Redis集群管理
Redis Cluster提供了一套完整的功能技术,使得Redis能够以分布式的方式运行,并具备高可用性、容错性和扩展性。通过自动发现、主从选举、在线分片等机制,Redis Cluster能够自动管理集群中的节点,并保证数据的一致性和可靠性。同时,基于配置文件和转向机制,Redis Cluster能够提供灵活的集群管理和数据访问方式。
-
拓扑结构:Redis集群由多个节点组成,每个节点都是一个独立的Redis实例。节点之间通过Gossip协议进行通信和信息交换。
-
数据分片:集群将数据分散存储在不同的节点上。采用哈希槽(hash slot)的方式进行数据分片,集群默认使用16384个哈希槽。每个键根据哈希函数计算得到一个槽位,集群根据槽位将键值对分配到对应的节点上进行存储。
-
主从复制:每个节点可以拥有多个从节点,实现数据的冗余和高可用性。主节点负责写入和处理命令请求,从节点则复制主节点的数据,并可以接收读请求。当主节点不可用时,从节点会自动选举一个新的主节点。
-
自动分片迁移:当集群中新增或删除节点时,集群会自动进行数据的迁移,保持数据均衡分布在不同的节点上。集群通过对槽位进行重新分配来实现数据的平衡。
-
故障检测和容错:Redis集群具有故障检测和容错机制。当节点失效或下线时,集群会自动检测并将槽位迁移到其他正常的节点上,确保数据的高可用性。同时,集群还会进行节点间的心跳检测,及时发现并处理故障。
-
客户端路由:在使用Redis集群时,客户端需要通过一个集群客户端来进行访问。集群客户端会根据键的哈希值将请求路由到正确的节点上,保证每个请求都能够到达正确的节点。
查看集群中各个节点状态
集群(cluster)
在此前提,我们需要使用./redis-cli -h 本地节点的ip -p redis的端口号 -a 密码的指令进行登录到我们的redis集群中,进入到redis客户端后,运行如下命令,查看集群中节点状态
cluster info的执行效果
"CLUSTER INFO"是一个Redis集群命令,用于获取有关Redis集群状态和拓扑的信息。当您在一个Redis集群环境中使用时,这个指令可以提供有关集群的关键信息,以便您监控和管理集群。
xx.xx.xx.xx:6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_sent:23695
cluster_stats_messages_received:23690
指令结果分析
下面是"CLUSTER INFO"指令返回的信息的解释:
-
“cluster_state”(集群状态):这是一个表示集群状态的字符串。它可以是以下几个值之一:
- “ok”:表示集群状态良好。
- “fail”:表示集群状态出现故障。
- “handshake”:表示集群正在进行节点握手操作。
-
“cluster_slots_assigned”(已分配槽位):该值表示已经在集群中分配的槽位数量。Redis集群将数据分散存储在不同的槽位中,这个值表示有多少个槽位已被分配。
-
“cluster_slots_ok”(正常槽位):这是一个表示当前状态正常的槽位数量的值。如果集群中的所有槽位都正常,则该值将与已分配的槽位数相等。
-
“cluster_slots_pfail”(部分失败槽位):这是一个表示部分槽位失败的数量值。当集群中有槽位处于部分失败状态时,该值会增加。
-
“cluster_slots_fail”(失败槽位):这是一个表示失败的槽位数量的值。如果集群中有槽位处于失败状态,则该值会增加。
-
“cluster_known_nodes”(已知节点):这是一个表示在集群中已知节点数量的值。它包括了主节点和从节点。
-
“cluster_size”(集群大小):该值表示集群的整体大小,即集群中所有节点的总数(包括主节点和从节点)。
-
“cluster_current_epoch”(当前纪元):这是一个用于在集群中执行故障转移操作时进行实时同步的纪元值。
-
“cluster_my_epoch”(当前节点纪元):这是当前节点的纪元值,在集群中通过它来标识节点。
-
“cluster_stats_messages_sent”(发送的消息数):这是一个表示当前节点发送的消息数量的值。
