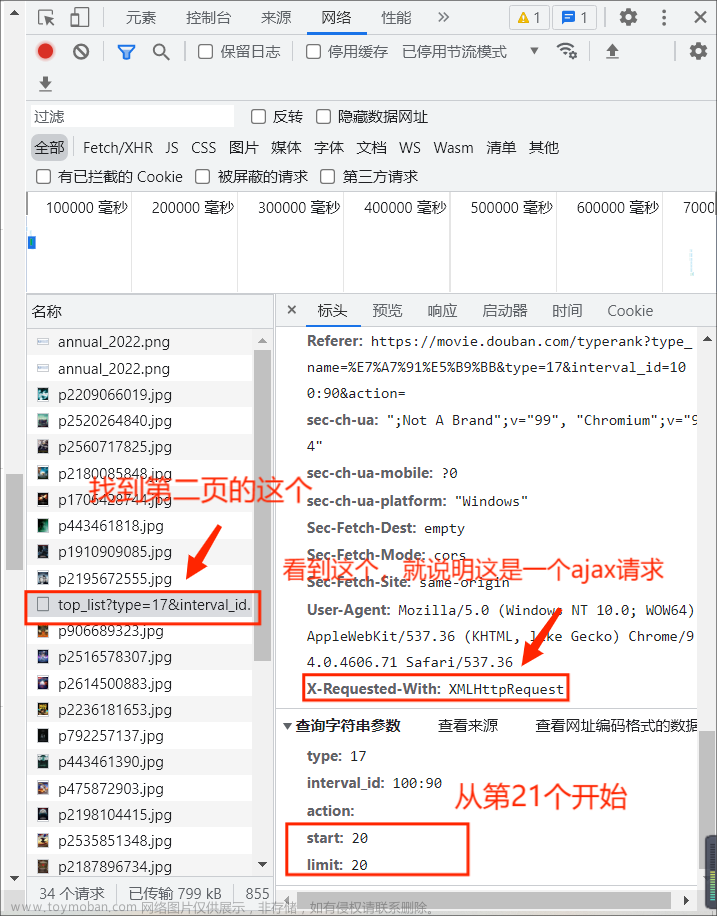
以豆瓣当下实时热门电影《热烈》作为分析对象
环境:
Python3(Anaconda3)
PyCharm
Chrome浏览器
主要模块:
BeautifulSoup
requests
pymysql
一.概括
目标:获得电影《热烈》的用户观影习惯数据
代码概括:
1.使用requests和bs4爬取电影《热烈》所有短评长评及其用户 2.爬取所有用户的观影数据并使用pymysql存入mysql数据库
3.对数据进行分析
二、(重点)登录豆瓣网(带有反爬虫)
豆瓣网使用一定的反爬虫技术,根据我的实验经验,主要是针对用户ID、用户IP和请求头的过滤
解决方案:
1携带登陆成功的cookie去请求get登陆
2.使用代理IP
3大量请求头随机使用
2.1使用小象代理IP
2.2大量请求头随机使用

2.3测试IP是否可用

2.4 登录豆瓣网

三.电影《热烈》全部长评reviews
以五星长评为例,遍历五星长评的网页,使用bs4爬取所需网页ontent,再读出所需信息得到信息list。
根据前文获得的headers和proxies,发出get请求,获取response。

使用bs4做网页解析,获取所需要的content

将提取的content提炼得到list

成功得到5星长评的第一页的用户list。
四.电影《热烈》全部短评comments
以五星短评为例,遍历短评的网页,使用bs4爬取所需网页content,筛选出五星短评content,再读出所需信息得到信息list。
根据前文获得的headers和proxies,发出get请求,获取response。

使用bs4做网页解析,获取所需要的content。

提取的content,过滤出五星短评,并提炼得到list

成功得到短评的第一页的五星用户list
五.存入数据库
以上内容经过去重,可以获得电影《热烈》的全部五星用户,现将这些五星用户list存入mysql数据库。

同样的方法可以获得全部的4星、3星、2星、1星用户,并都存入数据库或数据表
六.获取用户观影数据
已知用户主页链接,可以获得用户的观影数据。
以下代码是根据用户user_id 获取用户观影页面一页的数据。

已获取 list 数据,后续数据库操作和数据处理操作,就不详细展开了。
下面展示分析成果,对表格部分内容进行截取,将用户id做了打码处理。


生成条形图展示。

 文章来源:https://www.toymoban.com/news/detail-621231.html
文章来源:https://www.toymoban.com/news/detail-621231.html
文章来源地址https://www.toymoban.com/news/detail-621231.html
到了这里,关于爬虫练习-爬取豆瓣网电影评论用户的观影习惯数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2024/01/415693-1.png)