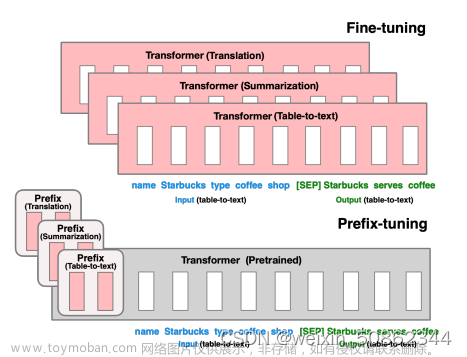
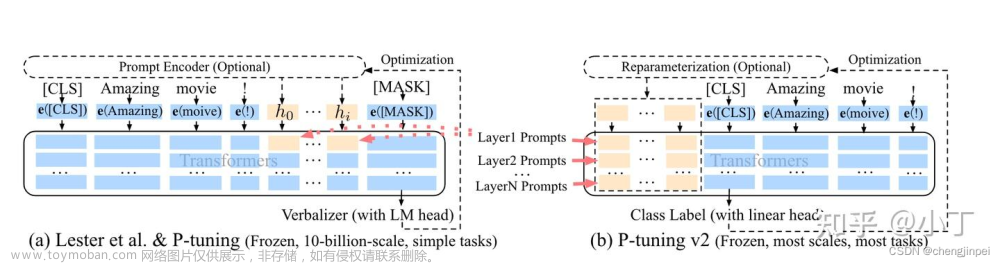
🔥 下面我只是分析讲解下这些方法的原理以及具体代码是怎么实现的,不对效果进行评价,毕竟不同任务不同数据集效果差别还是挺大的。文章来源地址https://www.toymoban.com/news/detail-622306.html
0、hard prompt & soft prompt区别
- hard prompt (离散):即人类写的自然语言式的prompt。
- soft prompt (连续):可训练的权重,可以理解为伪prompt。【毕竟nn是连续的模型,在连续空间中优化离散的prompt, 难以优化到最佳效果。额也就是说所谓的hard prompt对于人类来说好理解,但模型不一定好理解,
文章来源:https://www.toymoban.com/news/detail-622306.html
到了这里,关于LLM微调 | Prefix-Tuning, Prompt-Tuning, P-tuning, P-tuning-v2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!