前言
SD-Trainer:是stable diffusion进行lora训练的webui,有了SD-Trainer,只需要少许图片,每个人都能够方便快捷地训练出属于自 己的stable diffusion模型,可以让图片按照你的想法进行呈现。一、SD-Trainer webui使用介绍
- SD-Trainer:是stable diffusion进行lora训练的webui,有了SD-Trainer,只需要少许图片,每个人都能够方便快捷地训练出属于自 己的stable diffusion模型,可以让图片按照你的想法进行呈现。
- LoRA:英文全称Low-Rank Adaptation of Large Language Models,意为"大型语言模型的低秩自适应算法"。它是一种用于优化大型语言模型的算法,通过在训练过程中对模型进行低秩分解和自适应优化,可以显著提高语言模型的效果和性能。它是微软的研究人员为了解决大语言模型微调而开发的一项技术。
二、准备工作
2-1、登录在线训练平台
选择合适的训练平台:如果您还没有选择平台,这里我们推荐揽睿星舟平台,以下步骤以在揽睿星舟操作为例。
2-2、购买算力并创建工作空间
- 新用户拥有两个小时的免费算力,选择3090
- 镜像选择平台提供的镜像,即公有镜像-others-sd-trainer-1.1.0
- 其他默认即可


2-3、启动工作空间
- 点击启动,等待几分钟后,即可进入。
- 如果遇到网络问题,建议调试网络后选择重新启动(不会扣除费用)
- 根据个人习惯选择合适的ide,这里我选择使用vs code。


三、开始训练
3-1、打开终端
- 在打开页面后,点击Terminal-New Terminal来启动终端。

3-2、准备训练数据
训练数据:要求是若干张待训练的图片以及其描述文字,这里我们选用huggingface上的公开数据集,四张可爱狗狗的照片:https://huggingface.co/datasets/diffusers/dog-example/tree/main,也可以打开其父级目录查找其他照片组合。
注意事项:为每张图片准备一段仅一行的文本描述,存入txt或caption文件。一张图片对应一个文本文件。描述文字的命名需和 图片一致,如1.jpg的描述文字为1.caption或1.txt。
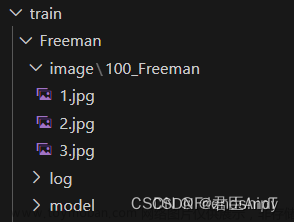
如图所示:
新建文件夹(将图片以及其描述文字放入):
mkdir -p /ark-contexts/data/sd_train_dataset/img /ark-contexts/data/sd_train_dataset/log /ark-contexts/data/sd_train_dataset/model
在img目录下新建文件,其中xx是数字,代表训练步数,XXXXX为自定义名称,本例中设为10_item,并将图片和描述文字放入该文件夹中:
cd /ark-contexts/data/sd_train_dataset/img
mkdir 10_item
把准备好的训练数据放入上述文件夹。检查最终训练数据文件夹结构为:
3-3、准备模型文件
3-3-1、模型
这里我们需要准备两个模型(先看下边的下载方法)。
-
clip-vit-large-patch14
第一个需要下载的模型 clip-vit-large-patch14,是我们需要从https://huggingface.co/openai/clip-vit-large-patch14 自行下载模型文件,上传到/ark-contexts/data/huggingface/hub/models–openai–clip-vit-large-patch14/snapshots/8d052a0f05efbaefbc9e8786ba291cfdf93e5bff 文件夹下。
最终文件夹的结构为:
-
stable-diffusion-v1-5
第二个需要下载的模型是stable-diffusion-v1-5,我们需要从https://huggingface.co/runwayml/stable-diffusion-v1-5上下载模型,
3-3-2、下载方法(以下两种方法任选一种即可)
一、直接使用命令下载(这里以clip-vit-large-patch14为例):
# 打开上图中的clone repository后,有如下命令
git lfs install
# 先安装好lfs,后边如果这一句报错可能是没有+sudo。
git clone https://huggingface.co/openai/clip-vit-large-patch14
注意:这里没有lfs,需要自行安装
- 使用lscpu命令查看架构。

- 下载对应的版本https://github.com/git-lfs/git-lfs/releases,下拉找到对应版本。


- 下载安装包后上传到服务器上并且进行解压(小文件直接拖拽上传即可,大文件需要在安装好lfs后再进行安装)
tar -zxvf git-lfs-linux-amd64-v2.9.0.tar.gz
- 解压后打开文件夹,使用命令执行安装文件
sudo ./install.sh
二、使用网盘来从本地上传(针对大文件上传)
参考官方文档:https://paritybit-us.gitbook.io/lan-rui-xing-zhou/yong-hu-shou-ce/zui-jia-shi-jian/shang-chuan-wang-pan-de-xiao-miao-zhao这里需要注意的是,记得更改端口号为443。
3-4、启动SD-Trainer
cd /app/lora-scripts
sudo sh run_gui.sh --host 0.0.0.0 --port 27777 --tensorboard-host 0.0.0.0
运行成功后我们需要在工作空间复制调试地址,在浏览器粘贴地址并且跳转,就可以进入训练界面了。
3-5、开始训练
训练界面如下所示,可以选择新手或专家两种模式,新手模式暴露的参数更少。本例使用专家模式:需要修改的参数为:
-
底模路径:使用的是我们刚才下载的模型stable-diffusion-v1-5中的文件v1-5-pruned.ckpt,我这里的路径是/ark-contexts/data/sd_train_dataset/v1-5-pruned.ckpt
-
train_data_dir:使用到的是训练数据集的路径,我这里的路径是/ark-contexts/data/sd_train_dataset/img

-
模型保存名称(可选):更改模型名称
-
模型保存路径(可选):更改模型保存路径

其他配置自行选择,配置完成后,可以点击开始训练,我们可以在之前的终端中监控模型的训练结果。
训练过程中可能会遇到的问题: -
文件夹中没有模型:检查设置的文件夹中是否存在对应模型
-
模型没有下载完全:可能是没有安装lfs导致的,Git LFS (Large File Storage) - 是Git源代码管理系统的一个扩展程序,可处理大型二进制文件的版本控制,在传输大型文件时需要首先安装lfs。

如图所示即为训练后的模型,模型保存在当前目录下的./output/aki.safetensors
总结:折腾的时间比我想象的长,但比起自己部署整个环境,云端训推还是香啊,想练练手的可以试试先薅个2小时羊毛注册链接文章来源:https://www.toymoban.com/news/detail-622401.html
参考文章:
linux安装git lfs
git-lfs
stable-diffusion-v1-5
参考B站Up文章来源地址https://www.toymoban.com/news/detail-622401.html
到了这里,关于【AI绘画】《超入门级教程:训练自己的LORA模型》,MM超爱的萌宠图片实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!