-
“cluster_stats_messages_received”(接收的消息数):这是一个表示当前节点接收的消息数量的值。
"CLUSTER INFO"指令返回的一些关键信息。它们可以帮助您了解Redis集群的状态、槽位分配情况、节点数量和消息传输情况等重要信息。通过分析这些信息,您可以更好地监控和管理您的Redis集群。
cluster nodes的执行效果
"CLUSTER NODES"是一个Redis集群命令,用于获取有关Redis集群中所有节点的信息。当您在一个Redis集群环境中使用时,这个指令可以提供关于每个节点的详细信息,包括节点ID、节点地址、角色(主节点或从节点)、槽位分配和连接状态等。
xx.xx.xx.xx:6379> cluster nodes
e2cfd53b8083539d1a4546777d0a81b036ddd82a xx.xx.xx.xx:6384 slave f1f6e93e625e8e0cef0da1b3dfe0a1ea8191a1ad(主节点为:xx.xx.xx.xx:6380) 0 1510021756842 6 connected
857a5132c844d695c002f94297f294f8e173e393 xx.xx.xx.xx:6379 myself,master - 0 0 1 connected 0-5460
e4394d43cf18aa00c0f6833f6f498ba286b55ca1 xx.xx.xx.xx:6382 master - 0 1510021759865 4 connected 5461-10922
16eca138ce2767fd8f9d0c8892a38de0a042a355 xx.xx.xx.xx:6383 slave 857a5132c844d695c002f94297f294f8e173e393 0 1510021757849 5 connected
f1f6e93e625e8e0cef0da1b3dfe0a1ea8191a1ad xx.xx.xx.xx:6380 master - 0 1510021754824 2 connected 10923-16383 ##红色字体可以看出只有主节点会被分配哈希槽
d14e2f0538dc6925f04d1197b57f44ccdb7c683a xx.xx.xx.xx:6381 slave e4394d43cf18aa00c0f6833f6f498ba286b55ca1 0 1510021758855 4 connected
xx.xx.xx.xx:6379>
指令结果分析
CLUSTER NODES可以查看到主从关系,以及节点的健康程度,下面是"CLUSTER NODES"指令返回的信息的解释:
-
“Node ID”(节点ID):每个Redis节点都有一个唯一的节点ID,用于标识它在集群中的位置。
-
“Address”(节点地址):节点的IP地址和端口号。
-
“Flags”(标志):标志表示节点的各种状态和角色。常见的标志包括:
- “master”:表示节点是主节点。
- “slave”:表示节点是从节点。
- “myself”:表示当前节点是查询命令的节点。
- “fail?”:表示节点是否被认为处于失败状态。
-
“Master ID”(主节点ID):对于从节点,该字段显示它所属的主节点的ID。对于主节点,该字段为空。
-
“Slots”(槽位):该字段显示节点负责的槽位范围。每个Redis集群将数据分散存储在不同的槽位中,该字段指示节点负责的槽位范围。
-
“Last Hello”(最后一次心跳):显示节点和集群之间最后一次交换心跳消息的时间。
-
“Status”(状态):表示节点的连接状态。常见的状态包括:
- “connected”:表示节点与集群保持连接。
- “disconnected”:表示节点与集群断开连接。
"CLUSTER NODES"命令返回的信息以文本形式呈现,每个节点的信息以行为单位。您可以解析这些信息来了解整个集群中每个节点的状态、角色和槽位分配情况。这对于监控和管理Redis集群非常有用,能够帮助您了解集群的拓扑结构和节点之间的连接状态。
节点(node)
