2020 年我有幸加入腾讯 tdmq 初创团队,当时 tdmq 还正在上云公测阶段,我第一次从一个使用工具的人转变成了开发工具的人,
这个过程使我沉淀了很多消息队列知识与设计艺术。
后来在业务中台的实践中,也频繁地使用到了 MQ,比如最常见的消息推送,异常信息的重试等等,
过程中也对消息队列有了更加深刻的了解。
此篇文章,我会站在一个时间维度的视角上去讲解这二十年每款 MQ 诞生的背景以及解决了何种问题。1. 消息队列发展历程
2003 至今有很多优秀的消息队列诞生,其中就有被大家所熟知的就是 kafka、阿里自研的 rocketmq、以及后起之秀 pulsar。首先我们先来了解一下每一时期消息队列诞生的背景以及要解决的核心问题是什么?

如图所示,我把消息队列的发展切分成了三个大的阶段。
第一阶段:解耦合
就是从 2003 年到 2010 年之前,03 年可以说计算机软件行业刚刚兴起,解决系统间强耦合变成了程序设计的一大难题,这一阶段以 activemq 和 rabbitmq 为主的消息队列致力于解决系统间解耦合和一些异步化的操作的问题,这也是所有消息队列被使用的最多的功能之一。
第二阶段:吞吐量与一致性
在 2010 年到 2012 年期间,大数据时代正式到来,实时计算的需求越来越高,数据规模也越来越大。由于传统消息队列已无法满足大数据的需求,消息队列设计的关键因素逐渐转向为吞吐量和并发程度。在这一背景下,Kafka 应运而生,并在日志收集和数据通道领域占据了重要地位。
然而,随着阿里电商业务的兴起,Kafka 在可靠性、一致性、顺序消息、事务消息支持等方面已经无法满足阿里电商场景的需求。因此,RocketMQ 诞生了,阿里在自研消息队列的过程中吸收了 Kafka 的很多设计理念,如顺序写盘、零拷贝、end-to-end 压缩方式,并在此基础上解决了 Kafka 的一些痛点问题,比如强依赖 Zookeeper。后来,阿里将 RocketMQ 捐赠给了 Apache,并最终成为了 Apache RocketMQ。
第三阶段:平台化
"没有平台的产品是没用的,再精确一点,去平台化的产品总是被平台化的产品所取代" 这句话并不是我说的,而是来自一篇来自 2011 年的文章《steve 对亚马逊和 google 的吐槽》( https://coolshell.cn/articles/5701.html 推荐阅读)。
2012 以后,随着云计算、k8s、容器化等新兴的技术兴起,如何把基本底层技术能力平台化成为了众多公司的攻坚方向,阿里云、腾讯云、华为云的入场都证明了这点,在这种大背景下,Pulasr 诞生了。
雅虎起初启动 pulsar 项目是为了解决以下三个问题:
-
公司内部多团队重复建造轮子。
-
当前主流 mq 的租户隔离机制都支持的不是很好。
-
数据迁移、恢复、故障转移个个都是头疼的问题,消息队列运维成本极高。
这三个问题的答案都指向了一个方向:平台化。
2. 消息队列的通用架构及基本概念
第一节我们从时间线上介绍了主流的消息队列产生的背景,这一小节我们先从生活场景入手,理解消息队列最最基本的概念,
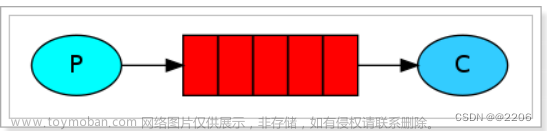
主题(topic)生产者(producer)消费者(consumer)
场景:食堂吃饭
我们可以把吃饭抽象成三步
-
第一步:当你进入饭堂,首先你想的是我今天吃什么,选择合适的档口,比如有米饭、有面、有麻辣香锅。这里的米饭、面、麻辣香锅就是 topic 主题的概念 -
第二步:当你选择了面档,下一步就是排队,排队默认的就是站在一个队伍的队尾,你加入队伍的这一过程统称为入队,此时对于 MQ 则是成功生产了一条消息。 -
第三步:经过了等待,终于排到了你,并把饭菜成功拿走。这个过程称为出队,档口相当于消费者,消费了"你"这一条信息。
通过这个例子,你可以很好的理解,主题(topic)、生产者(producer)、消费者(consumer)这三个概念。
分区(partition)
分区概念是计算机世界对真实世界很好的一层抽象,理解了分区,对于理解消息队列极其重要。如果你申请过云上的消息队列,平台会让你填写一个分区大小的参数选项,那分区到底是什么意思,我们接着向下看。
我们还是举学习食堂的例子,假如有一天学校大面积扩招,一下次多来了一万名学生,想象一下,你每次去食堂吃面,排上喜欢吃的东西,估计要等个一个小时,学校肯定也会想办法,很简单,就是把一个档口变成多个档口,对食堂进行扩建(扩容)。扩容前,卖面的档口只有一个,人多人少你都要排队。扩容后,你只要选择(路由)一个人少的档口就 ok。这里多个队伍就是多个分区。当理解了分区,就可以很好理解:分区使得消息队列的写吞吐量有了横向扩展的能力,这里也是 kafka 为什么可以高吞吐的本质原因。
3. 主流消息队列存储分析
特性与性能是存储结构的一种显化表现。特性是表相,存储才是本质。我们要搞清楚每款消息的特性,很有必要去了解它们在架构上的设计。这章节,我们先会去介绍 kafka、rocketmq、pulsar 各自的架构特点,然后再去对比架构上的不同带来了什么功能上的不同。
3.1. kafka
架构图
对于 kafka 架构,需要首先说明的一点,kafka 的服务节点并没有主从之分,主从的概念是针对 topic 下的某个 partition。对于存储的单位,宏观上来说就是分区,通过分区散落在各个节点的方式的不同,可以组合出各种各样的架构图。以下是生产者数量为 1 消费者数量为 1 分区数为 2 副本数为 3 服务节点数为 3 架构图。图中两块绿色图案分别为 topic1-partition1 分区和 topic1-partition2 分区,浅绿色方块为他们的副本,此时对于服务节点 1 topic1-partition1 就是主节点,服务节点 2 和 3 为从节点;但是对于服务节点 2 topic1-partition2 有是主分区,服务节点 1 和服务节点 3 变成了从节点。讲到这里,想必你已经对主从架构有了一个进一步的理解。

