- TensorFlow是由谷歌开发的
- PyTorch是由Facebook人工智能研究院(Facebook AI Research)开发的
Torch和cuda版本的对应,手动安装较好
全连接FC(Batch*Num)
搭建建议网络:
from torch import nn
class Mnist_NN(nn.Module):
def __init__(self):
super().__init__()
self.hidden1 = nn.Linear(784, 128)
self.hidden2 = nn.Linear(128, 256)
self.out = nn.Linear(256, 10)
def forward(self, x):
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
x = self.out(x)
return x
封装数据
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
def get_data(train_ds, valid_ds, bs):
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
训练模型:
import numpy as np
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
for step in range(steps):
model.train()
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt)
model.eval()
with torch.no_grad():
losses, nums = zip(
*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl]
)
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)
print('当前step:'+str(step), '验证集损失:'+str(val_loss))
一般在训练模型时加上model.train(),这样会正常使用Batch Normalization和 Dropout;测试的时候一般选择model.eval(),这样就不会使用Batch Normalization和 Dropout
批量损失函数
from torch import optim
def get_model():
model = Mnist_NN()
return model, optim.SGD(model.parameters(), lr=0.001)
def loss_batch(model, loss_func, xb, yb, opt=None):
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
return loss.item(), len(xb)
优化器
SGD是一种简单且易于实现的优化算法,但在大规模数据集和复杂模型上收敛缓慢。
Adam是一种自适应学习率调整的优化算法,能够更快地收敛,但可能会占用更多的内存。
在实践中,根据具体问题和数据集的特点,选择适合的优化算法可以提高训练效果。
卷积神经网络CNN(Batch * C * H * W)
Channel First
引入py库
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets,transforms
import matplotlib.pyplot as plt
import numpy as np
预处理
# 定义超参数
input_size = 28 #图像的总尺寸28*28
num_classes = 10 #标签的种类数
num_epochs = 3 #训练的总循环周期
batch_size = 64 #一个撮(批次)的大小,64张图片
# 训练集
train_dataset = datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
# 测试集
test_dataset = datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
# 构建batch数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True)
构建CNN
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28)
nn.Conv2d(
in_channels=1, # 灰度图
out_channels=16, # 要得到几多少个特征图
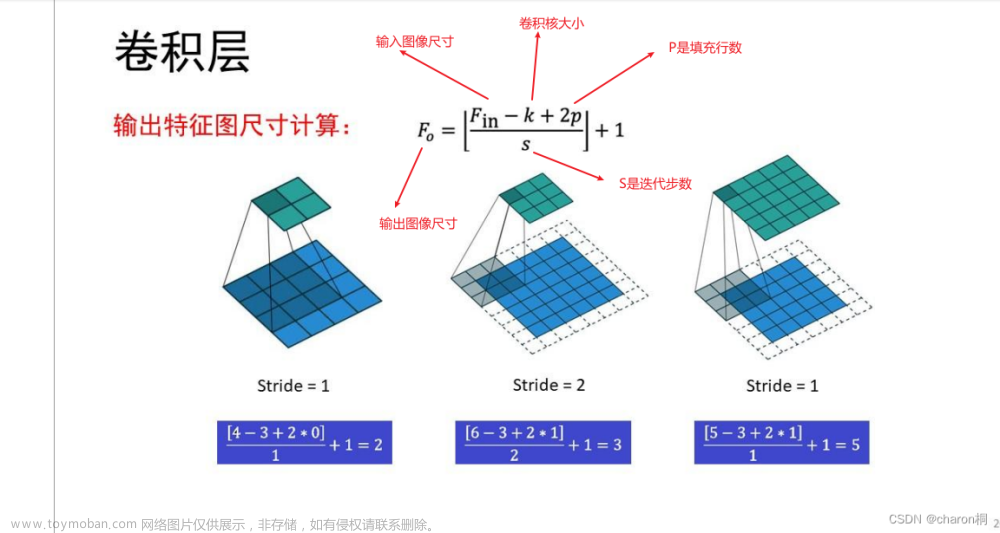
kernel_size=5, # 卷积核大小
stride=1, # 步长
padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1
), # 输出的特征图为 (16, 28, 28)
nn.ReLU(), # relu层
nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14)
)
self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14)
nn.ReLU(), # relu层
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2), # 输出 (32, 7, 7)
)
self.conv3 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)
nn.Conv2d(32, 64, 5, 1, 2), # 输出 (32, 14, 14)
nn.ReLU(), # 输出 (32, 7, 7)
)
self.out = nn.Linear(64 * 7 * 7, 10) # 全连接层得到的结果
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7)
output = self.out(x)
return output
定义准确率文章来源:https://www.toymoban.com/news/detail-622656.html
def accuracy(predictions, labels):
pred = torch.max(predictions.data, 1)[1]
rights = pred.eq(labels.data.view_as(pred)).sum()
return rights, len(labels)
训练网络模型文章来源地址https://www.toymoban.com/news/detail-622656.html
# 实例化
net = CNN()
#损失函数
criterion = nn.CrossEntropyLoss()
#优化器
optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,普通的随机梯度下降算法
#开始训练循环
for epoch in range(num_epochs):
#当前epoch的结果保存下来
train_rights = []
for batch_idx, (data, target) in enumerate(train_loader): #针对容器中的每一个批进行循环
net.train()
output = net(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right = accuracy(output, target)
train_rights.append(right)
if batch_idx % 100 == 0:
net.eval()
val_rights = []
for (data, target) in test_loader:
output = net(data)
right = accuracy(output, target)
val_rights.append(right)
#准确率计算
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(
epoch, batch_idx * batch_size, len(train_loader.dataset),
100. * batch_idx / len(train_loader),
loss.data,
100. * train_r[0].numpy() / train_r[1],
100. * val_r[0].numpy() / val_r[1]))
到了这里,关于深度学习中简易FC和CNN搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[当人工智能遇上安全] 13.威胁情报实体识别 (3)利用keras构建CNN-BiLSTM-ATT-CRF实体识别模型](https://imgs.yssmx.com/Uploads/2024/04/855121-1.png)





