#!/bin/bash
#########################
#File name:db_fen.sh
#Version:v1.0
#Email:admin@test.com
#Created time:2023-07-29 09:18:52
#Description:
#########################
# MySQL连接信息
db_user="root"
db_password="RedHat@123"
db_cmd="-u${db_user} -p${db_password}"
exclude_db="information_schema|mysql|performance_schema|sys|Database"
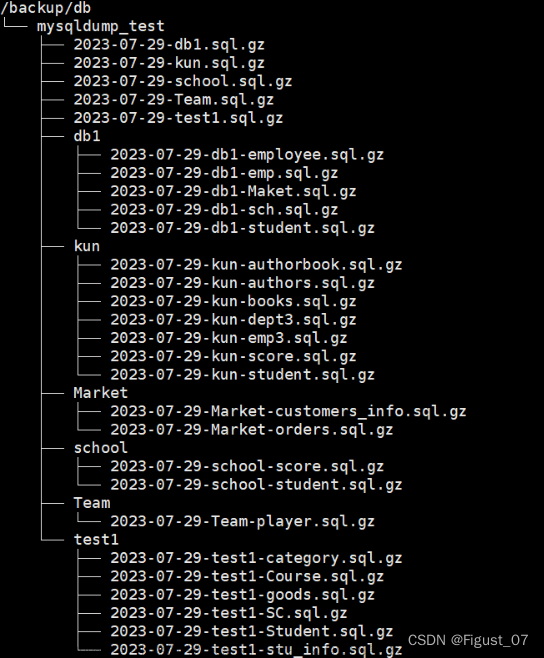
bak_dir=/backup/db/mysqldump_test/
# 判断备份路径是否存在
[ -d ${bak_dir} ] || mkdir ${bak_dir}
# 查找出需要备份的数据库
mysql ${db_cmd} -e"show databases" -N 2>/dev/null | egrep -v "$exclude_db" > dbtmp
# 循环遍历数据库列表
while read db
do
#对数据库进行备份
mysqldump ${db_cmd} --set-gtid-purged=off $db 2>/dev/null | gzip > ${bak_dir}/`date +%F`-$db.sql.gz
#判断是否备份成功
if [ $? -eq 0 ]
then
echo "database $db is being backed up ... success!"
else
echo "database $db is being backed up ... failure!"
fi
#根据数据库进行分表备份
[ -d ${bak_dir}/$db ] || mkdir -p ${bak_dir}/$db
# 获取数据库中的表名列表
mysql ${db_cmd} $db -e "SHOW TABLES;" | grep -v "Tables_in" > tbtmp
# 循环遍历表名列表
while read tb
do
# 对表进行备份
mysqldump ${db_cmd} --set-gtid-purged=off $db $tb 2>/dev/null | gzip > ${bak_dir}/$db/`date +%F`-$db-$tb.sql.gz
# 判断是否备份成功
if [ "$?" -eq 0 ]; then
echo "Backup of $db.$tb successful!"
else
echo "Backup of $db.$tb failed!"
fi
done < tbtmp
done < dbtmp
#删除临时文件
rm -rf tbtmp
rm -rf dbtmp 文章来源:https://www.toymoban.com/news/detail-622706.html
文章来源:https://www.toymoban.com/news/detail-622706.html
文章来源地址https://www.toymoban.com/news/detail-622706.html
到了这里,关于数据库的分库分表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!