我们先来看看消息队列的大致工作流程。
-
生产者 、消费者首先会和元数据中心(zookeeper)建立连接、并保持心跳,获取服务的实况以及路由信息。 -
消息会被 send 到 topic 下的任一分区中(这里通过算法会保证每个 topic 下的分区尽可能均匀),一般情况下,信息需要落盘才可以给上游返回 ack,保证了宕机后的信息的完整性。在信息写成功主分区后,系统会根据策略,选择同步复制还是异步复制,以保证单节点故障时的信息完整性。 -
消费者此时开始工作,拉取响应的信息,并返回 ack,此时 offset+1。
好的设计
下来我们来了解一下 kafka 架构优秀的设计理念。
-
磁盘顺序写盘。
Kafka 在底层设计上强依赖于文件系统(一个分区对应一个文件系统),本质上是基于磁盘存储的消息队列,在我们固有印象中磁盘的读写速度是非常慢的,慢的原因是因为在读写的过程中所有的进程都在抢占“磁头”这把锁,磁头在读写之前需要将其移动到合适的位置,这个“移动”极其耗费时间,这也就是磁盘慢的原因,但是如何不用移动磁头呢,顺序写盘就诞生了。
Kafka 消息存储在分区中,每个分区对应一组连续的物理空间。新消息追加到磁盘文件末尾。消费者按顺序拉取分区数据消费。Kafka 的读写是顺序的,可以高效地利用 PageCache,解决磁盘读写的性能问题。
以下是一张磁盘、ssd、内存的写入性能对比图,我们可以明显的看出顺序写入的性能快于 ssd 的顺序/随机写,与内存的顺序/随机性能也相差不大,这一特性非常重要,很多组件的底层存储设计都会用到这点,理解好这点对理解消息队列尤为重要。(推荐阅读《 The Pathologies of Big Data 》 https://queue.acm.org/detail.cfm?id=1563874 ))

