最近公司有几个服务遇到了瓶颈,也就是数据量增加了,没有人发现,这不是缺少一个监控服务和告警的系统吗?
主要需求是监控每个服务,顺带监控一下服务器和一些中间件,这里采集的2种,zabbix和prometheus,由于我们要监控的是Docker容器中的服务,最终选择prometheus。
如下:
一 实现功能
- 服务宕机,不能提供服务,飞书收到告警信息。
- 容器中服务占用分配内存达到50, 飞书收到预警信息。
- 容器中服务中JVM堆内存占用达到80, 飞书收到预警信息。
- 服务发生OOM后,服务可以立刻重启。
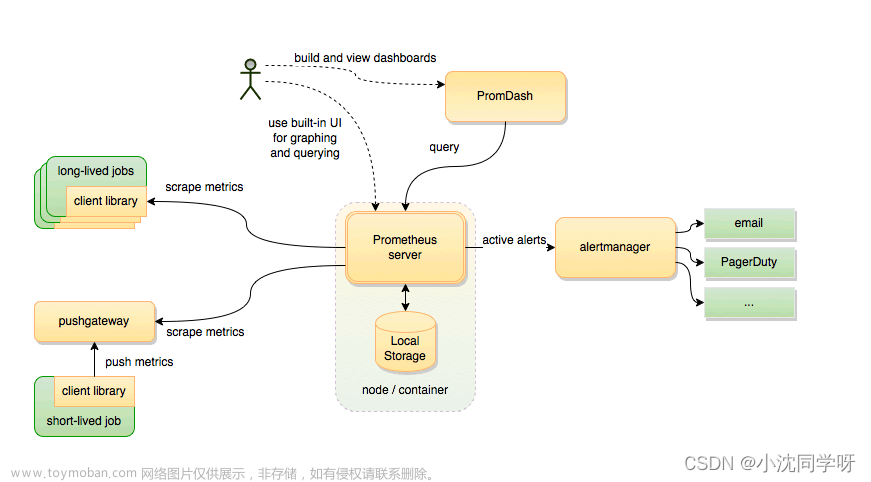
二:流程图

三 步骤
确定要监控的docker服务, 这里以公司的A服务为例子
- 查看服务的Dockerfile 和run.sh
Dockerfile是构建docker镜像,run.sh是启动服务用的
1.1 Dockerfile中java执行命令添加:
"-XX:+HeapDumpOnOutOfMemoryError","-XX:HeapDumpPath=/temp/dump","-XX:+ExitOnOutOfMemoryError","-XX:MaxRAMPercentage=75.0"
-XX:+HeapDumpOnOutOfMemoryError:参数表示当JVM发生OOM时,自动生成DUMP文件
-XX:HeapDumpPath=/temp/dump:生成dump目录文件的位置
-XX:+ExitOnOutOfMemoryError:JVM在第一次出现内存不足错误时退出,启动JVM实例
-XX:MaxRAMPercentage=75.0: 这为JVM定义了75%的总内存限制

查看服务目前容器大小,和占用内存大小,保证占用内存稳定在30%一下。
docker stats dcda4228b794

这边找了一个47%的,只给了1G的容器大小。需求中超过50%就会告警。
如果超过50%,需要在启动容器的run.sh命令中提升初始容器大小
修改--memory 1024m \ --memory-swap 1024m \的值,是容器的内存大小
以上是容器要做的一些调整,也是自己定义的规则。
2. Idea中找到A应用,修改POM和 application.properties文件
application.properties中添加
management.endpoint.health.show-details=always
management.endpoints.web.exposure.include=*
这边要注意,如果你是yml文件 management.endpoints.web.exposure.include=*,
这个 * 一定要加 ''单引号,*在yml文件中是通配符。

POM中添加,目的是当前服务可以提供一些监控指标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>注意,如果你的服务属于对外接口访问服务,有Shiro拦截的话要配置
filterChainDefinitionMap.put("/actuator/prometheus", "anon");至此完成代码的整改,可以提交代码,部署服务。
确定服务正常启动:输入docker ps -a (不加-a就看正常运行的服务,-a是看所有的服务,包括停止的)

去服务器厂商放开当前服务对外的端口号,主要是对指定监控的服务器放开,不是所有

环境地址访问 http://ip:port/actuator/prometheus
看到如下,就是提供的指标数据
3 docker容器监控服务
部署prometheus,alertmanager,garfana, 还有一个推消息给飞书的服务, 这个大家如果想找到怎么部署,可以留言,我整理一下,写出来。不过后面有时间我也会更新这边部署监控文章的。

