散列表
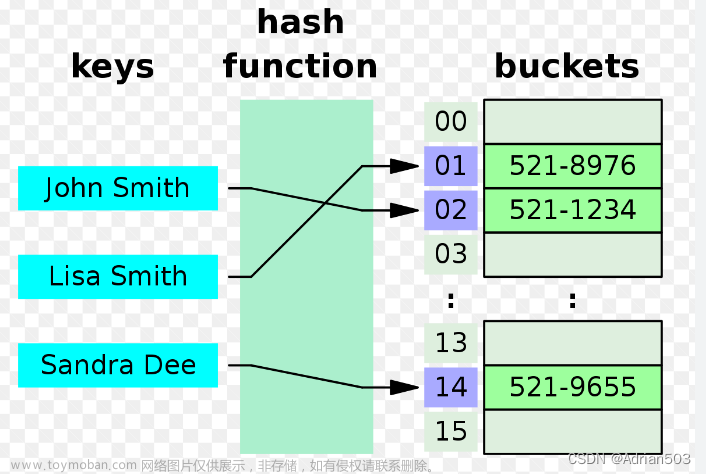
散列表(Hash Table)是一种基于散列函数(Hash Function)的数据结构,用
于实现快速的数据查找。散列函数将键(Key)映射到存储桶(Bucket)或槽位
(Slot)的位置上,以便能够快速定位到对应的值(Value)。
定义
输入:散列表(Hash Table)、待查找的键(Key)
输出:找到的值(Value)或表示键不存在的特定值(如NULL)
过程
1、根据给定的键使用散列函数计算键的散列值(Hash Value)。散列函数将键
转换为一个固定大小的整数,用于确定键在散列表中的位置。
2、使用散列值映射到散列表的索引位置。散列表通常是一个数组,每个元素代
表一个桶(Bucket),通过散列值的映射,待查找的键应该被存储在对应的桶中。
3、在散列表的索引位置上查找桶。如果桶为空,表示散列表中不存在待查找的
键,查找结束,返回表示键不存在的特定值(如NULL)。
4、如果桶不为空,可能存在冲突(多个键映射到了同一个桶),需要进行冲突解
决。常用的冲突解决方法有以下两种:
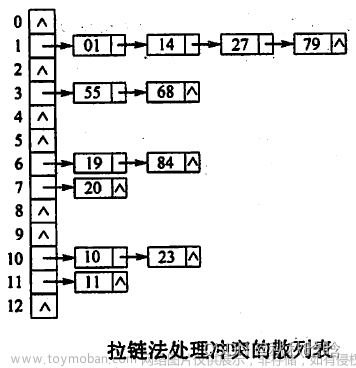
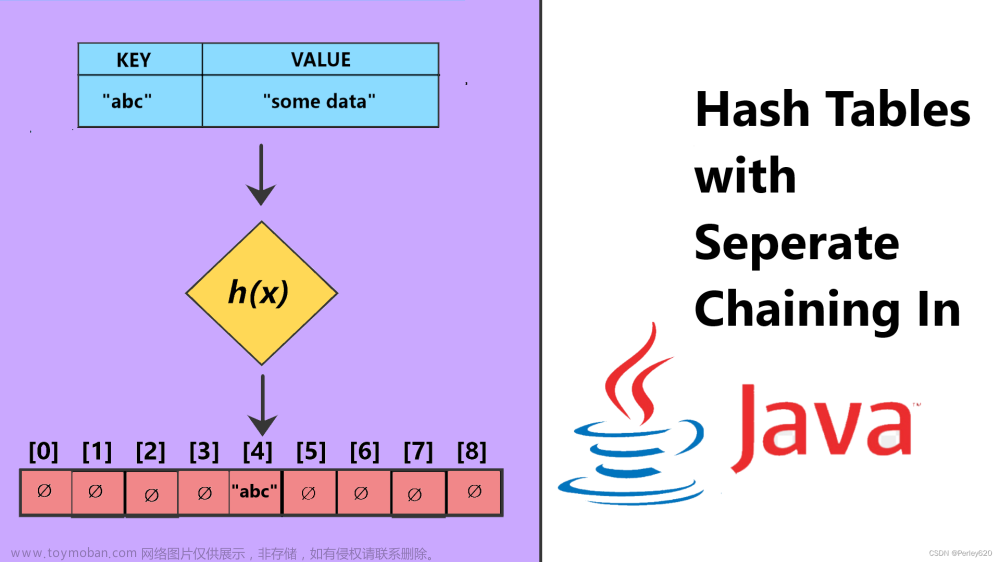
(1)链地址法(Separate Chaining):每个桶中保存一个链表,链表节点存
储冲突的键值对。在桶中搜索时,通过遍历链表来找到匹配的键值对。
(2)开放地址法(Open Addressing):在桶中直接存储冲突的键值对,当遇
到冲突时,通过探测(Probing)方法寻找下一个可用的桶。常见的探测方法有
线性探测、二次探测和双重散列等。
5、在桶中搜索待查找的键。如果找到了匹配的键,返回对应的值;如果未找到,
则继续冲突解决过程,直到找到匹配的键,或确定键不存在为止。
构造方法
直接定址法:将数据的某个固定部分作为散列地址。例如,对于整数数据,可以
将最高位或最低位作为散列地址。
数字分析法:根据对输入数据的分析,选择其中的某些位作为散列地址。例如,
对于日期数据,可以提取年份作为散列地址。
平方取中法:将数据平方后取中间的几位作为散列地址。这种方法可以减小重复
冲突的概率。
折叠法:将数据按固定位数分割,然后将这些部分相加得到散列地址。这种方法
可以在数据长度较大时减小冲突的概率。
随机数法:使用随机数生成器生成随机的散列地址。这种方法可以降低冲突的可
能性。
求余法:将数据除以散列表的大小,然后取余数作为散列地址。这是一种常用的
散列函数构造方法。
处理散列表冲突的方法
链地址法(Chaining):
实现原理:将冲突的元素存储在同一个位置的链表中。每个散列表的槽位都指
向一个链表的头节点,当发生冲突时,将新元素添加到链表的末尾。
插入操作:通过散列函数计算出元素的位置,如果该位置已经有元素存在,则
将新元素添加到链表的末尾。
查找操作:通过散列函数计算出目标元素的位置,然后遍历链表找到目标元素。
开放地址法(Open Addressing):
实现原理:当发生冲突时,通过一定的探测方式找到下一个可用的槽位。
线性探测法(Linear Probing):
当发生冲突时,线性地向后探测,直到找到一个空槽或者遍历整个散列表。
二次探测法(Quadratic Probing):
当发生冲突时,二次地向后探测,即第一次探测步长为1,第二次探测步长为2,
第三次探测步长为3,以此类推。
双重散列法(Double Hashing):
当发生冲突时,使用第二个哈希函数计算出一个步长,然后按照步长向后探测。
建立一个更大的散列表:
实现原理:当散列表的负载因子(已存储元素个数与槽位总数的比值)超过某
个阈值时,重新创建一个更大的散列表,并将原有的元素重新插入到新的散列
表中。这样可以减少冲突的概率。
再哈希法:
使用不同的哈希函数来处理冲突,当发生冲突时,再次计算哈希值,直到找到
一个空槽位。
伪随机数法:
通过伪随机数生成算法,将冲突的元素插入到散列表的不同位置,以减少冲突
的概率。
总结
每种方法都有其优缺点,选择合适的方法需要考虑散列表的具体应用场景和性能
需求。例如,链地址法适用于存储大量数据的情况,但需要额外的空间来存储链
表;开放地址法适用于空间有限的情况,但可能导致聚集现象。再哈希法和伪随
机数法可以提供较好的散列性能,但需要更复杂的实现。
算法实现
import java.util.LinkedList;
public class HashTable {
private LinkedList<Entry>[] table;