一些问题
任何事物都有两面性,顺序写盘的设计也带来一些其他的问题。
-
topic 数量不能过大
kafka 的整体性能收到了 topic 数量的限制,这和底层的存储有密不可分的关系,我们上面讲过,当消息来的时候,底层数据使用追加写入的方式,顺序写盘,使得整体的写性能大大提高,但这并不能代表所有情况,当我们 topic 数量从几个变成上千个的时候,情况就有所不同了,如下图所示。

以上左图代表了,队列中从头到尾的信息为:topic1、topic1、topic1、topic2,在这种情况下,很好地运用了顺序写盘的特性,磁头不用去移动,但是对于右边图的情况,队列中从头到尾的信息为:topic1、topic2、topic3、topic4,当队列中的信息变的很分散的时候,这个时候我们会发现,似乎没有办法利用磁盘的顺序写盘的特性,因为每次写完一种信息,磁头都需要进行移动,读到这里,你就很好理解,为什么当 topic 数量很大时,kafka 的性能会急剧下降了。
当然会有小伙伴问,没有其他办法了吗,当然有。我们可以把存储换成速度更快 ssd 或者针对每一个分区都搞一块磁盘,当然这都是钱!很多时候,系统的 6 个 9、7 个 9,并不是有多好的设计,而是用真金白银换来的,这是一种 trade off,失去什么得到什么,大家可以对比看看自己的系统,大多数情况是什么换什么。
3.2. rocketmq
架构图
以下是 rocketmq 双主双从的架构,对比 kafka,rocketmq 有两点很大的不同:
-
元数据管理系统,从 zookeeper 变成了轻量级的独立服务集群。 -
服务节点变为 多主多从架构。

zookeeper 与 namesrv
kafka 使用的 zookeeper 是 cp 强一致架构的一种,其内部使用 zab 算法,进行信息同步和容灾,在信息量较小的情况下,性能较好,当信息交互变多,因为同步带来的性能损耗加大,性能和吞吐量降低。如果 zookeeper 宕机,会导致整个集群的不可用,对于一些交易场景,这是不可接受的,为了提高大数据场景下,消息发现系统的可用性与整体的吞吐量,相比 zookeeper,rocketmq 选择了轻量级的独立服务器 namesrv,其有以下特点:
-
使用简单的 k/v 结构保存信息。 -
支持集群模式,每个 namesrv 相互独立,不进行任何通信。 -
数据都保存在内存当中,broker 的注册过程通过循环遍历所有 namesrv 进行注册。
局部顺序写(kafka) 与 完全顺序写(rocketmq)
kafka 写流程中会把不同分区写入对应的文件系统中,其设计理念保证了 kafka 优秀的水平扩容能力。RocketMQ 的设计理念则是追求极致的消息写,将所有的 topic 消息存储在同一个文件中,确保所有消息发送时按顺序写文件,尽最大能力确保消息发送的高可用性与高吞吐量,但是有利有弊,这种 topic 共用文件的设计会使得 rocketmq 不支持删除指定 topic 功能,这也很好理解,对于某个 topic 的信息,在磁盘上的表现是一段非连续的区域,而不像 kafka,一个 topic 就是一段连续的区域。如下图所示。

rocketmq 存储结构
下面我们来重点介绍 rocketmq 的存储结构,通过对存储结构的了解,你将会更好的对读写性能有一个更深的认识。
不同 topic 共用一个文件的模式带来了高效的写性能,但是单看某一 topic 的信息,相对于磁盘上的表现为非连续的若干片段,这样使得定位指定 topic 下 msg 的信息,变成了一个棘手的问题。
rocketmq 在生产过程中会把所有的 topic 信息顺序写入 commitlog 文件中,消费过程中,使用 ConsumeQueue、IndexFile 索引文件实现数据的高效率读取。下面我们重点介绍这三类文件。
-
Commitlog
从物理结构上来看,所有的消息都存储在 CommitLog 里面,单个 CommitLog 文件大小默认 1G,文件名长度为 20 位,左边补零,剩余为起始偏移量。
比如 00000000000000000000 代表了第一个文件,起始偏移量为 0 文件大小为 1G=1073741824;当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件。CommitLog 顺序写,可以大大提高写入效率。
-
ConsumeQueue (索引文件 1)
ConsumeQueue 文件可以看成是基于 topic 的 commitlog 索引文件。Consumer 即可根据 ConsumeQueue 来查找待消费的消息。
因为 ConsumeQueue 里只存偏移量信息,大部分的 ConsumeQueue 能够被全部读入内存,速度极快。在定位 msg 信息时直接读取偏移量,在 commitlog 文件中使用二分查找到对应的全量信息即可。
-
IndexFile(索引文件 2)
IndexFile 是另一种可选索引文件,提供了一种可以通过 key 或时间区间来查询消息的方法。IndexFile 索引文件其底层实现为 hash 索引,Java 的 HashMap,可以快速通过 key 找到对应的 value。
讲到这里,我们在想想 kafka 是怎么做的,对的,kafka 并没有类似的烦恼,因为所有信息都是连续的!以下是文件在目录下的存储示意图。