1. cadvisor 是容器内个服务的监控指标提取
2. prometheus-webhook-feishu 是网上找的一个开源的飞书通知服务
3.alertmanager是告警管理 --通知2下发告警的
4.grafana是可视化大屏,对prometheus采集的数据可视化展示
5.node-exporter 是服务器监控,提取服务器的指标数据
6.prometheus 是核心的监控服务
4. 配置prometheus
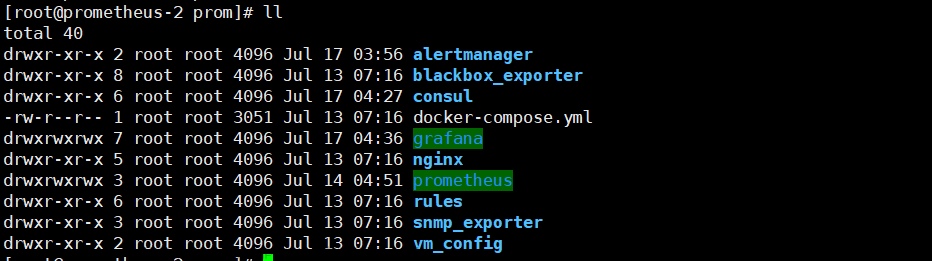
进入prometheus

看到这几个文件夹/文件,其中主要配置实例在prometheus.yml中,rules文件下是配置告警规则的。
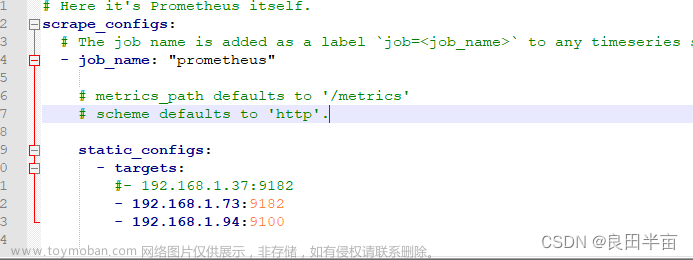
进入prometheus.yml仿照- job_name: 自己创建一个
- job_name: "A" # 监控的job名称
metrics_path: '/actuator/prometheus' # 监控的指标路径
static_configs:
- targets: ['ip:port'] #监控的服务器和端口端口已经开放
labels:
serviceId: A-snapshot #服务id告警展示
serviceName: A-web #服务名称 告警展示重启prometheus
docker restart prometheus
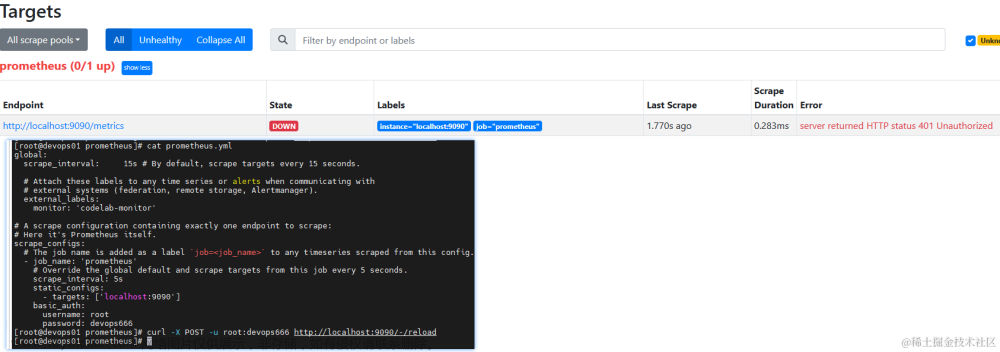
访问http://ip:9090/查看配置的任务,如下up状态代表服务正常启动,配置任务成功。

rules下有配置服务器/服务的告警规则
1. 服务器内存使用超过98%告警规则

(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 98

(node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 > 95

会对配置在prometheus中没有job都做监控,up==0标识改服务宕机,提示。
可以做验证
docker stop A服务容器id


飞书收到这个通知,如何配置 prometheus-alertmanager-feishu的流程后续会同步上
4.配置其他告警规则 这里配置容器内存超过50提示,和服务jvm中堆占用80提示
配置路径/minitor/prometheus/rules
可以自己重新定义一个yml ,下面yml下面所有规则都会被prometheus识别,一般按照项目建一个文件
容器内存超过50