private int capacity;
private int size;
public HashTable(int capacity) {
this.capacity = capacity;
this.table = new LinkedList[capacity];
this.size = 0;
}
public void put(String key, Object value) {
int index = getIndex(key);
if (table[index] == null) {
table[index] = new LinkedList<>();
}
for (Entry entry : table[index]) {
if (entry.getKey().equals(key)) {
entry.setValue(value);
return;
}
}
table[index].add(new Entry(key, value));
size++;
}
public Object get(String key) {
int index = getIndex(key);
if (table[index] != null) {
for (Entry entry : table[index]) {
if (entry.getKey().equals(key)) {
return entry.getValue();
}
}
}
return null;
}
public void remove(String key) {
int index = getIndex(key);
if (table[index] != null) {
for (Entry entry : table[index]) {
if (entry.getKey().equals(key)) {
table[index].remove(entry);
size--;
return;
}
}
}
}
public int size() {
return size;
}
private int getIndex(String key) {
int hashCode = key.hashCode();
return Math.abs(hashCode) % capacity;
}
private class Entry {
private String key;
private Object value;
public Entry(String key, Object value) {
this.key = key;
this.value = value;
}
public String getKey() {
return key;
}
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}
}
性能分析
散列函数的设计:散列函数将关键字映射到散列表的槽位上,一个好的散列函数
能够尽可能均匀地将关键字分布到不同的槽位上,减少冲突的概率。一个较差
的散列函数可能导致冲突增加,从而降低查找性能。
负载因子:负载因子是指已存储元素个数与槽位总数的比值。负载因子较高时,
冲突的概率会增加,查找性能会下降。通常情况下,负载因子的合理范围是0.7
到0.8。
冲突处理方法:不同的冲突处理方法会对查找性能产生影响。链地址法在发生冲
突时,将冲突的元素存储在链表中,查找时需要遍历链表。开放地址法通过一
定的探测方式找到下一个可用的槽位,查找时需要按照相同的探测方式进行查
找。选择合适的冲突处理方法可以提高查找性能。
散列表的大小:散列表的大小直接影响到槽位的数量,较大的散列表可以容纳更
多的元素,减少冲突的概率。当散列表的负载因子超过一定阈值时,可以考虑
重新创建一个更大的散列表来提高查找性能。
性能总结
总体来说,散列表的查找性能是较高的,平均情况下,查找操作的时间复杂度为
O(1),即常数时间。但是在最坏情况下,如果发生大量冲突,查找操作的时间复
杂度可能会退化为O(n),其中n为散列表的大小。因此,在设计散列表时需要综
合考虑散列函数的设计、负载因子的控制以及合适的冲突处理方法,以提高查找
性能。
文章来源地址https://www.toymoban.com/news/detail-622170.html
文章来源:https://www.toymoban.com/news/detail-622170.html
到了这里,关于查找-散列表(哈希表)详解篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!