豆瓣网址:https://movie.douban.com/top250
1.创建scrapy框架
scrapy startproject 项目名(scrapy_test_one)
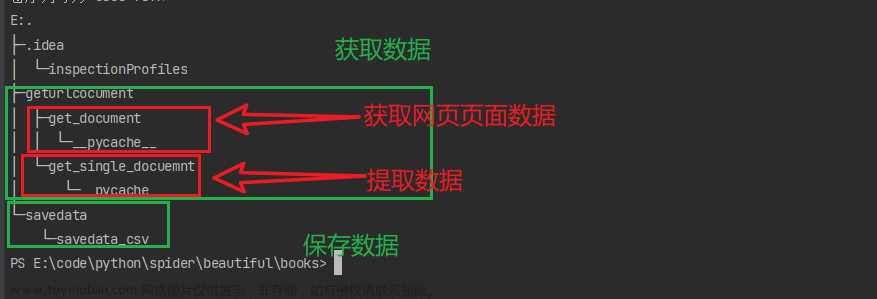
创建好以后的目录是这样的

2.创建spider文件
在spiders目录下创建一个spider_one.py文件,可以随意命名,该文件主要是让我们进行数据爬取的。
运行命令:
scrapy genspider spider_one baidu.com
注意末尾的域名是用来设置爬取的范围的
spider_one.py代码如下
import scrapy
from scrapy import Request
from scrapy_test_one.items import ScrapyTestOneItem
# from scrapy.selector import HtmlXPathSelector
class SpiderOneSpider(scrapy.Spider):
name = "spider_one"
allowed_domains = ['movie.douban.com/top250']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response, *args):
movie_items = response.xpath('//div/ol[@class="grid_view"]')
# print("======================",movie_items)
for item in movie_items:
movie = ScrapyTestOneItem()
# src = item.xpath('//li/div/div/a/img/@src').extract_first()
# print("===================",src)
# movie["img"] = src
title = item.xpath('//li/div/div[2]/div/a/span[1]/text()')
movie["title"] = title.extract()
print("=========================title=======================",title)
# movie['rank'] = item.xpath('')
# # print(movie['rank'])
# movie['title'] = item.xpath(
# 'div[@class="info"]/div[@class="hd"]/a/span[@class="title"][1]/text()').extract()
# movie['poster'] = item.xpath('div[@class="pic"]/a/img/@src').extract()
# movie['link'] = item.xpath('div[@class="info"]/div[@class="hd"]/a/@href').extract()
# movie['rating'] = item.xpath(
# 'div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract()
yield movie
3.对settings进行配置
放开useragent,配置好对应的值
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
关闭robots协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
放开管道限制
ITEM_PIPELINES = {
"scrapy_test_one.pipelines.ScrapyTestOnePipeline": 300,
}
4.配置items文件
在items.py文件中添加需要的字段文章来源:https://www.toymoban.com/news/detail-621911.html
import scrapy
class ScrapyTestOneItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
img = scrapy.Field()
title = scrapy.Field()
5.配置piplines.py文件
from itemadapter import ItemAdapter
from scrapy_test_one.items import ScrapyTestOneItem
import pymongo
host = 'localhost'
port = 27017
db_name = 'DBmovies'
class ScrapyTestOnePipeline:
def open_spider(self, spider):
# 连接数据库
self.client = pymongo.MongoClient(host=host, port=port)
self.db = self.client[db_name]
def process_item(self, item, spider):
items = dict(item)
if isinstance(items, dict):
print("============================",items)
self.collection = self.db['movies']
self.collection.insert_one(items)
# self.db["movies"].insert_one(items)
else:
return "数据格式错误"
6.所有配置完后就可以运行程序进行爬取并存储啦
运行命令:文章来源地址https://www.toymoban.com/news/detail-621911.html
scrapy crawl spider_one
到了这里,关于scrapy框架简单实现豆瓣评分爬取案例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!