作者:禅与计算机程序设计艺术文章来源地址https://www.toymoban.com/news/detail-622439.html
文章来源:https://www.toymoban.com/news/detail-622439.html
到了这里,关于深度剖析生成式预训练Transformer:用于语音识别的示例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
这篇具有很好参考价值的文章主要介绍了深度剖析生成式预训练Transformer:用于语音识别的示例。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
作者:禅与计算机程序设计艺术文章来源地址https://www.toymoban.com/news/detail-622439.html
文章来源:https://www.toymoban.com/news/detail-622439.html
到了这里,关于深度剖析生成式预训练Transformer:用于语音识别的示例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!

在这项工作中,我们解决了引用分割的挑战性任务。引用分割中的查询表达式通常通过描述目标对象与其他对象的关系来表示目标对象。因此,为了在图像中的所有实例中找到目标实例,模型必须对整个图像有一个整体的理解。为了实现这一点,我们 将引用分割重新定义为直

本篇学习记录主要包括:《Python深度学习》的第5章(深度学习用于计算机视觉)的第3节(使用预训练的卷积神经网络)内容。 相关知识点: 预训练模型的复用方法; 预训练网络 (pretrained network) 是一个保存好的网络,之前已经在大型数据集上完成训练。理论上数据集足够大

GPT(Generative Pre-trained Transformer)模型是一种深度学习模型,由OpenAI于2018年首次提出,并在随后的几年中不断迭代发展,包括GPT-2、GPT-3以及最新的GPT-4。GPT模型在自然语言处理(NLP)领域取得了显著成果,特别是在语言生成、文本理解、问答系统、代码编写等方面表现出强大

本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处 标题: Large Scale GAN Training for High Fidelity Natural Image Synthesis 链接:[1809.11096] Large Scale GAN Training for High Fidelity Natural Image Synthesis (arxiv.org) 尽管在生成图像建模方面取得了近期的进展,但成功地从诸如ImageNet之类的复

VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种结合变分推理(variational inference)、标准化流(normalizing flows)和对抗训练的高表现力语音合成模型。 VITS模型是韩国科学院在2021年6月提出的,VITS通过隐变量而非频谱串联起来语

本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处 标题: Large Scale GAN Training for High Fidelity Natural Image Synthesis 链接:[1809.11096] Large Scale GAN Training for High Fidelity Natural Image Synthesis (arxiv.org) 尽管在生成图像建模方面取得了近期的进展,但成功地从诸如ImageNet之类的复
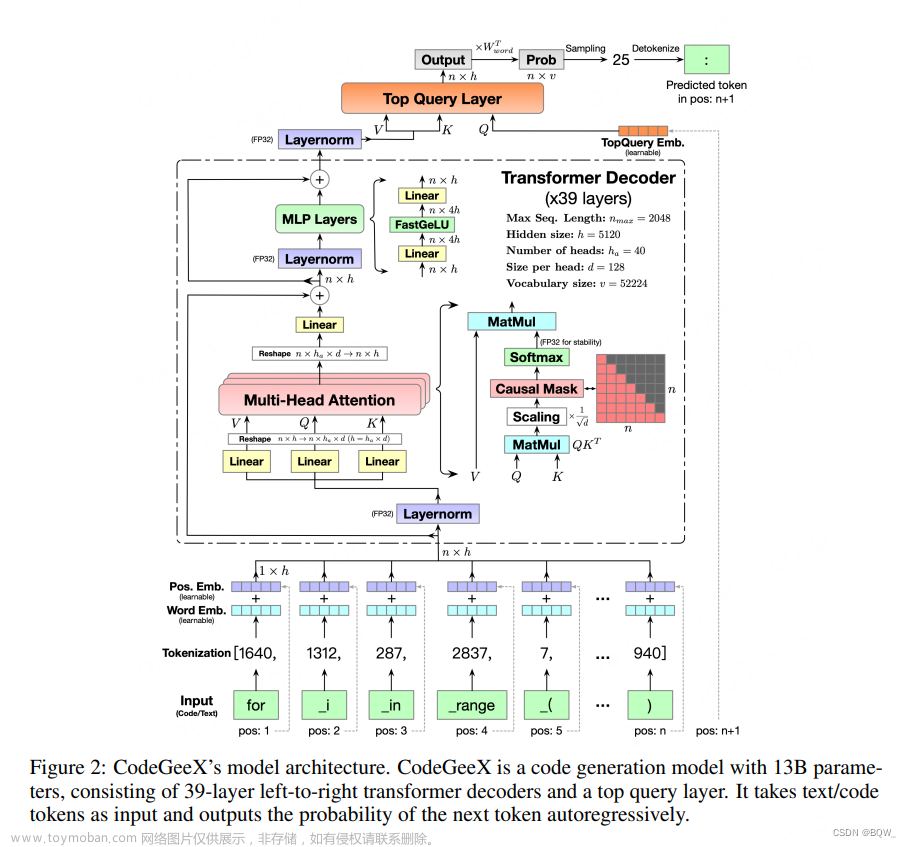
CodeGeeX:用于代码生成的多语言预训练模型 《CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X》 论文地址:https://arxiv.org/pdf/2303.17568.pdf 相关博客 【自然语言处理】【大模型】RWKV:基于RNN的LLM 【自然语言处理】【大模型】CodeGen:一个用于多轮程序合成

将CNN和GAN结合起来,把监督学习和无监督学习结合起来。具体解释可以参见 深度卷积对抗生成网络(DCGAN) DCGAN的生成器结构: 图片来源:https://arxiv.org/abs/1511.06434 model.py 训练使用的数据集:CelebA dataset (Images Only) 总共1.3GB的图片,使用方法,将其解压到当前目录 图片如下图所
以下以GRU为例讲解RNN作为解码器时如何根据用户、商品特征信息 hidden 生成评价。 解码器部分代码如下: 在训练时,解码器会有两个输入:一是编码器提取的用户、商品特征,二是用户对商品的评价。 评价是文字,在训练开始前已经转换成了Token ID, 比如 I love this item , 每个

今天小陶在训练CGAN的时候出现了绷不住的情况,那就是G_loss(生成器的loss值)一路狂飙,一直上升到了6才逐渐平稳。而D_loss(判别器的loss值)却越来越小,具体的情况就看下面的图片吧。其实这在GAN训练里是非常容易遇到的问题,所以不用慌,是有解决的办法的。小陶就通