在Redis集群中,“node”(节点)是指负责管理一个或多个哈希槽(slots)的Redis实例。集群将数据分散在多个节点上,以实现高可用性和横向扩展。
每个节点都是一个独立的Redis服务器实例,具有自己的配置、内存、CPU和磁盘。节点之间通过内部通信进行数据同步和协调。
在Redis集群中,节点具有以下特点:
-
负责一部分哈希槽:Redis集群将全局数据分为16384个哈希槽,并将这些槽分配给集群中的各个节点。每个节点负责管理一部分哈希槽,处理存储在这些槽中的键值对的操作。通过将槽分散在多个节点上,Redis集群可以实现数据的分布和负载均衡。
-
数据同步:节点间通过内部通信协议进行数据同步。当一个节点接收到写操作时,它会将更新的数据复制到其他节点上,以确保数据在整个集群中的一致性。
-
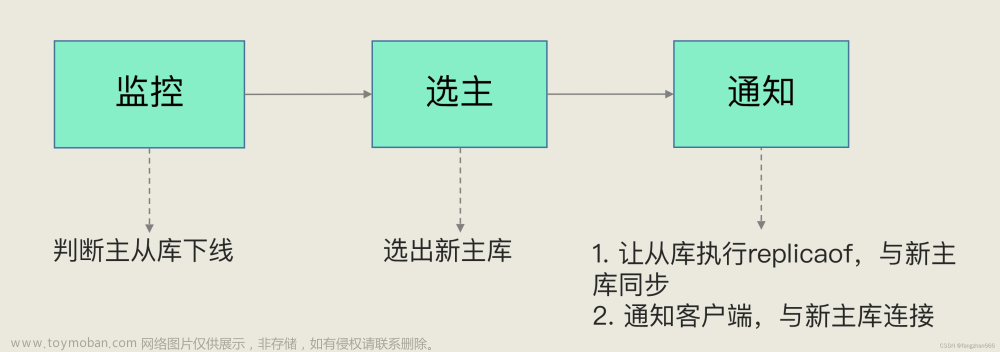
故障转移和高可用性:Redis集群提供了故障转移机制,可以在节点失效时自动将其替换为新的节点。每个节点都有一个主节点和若干个从节点。当主节点失效时,从节点会参与选举新的主节点,并继续提供服务。这种机制确保了Redis集群的高可用性。
-
节点间通信:节点之间通过内部通信协议进行数据同步和协调。节点会定期交换状态信息,例如哈希槽分配和节点的健康状态。这种通信机制使得集群能够实时监控节点的状态,并做出相应的调整和决策。

CLUSTER MEET
"CLUSTER MEET"是一个Redis集群命令,用于将指定的节点添加到Redis集群中,使其成为集群的一部分。
命令的语法如下:
CLUSTER MEET <ip> <port>
其中,<ip>是要添加的节点的IP地址,而<port>是该节点的端口号。
当您使用CLUSTER MEET命令时,Redis集群会尝试与指定的节点建立连接,并将其纳入到集群中。如果连接成功,Redis会将新节点添加为一个普通节点,并在节点之间进行必要的信息交换,以使其成为集群中的一部分。
当新节点被添加到集群后,它将被分配一部分槽位,用于存储集群中的数据。槽位在整个集群中均匀分布,每个节点负责管理一定范围的槽位。通过添加更多的节点,您可以扩展Redis集群的容量和性能,并实现数据的高可用性和负载均衡。
需要注意的是,添加节点到Redis集群需要确保新节点的IP地址和端口号是正确可达的,并且新节点的Redis实例没有与现有集群节点发生冲突(即IP地址和端口号不能与现有节点相同)。
使用CLUSTER MEET命令可以轻松地将新的Redis节点添加到集群中,以扩展集群的能力和可靠性。
CLUSTER FORGET
"CLUSTER FORGET"是一个Redis集群命令,用于将指定的节点从Redis集群中移除。命令的语法如下:
CLUSTER FORGET <node id>
其中,<node id>是要移除的节点的ID。
当您使用CLUSTER FORGET命令时,Redis集群会将指定的节点从集群中移除。该节点将被视为无效节点,并且不再被集群所感知。这个命令通常在需要从Redis集群中移除故障或不确定节点时使用,例如节点停机、故障或离线状态不明确。
注意,移除节点可能会导致集群中的数据丢失,因为被移除的节点所负责的一部分槽位中的数据将不再可达。在执行此命令之前,请确保您了解被移除节点的情况,并确保数据的备份和复制,以减少数据丢失的风险。
同时,移除节点后,Redis集群中的其他节点会自动感知到该节点的移除,并重新分配移除节点负责的槽位给其他可用节点,以保持集群的正常运行。
使用CLUSTER FORGET命令可以有效地从Redis集群中移除指定的节点,以解决故障或不确定性问题,并确保集群的稳定性和可靠性。
CLUSTER REPLICATE
"CLUSTER REPLICATE"是一个Redis集群命令,用于将当前节点设置为指定节点的从节点(replica)。命令的语法如下:
CLUSTER REPLICATE <node id>
其中,<node id> 是要设置为从节点的节点的ID。
当您使用CLUSTER REPLICATE命令时,当前节点将被设置为指定节点的从节点。从节点是主节点(master)的副本,它会复制主节点的数据,并按照主节点的指令进行同步更新。从节点可以提供读取请求的负载均衡,同时增强了数据的冗余性和可用性。