3.3. pulsa
架构图(分层+分片)

pulsar 相比与 kafka 与 rocketmq 最大的特点则是使用了分层和分片的架构,回想一下 kafka 与 rocketmq,一个服务节点即是计算节点也是服务节点,节点有状态使得平台化、容器化困难、数据迁移、数据扩缩容等运维工作都变的复杂且困难。
分层:Pulsar 分离出了 Broker(服务层)和 Bookie(存储层)架构,Broker 为无状态服务,用于发布和消费消息,而 BookKeeper 专注于存储。
分片 : 这种将存储从消息服务中抽离出来,使用更细粒度的分片(Segment)替代粗粒度的分区(Partition),为 Pulsar 提供了更高的可用性,更灵活的扩展能力。
服务层设计
Broker 集群在 Pulsar 中形成无状态服务层。服务层是“无状态的”,所有的数据信息都存储在了 BookKeeper 上,所有的元信息都存储在了 zookeeper 上,这样使得一个 broker 节点没有任何的负担,这里的负担有几层含义:
-
容器化没负担,broker 节点不用考虑任何数据状态带来的麻烦。 -
扩容、缩容没负担,当请求量级突增或者降低的同时,可以随时的添加节点或者减少节点以动态的调整资源,使得整体在一种“合适”的状态。 -
故障转移没负担,当一个节点宕机、服务不可用时,可以通快速地转移所负责的 topic 信息到别的基节点上,可以很好做到故障对外无感知。

存储层设计
pulsar 使用了类似于 raft 的存储方案,数据会并发的写入多个存储节点上,下图为四存储节点、三副本架构。

broker2 节点当前需要写入 segment1 到 segment4 数据,流程为:segment1 并发写入 b1、b2、b3 数据节点、segment2 并发写入 b2、b3、b4 数据节点、segment3 并发写入 b3、b4、b1 数据节点、segment4 并发写入 b1、b2、b4 数据节点。这种写入方式称为条带化的写入方式、这种方式潜在的决定了数据的分布方式、通过路由算法,可以很快的找到对应数据的位置信息,在数据迁移与恢复中起到重要的作用。
扩容
当存储节点资源不足的时候,常规的运维操作就是动态扩容,相比 kafka 与 rocketmq、pulsar 不用考虑原数据的"人为"搬移工作,而是动态新增一个或者多个节点,broker 在写入数据时通过路有算法优先写入资源充足的节点,使得整体的资源利用力达到一个平衡的状态,如图所示。

以下是一张 kafka 分区和 pulsar 分片的一张对比图,左图是 kafka 的数据存储特点,因为数据和分区的强绑定,导致了第三艘小船没有任何的数据,而相比 pulsar,数据不和任何存储节点绑定,而是实时的动态写入,从数据分布和资源利用来说,要做的更好。

容灾
当 bookie4 存储节点宕机不可用时,如何恢复节点数据?这里只需要增加新的存储节点,并且拷贝 bookie2 与 bookie3 上的数据即可,这个过程对外是无感知的,实现了平滑切换,如图所示。

4. 一些想法
纵观消息队列的发展、技术的革新总是解决了某些问题、每种设计的背后都有着一种天然的平衡 ,无论优劣,针对不同的场景,选择不同的产品,才是王道。文章来源:https://www.toymoban.com/news/detail-622699.html
作者:blithe文章来源地址https://www.toymoban.com/news/detail-622699.html
到了这里,关于消息队列二十年的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!