前言
第一次接触OpenMV也是第一次将理论用于实践,是老师让我实现的一个小测验,这几天完成后决定写下完整的过程。本文主要是当缝合怪,借鉴和参考了其他人的代码再根据我个人设备进行了一定的调整,此外还包括了我自身实践过程中的一些小意外。
!!!一定要根据个人器件型号和个人设备来参考
一、数字识别的模型训练
1.下载训练集
研究期间,我发现大部分人以及官网教程采用的都是自己拍摄照片再进行网络训练,存在的缺陷就是数据集较小不全面、操作繁琐。个人认为如果是对标准的数字进行识别,自己手动拍取照片进行识别足够了。但想要应用于更广泛的情况,应该寻找更大的数据集,所以我找到了国外手写数字的数据集MNIST。建议四个文件都下载
数据链接:MINIST数据集
2.对数据进行调整
2.1 将ubyte格式转为jpg格式
代码参考链接:python将ubyte格式的MNIST数据集转成jpg图片格式并保存
import numpy as np
import cv2
import os
import struct
def trans(image, label, save):#image位置,label位置和转换后的数据保存位置
if 'train' in os.path.basename(image):
prefix = 'train'
else:
prefix = 'test'
labelIndex = 0
imageIndex = 0
i = 0
lbdata = open(label, 'rb').read()
magic, nums = struct.unpack_from(">II", lbdata, labelIndex)
labelIndex += struct.calcsize('>II')
imgdata = open(image, "rb").read()
magic, nums, numRows, numColumns = struct.unpack_from('>IIII', imgdata, imageIndex)
imageIndex += struct.calcsize('>IIII')
for i in range(nums):
label = struct.unpack_from('>B', lbdata, labelIndex)[0]
labelIndex += struct.calcsize('>B')
im = struct.unpack_from('>784B', imgdata, imageIndex)
imageIndex += struct.calcsize('>784B')
im = np.array(im, dtype='uint8')
img = im.reshape(28, 28)
save_name = os.path.join(save, '{}_{}_{}.jpg'.format(prefix, i, label))
cv2.imwrite(save_name, img)
if __name__ == '__main__':
#需要更改的文件路径!!!!!!
#此处是原始数据集位置
train_images = 'C:/Users/ASUS/Desktop/train-images.idx3.ubyte'
train_labels = 'C:/Users/ASUS/Desktop/train-labels.idx1.ubyte'
test_images ='C:/Users/ASUS/Desktop/t10k-images.idx3.ubyte'
test_labels = 'C:/Users/ASUS/Desktop/t10k-labels.idx1.ubyte'
#此处是我们将转化后的数据集保存的位置
save_train ='C:/Users/ASUS/Desktop/MNIST/train_images/'
save_test ='C:/Users/ASUS/Desktop/MNIST/test_images/'
if not os.path.exists(save_train):
os.makedirs(save_train)
if not os.path.exists(save_test):
os.makedirs(save_test)
trans(test_images, test_labels, save_test)
trans(train_images, train_labels, save_train)
2.2 将图片按照标签分类到具体文件夹
文章参考链接:python实现根据文件名自动分类转移至不同的文件夹
注意:为了适合这个数据集和我的win11系统对代码进行了一点调整,由于数据很多如果只需要部分数据一定要将那些数据单独放在一个文件夹。
# 导入库
import os
import shutil
# 当前文件夹所在的路径,使用时需要进行修改
current_path = 'C:/Users/ASUS/Desktop/MNIST/test'
print('当前文件夹为:' + current_path)
# 读取该路径下的文件
filename_list = os.listdir(current_path)
# 建立文件夹并且进行转移
# 假设原图片名称 test_001_2.jpg
for filename in filename_list:
name1, name2, name3 = filename.split('_') # name1 = test name2 = 001 name3 = 2.jpg
name4, name5 = name3.split('.') # name4 = 2 name5 = jpg
if name5 == 'jpg' or name5 == 'png':
try:
os.mkdir(current_path+'/'+name4)
print('成功建立文件夹:'+name4)
except:
pass
try:
shutil.move(current_path+'/'+filename, current_path+'/'+name4[:])
print(filename+'转移成功!')
except Exception as e:
print('文件 %s 转移失败' % filename)
print('转移错误原因:' + e)
print('整理完毕!')