被设置为从节点的当前节点将开始与主节点进行通信,通过复制主节点的数据来保持数据的一致性。从节点将定期从主节点接收增量数据,并将其应用到本地副本中,以与主节点保持同步。
使用CLUSTER REPLICATE命令可以方便地将当前节点设置为指定节点的从节点,并通过从节点复制主节点的数据来提高数据的可用性和读取性能。这在构建高可用性、可伸缩性和容错性的Redis集群时非常有用。
注意,从节点的复制行为是异步的,它会有一定的延迟,因此从节点的数据可能不会与主节点的数据完全实时同步。但是,从节点会自动尽力追赶主节点,并尽量保持数据的一致性。
CLUSTER SAVECONFIG
当执行命令cluster saveconfig时,集群会将当前的配置文件保存到硬盘上。配置文件通常包含了集群的各种设置和参数,如网络配置、安全设置、存储设置等。
这个命令非常有用,因为它可以帮助你在集群发生故障或重启时快速恢复之前的配置状态。通过将配置文件保存到硬盘上,你可以在需要时重新加载它,以确保集群的设置和配置与之前保持一致。
保存配置文件到硬盘的过程是自动进行的,你不需要手动指定保存的路径或文件名。通常情况下,配置文件会保存在集群的默认配置目录中,具体位置可能因系统而异。你可以在文档或官方指南中查找相关信息,以了解配置文件的保存位置。
当需要恢复配置时,你可以使用对应的命令(如cluster loadconfig)将保存在硬盘上的配置文件加载到集群中,以重新应用之前的配置设置。
注意,保存配置文件到硬盘是一项重要的操作,请确保你具有足够的权限来执行此操作,并且小心保管保存的配置文件,以防止未经授权的访问或意外的数据泄露。
CLUSTER SLAVES
在Redis集群中,每个master节点可以有多个对应的slave节点。Slave节点是master节点的从属节点,它们通过复制(master-slave replication)来保持数据的一致性。
cluster slaves <node id>使用这个命令时,需要替换<node id>为具体的slave节点的ID或名称。执行命令后,Redis集群会返回给你该slave节点所对应的master节点信息。
获取slave节点的master节点信息对于监控和调试集群非常有用。你可以根据返回的结果查看每个slave节点的主节点,以更好地了解集群的拓扑结构和复制关系。
注意,slave节点和master节点之间通过异步复制进行数据同步,因此在进行读取操作时,建议直接访问master节点,以确保获取到的是最新的数据。
cluster set-config-epoch
cluster set-config-epoch命令用于设置Redis集群的配置纪元(config epoch)。配置纪元是一个用于标识集群配置变化的整数值,每当集群发生配置更改时,这个值都会递增。
在Redis集群中,配置纪元主要用于解决主从切换(failover)过程中的冲突问题。当一个master节点下线或发生故障时,集群需要从其它可用的slave节点中选举一个新的master节点来接管。当新的master节点被选举为主节点时,它将会增加配置纪元的值,以通知其它节点发生了配置变化。
通过使用cluster set-config-epoch命令,你可以手动设置配置纪元的值。这在某些特殊情况下可能是有用的,比如当你需要手动引导一个新的master节点或修复集群中的配置冲突问题时。
此外,在Redis集群中可以使用configEpoch配置项来查看当前集群的配置纪元值。你可以通过读取这个值来了解集群的配置状态和变化情况。
槽(slot)
在Redis集群中,哈希槽(hash slot)是一种用于进行数据分区和数据共享的机制。
Redis集群中的数据被分割成 16384 个哈希槽,每个槽可以存储一个或多个键值对。在集群中的每个节点都负责一部分槽的数据存储和处理。当一个节点接收到一个操作命令时,它会根据命令操作的键(key)使用一致性哈希算法来决定该键属于哪个哈希槽,然后将该操作转发给负责管理该槽的节点进行处理。
哈希槽的设计使得Redis集群能够进行水平扩展和负载均衡。通过将数据分布在多个节点上,集群可以同时处理更多的请求,提高系统的吞吐量和并发能力。此外,当需要扩展集群时,可以通过添加新的节点,并将未分配的槽分配给新节点来实现扩展。