groups:
# 组名。报警规则组名称
- name: A服务内存预警
rules:
- alert: a服务内存使用率预警
# expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
expr: container_memory_usage_bytes{image="a:latest"}/container_spec_memory_limit_bytes{image="a:latest"} * 100 > 50
# for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
for: 20s # for语句会使 Prometheus 服务等待指定的时间, 然后执行查询表达式。(for 表示告警持续的时长,若持续时长小于该时间就不发给alertmanager了,大于
该时间再发。for的值不要小于prometheus中的scrape_interval,例如scrape_interval为30s,for为15s,如果触发告警规则,则再经过for时长后也一定会告警,这是因为>最新的度量指标还没有拉取,在15s时仍会用原来值进行计算。另外,要注意的是只有在第一次触发告警时才会等待(for)时长。)
# labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
labels:
# severity: 指定告警级别。有三种等级,分别为 warning, critical 和 emergency 。严重等级依次递增。
severity: critical
# annotations: 附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
annotations:
title: "a服务内存使用率预警"
serviceName: "{{ $labels.serviceName }}"
instance: "{{ $labels.instance }}"
value: "{{ $value }}"
btn: "点击查看详情 :玫瑰:"
link: "http://xxxxxxxxx:9090/targets"
template: "**${serviceName}**(${instance})正式服务内存使用率已经超过阈值 **50%**, 请及时处理!\n当前值: ${value}%"
expr:container_memory_usage_bytes{image="a:latest"}/container_spec_memory_limit_bytes{image="a:latest"} * 100 > 50
这个可以在之前prometheus查看

服务jvm中堆占用80提示

- name: A服务堆内存超高预警
rules:
- alert: A服务堆内存使用率超高预警
expr: sum(jvm_memory_used_bytes{serviceId="a", area="heap"})*100/sum(jvm_memory_max_bytes{serviceId="a", area="heap"}) > 80
for: 20s
labels:
severity: red
annotations:
title: "a服务堆内存使用率超高预警"
serviceName: "{{ $labels.serviceName }}"
instance: "{{ $labels.instance }}"
value: "{{ $value }}"
btn: "点击查看详情 :玫瑰:"
link: "http://xxxxxxxx:9090/targets"
template: "**${serviceName}**(${instance})正式环境服务内存使用率已经超过阈值 **80%**, 请及时处理!\n当前值: ${value}%"expr: sum(jvm_memory_used_bytes{serviceId="job中配置的", area="heap"})*100/sum(jvm_memory_max_bytes{serviceId="job中配置的", area="heap"}) > 80

重启prometheus
5 验证容器内存超过50 堆内存超80 和出现OOM后容器自动重启服务
在服务中加一个测试oom的接口, 正式发布后,这个接口要去掉
如下: 会不断的生成不回收的对象 /dev/d
package xxx;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletRequest;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
*/
@Slf4j
@RestController
@RequestMapping("dev")
public class Controller {
@RequestMapping("/a")
public Integer message() {
log.info(">>>>info");
log.debug(">>>>>Debug");
return Runtime.getRuntime().availableProcessors();
}
@RequestMapping("/d")
public String messaged(HttpServletRequest request) throws InterruptedException {
log.info(">>>>info");
log.debug(">>>>>Debug");
List<Object> list = new ArrayList<>();
new Thread(new Runnable() {
@Override
public void run() {
List<Object> list2 = new ArrayList<>();
int initSize = 1024 * 1024 * 300;
Map<String, Object> map = new HashMap<>();
int i= 0;
while(true) {
try{
Thread.sleep(5000);
} catch(Exception e) {
e.printStackTrace();
}
//每次添加50M
int userMemory = 1024*1024*10;
i++;
map.put("userMemory" + i, new byte[userMemory]);
list.add(map);
list2.add(map);
}
}
}).start();
return "OK";
}
}这里对A服务运行dev/d接口
先看dev/a 是看运行的cpu个数,验证服务是否启动

这时候别着急让服务OOM
先看cAdvisor,容器监控都靠他,监控别的服务器容器也要在对应服务器上安装。
环境运行: http://ip:19190/

点击Docker Containers可以看具体容器的信息,找到你要配置的容器A
里面包括很多参数指标信息,这里先看容器内存

和docker stats运行的值基本一致
Jvm堆内存使用占比,我们可以根据cAdvisor提供的
jvm_memory_used_bytes
jvm_memory_max_bytes
执行接口,查看对应数据,验证告警信息。
等会我们执行增加jvm堆内存的接口,要看容器的内存使用,和jvm中堆占比都上升,知道堆内存占比100%发生OOM后,容器重启服务,过程中,会提示容器内存使用超过50%,堆内存使用超过80%
1. 系统OOM 产生dump文件 之前第一步有配置
2. 系统OOM 会立刻重启服务,保证不宕机,服务可用
3. 容器内存超50% 告警
4. 堆内存超80% 告警
第一个:
在docker下dump/temp发现 java_pid6.hprof 文件--后面讲
第二个 服务立刻重启,并且输入dev/a 还是可以访问的
第三个 收到告警
这个过程,百分比是慢慢上升的可以通过docker stats/cadvisor看数据