2.3 数据存在的缺陷
-
数据集内的图片数量很多,由于后面介绍的云端训练的限制,只能采用部分数据(本人采用的是1000张,大家可以自行增减数目)。
-
数据集为国外的数据集,很多数字写的跟我们不一样。如果想要更好的适用于我们国内的场景,可以对数据集进行手动的筛选。下面是他们写的数字2:
 可以看出跟我们的不一样,不过数据集中仍然存在跟常规书写的一样的,我们需要进行人为的筛选。
可以看出跟我们的不一样,不过数据集中仍然存在跟常规书写的一样的,我们需要进行人为的筛选。
2.4 优化建议(核心)
分析发现,部分数字精度不高的原因主要是国外手写很随意,我们可以通过调整网络参数(如下)、人为筛选数据(如上)、增大数据集等方式进行优化。
二、模型训练
主要参考文章:通过云端自动生成openmv的神经网络模型,进行目标检测
!!!唯一不同的点是我图像参数设置的是灰度而不是上述文章的RGB。
下面是我模型训练时的参数设置(仅供参考):
通过混淆矩阵可以看出,主要的错误在于数字2、6、8。我们可以通过查看识别错误的数字来分析可能的原因。
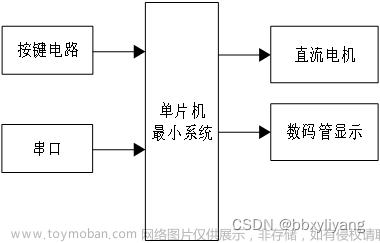
三、项目实现
!!!我们需要先将上述步骤中导出文件中的所有内容复制粘贴带OpenMV中自带的U盘中。然后将其中的.py文件名称改为main
1. 代码实现
本人修改后的完整代码展示如下,使用的是OpenMV IDE(官网下载):
# 数字识别后控制直流电机转速
from pyb import Pin, Timer
import sensor, image, time, os, tf, math, random, lcd, uos, gc
# 根据识别的数字输出不同占比的PWM波
def run(number):
if inverse == True:
ain1.low()
ain2.high()
else:
ain1.high()
ain2.low()
ch1.pulse_width_percent(abs(number*10))
# 具体参数调整自行搜索
sensor.reset() # 初始化感光元件
sensor.set_pixformat(sensor.GRAYSCALE) # set_pixformat : 设置像素模式(GRAYSCALSE : 灰色; RGB565 : 彩色)
sensor.set_framesize(sensor.QQVGA2) # set_framesize : 设置处理图像的大小
sensor.set_windowing((128, 160)) # set_windowing : 设置提取区域大小
sensor.skip_frames(time = 2000) # skip_frames :跳过2000ms再读取图像
lcd.init() # 初始化lcd屏幕。
inverse = False # True : 电机反转 False : 电机正转
ain1 = Pin('P1', Pin.OUT_PP) # 引脚P1作为输出
ain2 = Pin('P4', Pin.OUT_PP) # 引脚P4作为输出
ain1.low() # P1初始化低电平
ain2.low() # P4初始化低电平
tim = Timer(2, freq = 1000) # 采用定时器2,频率为1000Hz
ch1 = tim.channel(4, Timer.PWM, pin = Pin('P5'), pulse_width_percent = 100) # 输出通道1 配置PWM模式下的定时器(高电平有效) 端口为P5 初始占空比为100%
clock = time.clock() # 设置一个时钟用于追踪FPS
# 加载模型
try:
net = tf.load("trained.tflite", load_to_fb=uos.stat('trained.tflite')[6] > (gc.mem_free() - (64*1024)))
except Exception as e:
print(e)
raise Exception('Failed to load "trained.tflite", did you copy the .tflite and labels.txt file onto the mass-storage device? (' + str(e) + ')')
# 加载标签
try:
labels = [line.rstrip('\n') for line in open("labels.txt")]
except Exception as e:
raise Exception('Failed to load "labels.txt", did you copy the .tflite and labels.txt file onto the mass-storage device? (' + str(e) + ')')
# 不断的进行运行
while(True):
clock.tick() # 更新时钟
img = sensor.snapshot().binary([(0,64)]) # 抓取一张图像以灰度图显示
lcd.display(img) # 拍照并显示图像
for obj in net.classify(img, min_scale=1.0, scale_mul=0.8, x_overlap=0.5, y_overlap=0.5):
# 初始化最大值和标签
max_num = -1
max_index = -1
print("**********\nPredictions at [x=%d,y=%d,w=%d,h=%d]" % obj.rect())
img.draw_rectangle(obj.rect())
# 预测值和标签写成一个列表
predictions_list = list(zip(labels, obj.output()))
# 输出各个标签的预测值,找到最大值进行输出
for i in range(len(predictions_list)):
print('%s 的概率为: %f' % (predictions_list[i][0], predictions_list[i][1]))
if predictions_list[i][1] > max_num:
max_num = predictions_list[i][1]
max_index = int(predictions_list[i][0])
run(max_index)
print('该数字预测为:%d' % max_index)
print('FPS为:', clock.fps())
print('PWM波占空比为: %d%%' % (max_index*10))
2. 采用器件
使用的器件为OpenMV4 H7 Plus和L298N以及常用的直流电机。关键是找到器件的引脚图,再进行简单的连线即可。
参考文章:【L298N驱动模块学习笔记】–openmv驱动
参考文章:【openmv】原理图 引脚图
2. 注意事项
上述代码中我用到了lcd屏幕,主要是为了方便离机操作。使用过程中,OpenMV的lcd初始化时会重置端口,所有我们在输出PWM波的时候一定不要发生引脚冲突。我们可以在OpenMV官网查看lcd用到的端口:
可以看到上述用到的是P0、P2、P3、P6、P7和P8。所有我们输出PWM波时要避开这些端口。下面是OpenMV的PWM资源: 文章来源:https://www.toymoban.com/news/detail-621228.html
文章来源:https://www.toymoban.com/news/detail-621228.html
总结
本人第一次自己做东西也是第一次使用python,所以代码和项目写的都很粗糙,只是简单的识别数字控制直流电机。我也是四处借鉴修改后写下的大小,这篇文章主要是为了给那些像我一样的小白们提供一点帮助,减少大家查找资料的时间。模型的缺陷以及改进方法上述中已经说明,如果我有写错或者大家有更好的方法欢迎大家告诉我,大家一起进步!文章来源地址https://www.toymoban.com/news/detail-621228.html
到了这里,关于OpenMV数字识别进而控制直流电机转速【小白篇】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!