在Redis集群中管理哈希槽的分配是通过集群管理命令来完成的,例如cluster addslots用于将槽分配给节点,cluster delslots用于从节点中删除槽,cluster countkeysinslot用于计算槽中的键值对数量等等。这些命令使得管理员可以灵活地管理集群中的数据分布和节点调度。
cluster addslots
cluster addslots是Redis集群中的一个命令,用于将一个或多个哈希槽(hash slot)分配给当前节点。
cluster addslots <slot>[slot ...]
在Redis集群中,数据被分割为16384个哈希槽,每个槽都可以存储一个或多个键值对。这种分区方式使得数据能够在集群中进行水平扩展和负载均衡,每个节点负责一部分槽的数据。
当你在Redis集群中添加一个新的节点时,这个节点默认是没有分配任何哈希槽的。因此,你可以使用cluster addslots命令手动将特定的哈希槽分配给该节点。你可以指定一个或多个槽的范围,例如cluster addslots 0 1 2 3 4 1000-2000,这将将槽0、1、2、3、4以及1000到2000之间的槽分配给当前节点。
在执行cluster addslots命令后,Redis集群将会更新集群的分配信息,并将这些槽分配给指定的节点。集群会自动将新分配的槽信息同步给其它节点,以确保哈希槽的分配在整个集群中保持一致。
cluster delslots
cluster delslots <slot>[slot...] 是用于在Redis集群中移除指定哈希槽(slot)的命令。
在Redis集群中,每个节点都负责管理一部分哈希槽,并处理与这些槽相关的操作。通过移除槽,你可以调整集群中节点之间的数据分布,以满足不同的需求。
使用cluster delslots命令,你可以指定一个或多个哈希槽来进行移除。语法如下:
cluster delslots <slot>[slot...]
其中,<slot>[slot...]指定了要移除的槽的编号。你可以一次指定一个或多个槽,用空格分隔它们的编号。
请注意,执行此命令将导致所选槽内的数据被删除或不可访问。在移除槽之前,请确保你了解操作的后果,并确保有适当的备份和数据迁移策略。
以下是一个使用cluster delslots命令的示例:
cluster delslots 1234 5678
该示例将从当前节点中移除槽1234和5678。移除后,这些槽内的数据将不再由该节点负责处理。
CLUSTER FLUSHSLOTS
CLUSTER FLUSHSLOTS 是一个 Redis 集群命令,用于清空集群中所有节点所负责的哈希槽(slots)。当执行该命令时,集群将会移除所有键值对,并将所有哈希槽设置为空,从而实现集群中数据的清空操作。
使用 CLUSTER FLUSHSLOTS 命令需要注意以下几点:
-
需要连接到集群主节点执行:
CLUSTER FLUSHSLOTS命令只能在连接到集群的主节点上执行。如果你连接到一个从节点上,需要先使用CLUSTER FAILOVER命令切换到主节点上。 -
数据删除是不可逆操作:执行
CLUSTER FLUSHSLOTS命令后,集群中存储的所有键值对都将被永久地删除,无法恢复。确保在执行该命令前,你已经做好了备份或确认数据不再需要。 -
需要集群处于正常工作状态:在执行
CLUSTER FLUSHSLOTS命令前,确保集群处于正常工作状态,所有节点都在线,并且所有哈希槽都有主节点。如果集群中有节点失效或哈希槽未分配给主节点,需要先修复集群再执行该命令。
执行 CLUSTER FLUSHSLOTS 命令的示例:
- 使用 Redis 命令行客户端连接到 Redis 集群的主节点。
- 执行
CLUSTER FLUSHSLOTS命令:CLUSTER FLUSHSLOTS。
CLUSTER SETSLOT <slot> NODE <node id>
CLUSTER SETSLOT <slot> NODE <node id> 是一个 Redis 集群命令,用于将指定的哈希槽(slot)分配给指定的节点(node id)。如果槽已经被分配给其他节点,该命令会先要求另一个节点删除该槽,然后再指派给目标节点。
