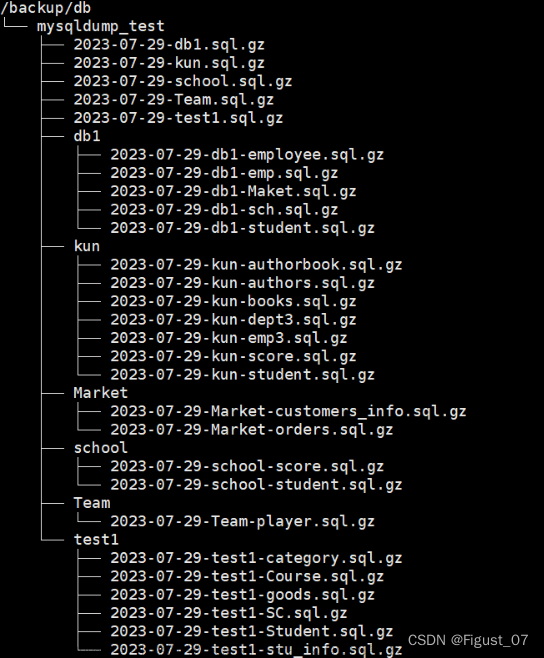
分库备份
创建脚本并编写
[root@localhost scripts]# vim bak_db_v1.sh
#!/bin/bash
备份的路径
bak_path=/backup/db
账号密码
mysql_cmd='-uroot -pRedHat@123'
需要排除的数据库
exclude_db='information_schema|mysql|performance_schema|sys'
检验备份路径是否存在,不存在则创建
[ -d ${bak_path} ] || mkdir -p ${bak_path}
提取需要备份的数据库,并将其写入文件(dbname)中
mysql ${mysql_cmd} -e 'show databases' -N | egrep -v "${exclude_db}" > dbname
循环文件,针对每个库进行备份
while read line
do
mysqldump ${mysql_cmd} -B $line | gzip > ${bak_path}/${line}_$(date +%F).sql.gz
done < dbname
删除临时文件
rm -f dbname
分表备份文章来源:https://www.toymoban.com/news/detail-621765.html
#!/bin/bash
备份的路径
bak_path=/backup/db
账号,密码
mysql_cmd='-uroot -pRedHat@123'
需要排除的数据库
exclude_db='information_schema|mysql|performance_schema|sys'
提取需要备份的数据表,并将其写入文件(tbname)中
mysql -uroot -pRedHat@123 -N -e'show tables from abc' > tbname
循环文件,针对每个表进行备份
while read line
do
将数据表放在对应的数据库下面
[ -d ${bak_path}/abc ] || mkdir -p ${bak_path}/abc
mysqldump ${mysql_cmd} abc $line | gzip > ${bak_path}/abc/abc_${line}_$(date +%F).sql.gz
done < tbname
删除临时文件
rm -f tbname文章来源地址https://www.toymoban.com/news/detail-621765.html
到了这里,关于MySQL数据库分库分表备份的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!