- 继续监控
此时堆内存已经达到91 > 80

容器内存也快达到,瓶颈


- 继续监控,突然会服务重新,出现OOM,
也可以docker logs -f xxx查看日志,此时对象都释放掉了

又回到服务初始容器内存占比和jvm堆使用占比
至此,完成了服务宕机告警,容器内存超50%告警,堆内存超80%告警,服务出现OOM后服务重启。
6 可视化监控的页面grafana
可以通过看大屏数据,感觉还挺牛的,可以自定义。
http://xxxxx:3000/ grafana可视化监控,是对prometheus采集的数据做大屏展示
如:展示刚刚容器中jvm的一些指标信息 配置模板id:4701 用过grafana你就知道了。相当于一个模版id
展示当前服务器中所有容器的cpu,内存,硬盘等使用情况
模板id: 116000 是查看当前容器中各服务,cpu,内存使用情况。

也可以对整个服务器做监控展示 模板id:8919

grafana的更多常用模板地址:Dashboards | Grafana Labs
目前监控的实现方案如上,有好的优化方案和新的监控点,告警点互相讨论。
7 上面代码出现OOM,简单排查过程
主要是分析dump文件
通过写的代码,看到开启一个线程,不停的给ArrayList插入一个value是10M的Map
在配置java启动中,我们把oom自动生成的dump文件拿出来

进到容器中把文件cp到宿主机
分析工具:MemoryAnalyzer 导入文件
1 进入Leak Suspects 2进入Dominator Tree

进入Leak Suspects 点击detail 发现出现一堆HashMap没有回收,这和我们的代码问题一致

进入 Dominator Tree查看
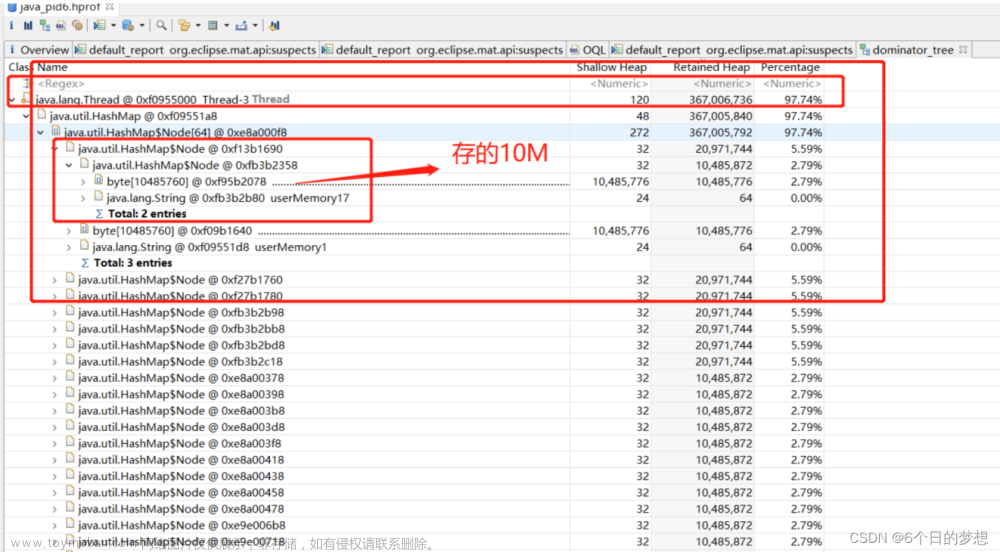
发现有很多的HashMap key 是递增的,value是一个10M的Byte[]
代码都是自己写的。哈哈。
定位代码:

服务地址:
Promethues: http://xxxx:9090
Grafana: http://xxxx:3000
Alertmanager: http://xxxx:19093文章来源:https://www.toymoban.com/news/detail-621318.html
cAdvisor的所有容器监控 http://xxxxx:19190/containers/文章来源地址https://www.toymoban.com/news/detail-621318.html
到了这里,关于prometheus 配置服务器监控、服务监控、容器中服务监控与告警的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!