使用 CLUSTER SETSLOT <slot> NODE <node id> 命令需要注意以下几点:
-
集群正常工作状态:在执行
CLUSTER SETSLOT <slot> NODE <node id>命令之前,确保 Redis 集群处于正常工作状态,所有节点都处于在线状态。 -
槽的范围:Redis 集群将所有的键值对分配到不同的哈希槽上,默认情况下,集群有16384个哈希槽。
<slot>参数是一个整数,表示要操作的具体槽编号。 -
节点的标识:
<node id>参数是一个字符串,表示节点的标识,通常是节点的 ID 或节点的 IP 地址加端口。 -
数据迁移:如果目标槽(slot)已经被其他节点所指派,集群会先发送指令给该节点,要求它删除该槽的键值对。然后,集群会将该槽重新指派给目标节点。这意味着,在键值对迁移过程中,会有一段时间内数据可能会在集群中的其他节点之间进行迁移。
执行 CLUSTER SETSLOT <slot> NODE <node id> 命令的示例:
- 使用 Redis 命令行客户端连接到 Redis 集群的任意节点。
- 执行
CLUSTER SETSLOT <slot> NODE <node id>命令,将指定的哈希槽分配给指定的节点。- 例如,将槽5指派给节点1234567890abcdef1234567890abcdef12345678:
CLUSTER SETSLOT 5 NODE 1234567890abcdef1234567890abcdef12345678
- 例如,将槽5指派给节点1234567890abcdef1234567890abcdef12345678:
CLUSTER SETSLOT <slot> MIGRATING <node id>
CLUSTER SETSLOT <slot> MIGRATING <node id> 是一个 Redis 集群命令,用于将本节点上的指定槽(slot)迁移至指定的节点(node id)。
使用 CLUSTER SETSLOT <slot> MIGRATING <node id> 命令时,需要注意以下几点:
-
迁移流程:在进行槽迁移之前,请确保 Redis 集群正常工作,并且源节点和目标节点都处于在线状态。迁移槽的过程包括以下几个步骤:
- 源节点将指定的槽标记为正在迁移(migrating)状态。
- 将该槽的键值对复制到目标节点。
- 源节点从本地删除该槽的键值对。
- 源节点将该槽的迁移状态(migrating)更新为迁移结束(importing)。
-
槽的范围:Redis 集群将所有的键值对分配到不同的哈希槽上,默认情况下,集群有16384个哈希槽。
<slot>参数是一个整数,表示要操作的具体槽编号。 -
节点的标识:
<node id>参数是一个字符串,表示目标节点的标识,通常是节点的 ID 或节点的 IP 地址加端口。
执行 CLUSTER SETSLOT <slot> MIGRATING <node id> 命令的示例:
- 使用 Redis 命令行客户端连接到 Redis 集群的源节点。
- 执行
CLUSTER SETSLOT <slot> MIGRATING <node id>命令,将指定槽迁移到指定的目标节点。- 例如,将本节点上的槽5迁移到目标节点1234567890abcdef1234567890abcdef12345678:
CLUSTER SETSLOT 5 MIGRATING 1234567890abcdef1234567890abcdef12345678
- 例如,将本节点上的槽5迁移到目标节点1234567890abcdef1234567890abcdef12345678:
CLUSTER SETSLOT <slot> IMPORTING <node_id> 是一个 Redis 集群命令,用于从指定节点(node_id)导入槽(slot)到当前节点。
CLUSTER SETSLOT <slot> IMPORTING <node_id>
CLUSTER SETSLOT <slot> IMPORTING <node_id>从node id指定的节点中导入槽slot到本节点。
-
导入流程:在执行槽导入之前,请确保 Redis 集群处于正常工作状态,并且源节点和目标节点都在线。槽导入的流程如下:
- 源节点将指定的槽标记为正在导入(importing)状态。
- 目标节点从源节点获取该槽的键值对。
- 目标节点将该槽的键值对加入自己的数据集中。
- 源节点将该槽的导入状态(importing)更新为导入结束(stable)。
-
槽范围:Redis 集群将所有键值对分配到不同的哈希槽上。默认情况下,集群包含16384个哈希槽。
<slot>参数是一个整数,用于指定要操作的槽编号。 -
节点标识:
<node_id>参数是一个字符串,表示源节点的标识。通常,它可以是节点的 ID 或节点的 IP 地址加端口。
执行 CLUSTER SETSLOT <slot> IMPORTING <node_id> 命令的示例:
- 使用 Redis 命令行客户端连接到目标节点的 Redis 集群。
- 执行
CLUSTER SETSLOT <slot> IMPORTING <node_id>命令,将指定槽从源节点导入到当前节点。- 例如,从源节点1234567890abcdef1234567890abcdef12345678中导入槽5到当前节点:
CLUSTER SETSLOT 5 IMPORTING 1234567890abcdef1234567890abcdef12345678
- 例如,从源节点1234567890abcdef1234567890abcdef12345678中导入槽5到当前节点:
cluster setslot <slot>stable
“cluster setslot <slot> stable” 是 Redis 集群命令之一,用于将指定的槽位(slot)标记为稳定(stable)状态。
在 Redis 集群中,数据被分布在不同的槽位上。每个槽位都有一个负责人(slot owner),负责处理该槽位上的数据。当一个槽位被标记为稳定状态时,意味着该槽位的负责人已经确定,不会再发生变动。
使用 “cluster setslot <slot> stable” 命令,可以手动将一个槽位标记为稳定状态。这在某些情况下是有用的,例如当你需要手动指定槽位的负责人,或者在进行集群维护时需要暂时固定槽位的负责人。
需要注意的是,只有当槽位被标记为稳定状态后,才能进行一些特定的操作,例如迁移槽位或添加节点到集群中。
总结起来,“cluster setslot <slot> stable” 命令用于将指定的槽位标记为稳定状态,确保该槽位的负责人不会再发生变动。
键(key)
在 Redis 集群中,key 是用于标识存储在数据库中的数据的唯一标识符。每个 key 都与一个对应的值(value)相关联,所有的 key 被分布在不同的槽位(slot)上。每个槽位负责处理一部分 key。这种分布方式使得数据可以在集群中进行水平扩展,并允许集群中的多个节点共同处理请求。
在使用 Redis 集群时,需要注意以下几点:
-
key 的分布是由集群自动处理的,开发者无需手动指定 key 的槽位。
-
当执行命令时,Redis 集群会根据 key 的槽位将请求路由到正确的节点上进行处理。
-
在集群中添加或删除节点时,部分 key 可能会被重新分配到不同的槽位上,但这对于应用程序来说是透明的。
总结起来,Redis 集群中的 key 是用于标识存储在数据库中的数据的唯一标识符,它们被分布在不同的槽位上,并且可以与各种数据类型相关联。
cluster keyslot <key>
“cluster keyslot ” 是 Redis 集群命令之一,用于计算给定键(key)应该被放置在哪个槽位(slot)上。
在 Redis 集群中,数据被分布在不同的槽位上。每个槽位负责处理一部分键值对。当执行命令时,Redis 集群会根据键的槽位将请求路由到正确的节点上进行处理。
使用 “cluster keyslot <key>” 命令,可以通过计算给定键的哈希值来确定它应该被放置在哪个槽位上。这个命令对于开发者来说是有用的,因为它可以帮助他们了解给定键的分布情况,以及确定它应该被路由到哪个节点上。
注意,计算键的槽位是根据 Redis 集群的哈希槽位分配算法进行的。这个算法使用 CRC16 校验和函数对键进行哈希计算,然后将哈希值对槽位总数取模来确定槽位编号。
