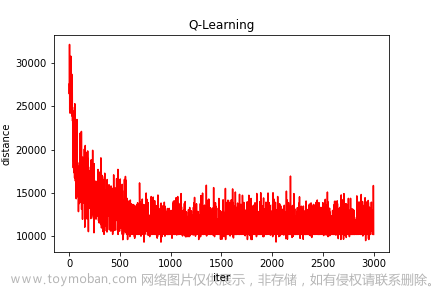
Q-learning算法是强化学习算法中的一种,该算法主要包含:Agent、状态、动作、环境、回报和惩罚。Q-learning算法通过机器人与环境不断地交换信息,来实现自我学习。Q-learning算法中的Q表是机器人与环境交互后的结果,因此在Q-learning算法中更新Q表就是机器人与环境的交互过程。机器人在当前状态s(t)下,选择动作a,通过环境的作用,形成新的状态s(t+1),并产生回报或惩罚r(t+1),通过式(1)更新Q表后,若Q(s,a)值变小,则表明机器人处于当前位置时选择该动作不是最优的,当下次机器人再次处于该位置或状态时,机器人能够避免再次选择该动作action. 重复相同的步骤,机器人与环境之间不停地交互,就会获得到大量的数据,直至Q表收敛。QL算法使用得到的数据去修正自己的动作策略,然后继续同环境进行交互,进而获得新的数据并且使用该数据再次改良它的策略,在多次迭代后,Agent最终会获得最优动作。在一个时间步结束后,根据上个时间步的信息和产生的新信息更新Q表格,Q(s,a)更新方式如式(1):

式中:st为当前状态;r(t+1)为状态st的及时回报;a为状态st的动作空间;α为学习速率,α∈[0,1];γ为折扣速率,γ∈[0,1]。当α=0时,表明机器人只向过去状态学习,当α=1时,表明机器人只能学习接收到的信息。当γ=1时,机器人可以学习未来所有的奖励,当γ=0时,机器人只能接受当前的及时回报。
每个状态的最优动作通过式(2)产生:

Q-learning算法的搜索方向为上下左右四个方向,如下图所示:

Q-learning算法基本原理参考文献:
[1]王付宇,张康,谢昊轩等.基于改进Q-learning算法的移动机器人路径优化[J].系统工程,2022,40(04):100-109.
二、Q-learning算法求解机器人路径优化
部分代码:提供参考地图,地图数值可以修改(地图中0代表障碍物,50代表通道 ,70代表起点 ,100代表终点),最大训练次数等参数可根据自己需要修改。
close all
clear
clc
global maze2D;
global tempMaze2D;
NUM_ITERATIONS =700; % 最大训练次数(可以修改)
DISPLAY_FLAG = 0; % 是否显示(1 显示; 0 不显示)注意:设置为0运行速度更快
CurrentDirection = 4; % 当前机器人的朝向(1-4具体指向如下)
% 1 - means robot facing up
% 2 - means robot facing left
% 3 - means robot facing right
% 4 - means robot facing down
maze2D=xlsread('10x10.xlsx');%%导入地图(提供5个地图,可以修改) maze2D中 0代表障碍物 50代表通道 70代表起点 100代表终点
[startX,startY]=find(maze2D==70);%获取起点
[goalX,goalY] = find(maze2D==100);%获取终点
orgMaze2D = maze2D;
tempMaze2D = orgMaze2D;
CorlorStr='jet';地图中绿色为通道,蓝色为障碍物,红线为得到的路径,起始点均标注。
(1)第一次结果
机器人最终路径:
49 1
48 1
47 1
47 2
47 3
48 3
48 4
48 5
48 6
48 7
48 8
47 8
47 9
47 10
46 10
45 10
45 11
45 12
44 12
43 12
42 12
42 13
42 14
42 15
42 16
42 17
42 18
42 19
41 19
41 20
41 21
41 22
40 22
40 23
40 24
40 25
39 25
38 25
37 25
36 25
35 25
34 25
34 24
33 24
32 24
31 24
30 24
30 25
29 25
28 25
28 24
27 24
26 24
25 24
24 24
24 25
24 26
24 27
23 27
22 27
21 27
21 28
21 29
21 30
22 30
22 31
22 32
22 33
22 34
21 34
21 35
21 36
20 36
19 36
18 36
17 36
16 36
15 36
15 37
15 38
14 38
14 39
14 40
14 41
13 41
12 41
11 41
10 41
9 41
8 41
8 40
7 40
6 40
5 40
4 40
4 41
4 42
4 43
3 43
2 43
1 43
1 44
1 45
1 46
1 47
2 47
2 48
1 48
机器人最终路径长度为 107
机器人在最终路径下的转向及移动次数为 189


(2)第二次结果
机器人最终路径:
49 1
48 1
47 1
47 2
46 2
45 2
44 2
44 3
44 4
43 4
42 4
42 5
42 6
42 7
42 8
42 9
42 10
41 10
41 11
41 12
42 12
42 13
42 14
42 15
42 16
42 17
42 18
42 19
41 19
41 20
41 21
41 22
40 22
40 23
40 24
40 25
39 25
38 25
37 25
36 25
35 25
34 25
34 24
33 24
32 24
31 24
30 24
30 25
29 25
28 25
28 24
27 24
26 24
25 24
24 24
24 25
24 26
24 27
23 27
22 27
21 27
21 28
21 29
21 30
22 30
22 31
22 32
22 33
22 34
21 34
21 35
21 36
20 36
19 36
19 37
18 37
18 38
17 38
16 38
15 38
14 38
14 39
14 40
14 41
13 41
12 41
11 41
10 41
9 41
8 41
8 40
7 40
6 40
5 40
4 40
4 41
4 42
4 43
3 43
2 43
1 43
1 44
1 45
1 46
1 47
1 48
机器人最终路径长度为 105
机器人在最终路径下的转向及移动次数为 186


(3)第三次结果
机器人最终路径:
49 1
48 1
47 1
47 2
47 3
48 3
48 4
48 5
48 6
48 7
48 8
47 8
47 9
47 10
46 10
45 10
45 11
44 11
44 12
43 12
42 12
42 13
42 14
42 15
42 16
42 17
42 18
42 19
41 19
41 20
41 21
41 22
40 22
40 23
40 24
40 25
39 25
38 25
37 25
36 25
35 25
34 25
34 24
33 24
32 24
31 24
30 24
30 25
29 25
28 25
28 24
27 24
26 24
25 24
24 24
24 25
24 26
24 27
23 27
22 27
21 27
21 28
21 29
21 30
22 30
22 31
22 32
22 33
22 34
21 34
21 35
21 36
20 36
19 36
19 37
18 37
18 38
17 38
16 38
15 38
14 38
14 39
14 40
14 41
13 41
12 41
11 41
10 41
9 41
8 41
8 40
7 40
6 40
5 40
4 40
4 41
4 42
4 43
3 43
2 43
1 43
1 44
1 45
1 46
2 46
2 47
1 47
1 48
机器人最终路径长度为 107
机器人在最终路径下的转向及移动次数为 200

 文章来源:https://www.toymoban.com/news/detail-620679.html
文章来源:https://www.toymoban.com/news/detail-620679.html
三、完整MATLAB代码
 文章来源地址https://www.toymoban.com/news/detail-620679.html
文章来源地址https://www.toymoban.com/news/detail-620679.html
到了这里,关于强化学习路径优化:基于Q-learning算法的机器人路径优化(MATLAB)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![强化学习基础篇[2]:SARSA、Q-learning算法简介、应用举例、优缺点分析](https://imgs.yssmx.com/Uploads/2024/02/468458-1.jpeg)