总结起来,“cluster keyslot <key>” 命令用于计算给定键应该被放置在哪个槽位上。它通过计算键的哈希值并使用哈希槽位分配算法来确定槽位编号。这个命令对于了解键的分布情况和路由到正确节点上是很有帮助的。
cluster countkeysinslot <slot>
cluster countkeysinslot <slot> 是一个Redis命令,用于返回指定槽位(slot)中当前包含的键值对数量。
在 Redis 集群中,数据被分布在不同的槽位上。每个槽位负责存储一部分数据。custer countkeysinslot 命令可以帮助我们查看指定槽位中当前包含的键值对数量。
使用该命令时,需要替换 <slot> 为实际的槽位号。例如,如果我们想要查看槽位号为 123 的槽位中包含的键值对数量,可以执行以下命令:
cluster countkeysinslot 123
执行该命令后,Redis 会返回槽位号为 123 的槽位中当前包含的键值对数量。这个数量可以帮助我们了解该槽位中存储的数据量,从而更好地管理和优化 Redis 集群的性能。
cluster getkeysinslot <slot> <count>
cluster getkeysinslot <slot> <count> 是一个 Redis 命令,用于返回指定槽位(slot)中的键。
在 Redis 集群中,数据被分布在不同的槽位上。每个槽位负责存储一部分数据。cluster getkeysinslot 命令可以帮助我们获取指定槽位中的键。
使用该命令时,需要替换 <slot> 为实际的槽位号,<count> 为需要返回的键的数量。例如,如果我们想要获取槽位号为 123 的槽位中的前 10 个键,可以执行以下命令:
cluster getkeysinslot 123 10
执行该命令后,Redis 会返回槽位号为 123 的槽位中的前 10 个键。这些键可以帮助我们了解该槽位中存储的具体数据,从而进行进一步的操作和分析。
注意,由于 Redis 集群的数据分布是动态的,所以在执行 cluster getkeysinslot 命令时,返回的键可能会有变化。因此,该命令主要用于调试和分析,不适合用于生产环境中的正式操作。
Redis集群总结
Redis集群提供了可靠的高可用性和扩展性,能够满足大规模分布式应用中对于高性能和数据可靠性的要求。通过节点间的数据分片、主从复制和自动迁移,Redis集群能够实现数据的平衡分布和故障恢复。
-
节点自动发现:Redis Cluster可以自动发现新加入的节点,并将其加入到集群中。当一个新的节点加入集群时,其他节点会自动感知到并进行相应的配置更新。
-
slave->master选举和集群容错:Redis Cluster支持主从复制机制,当一个主节点宕机时,集群会自动选举一个从节点作为新的主节点,以保证集群的高可用性和容错性。
-
Hot resharding:Redis Cluster支持在线分片,即在运行过程中动态地增加或减少分片。这意味着可以在不停机的情况下对集群进行扩容或缩容操作,以适应不同的负载需求。
-
进群管理:Redis Cluster提供了cluster xxx命令,用于管理集群中的节点。通过该命令,可以查看集群的状态、节点的信息、分片的分布情况等。
-
基于配置(nodes-port.conf)的集群管理:Redis Cluster使用一个配置文件(nodes-port.conf)来管理集群中的节点。该配置文件包含了集群中所有节点的信息,包括节点的IP地址、端口号、角色等。文章来源:https://www.toymoban.com/news/detail-621728.html
-
ASK转向/MOVED转向机制:当一个客户端请求的数据位于其他节点上时,Redis Cluster会返回一个ASK转向或MOVED转向的响应,告诉客户端应该去访问哪个节点来获取数据。这种机制保证了数据的一致性和高效性。文章来源地址https://www.toymoban.com/news/detail-621728.html
到了这里,关于【Redis深度专题】「核心技术提升」探究Redis服务启动的过程机制的技术原理和流程分析的指南(集群指令分析—上篇)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!