华中杯C题:空气质量预测
问题一:
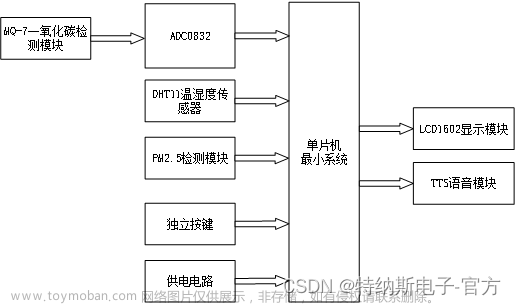
根据附件 1和附件 2,对数据进行分析和处理,筛选出与 PM2.5 浓度变化有关的因素,并说明筛选出的因素对 PM2.5 浓度影响的程度。
| 这道题其实比较简单,主要是做相关性影响分析,这里我讲两种做法,第一种做法比较简单,我们可以通过常规的统计学模型来进行分析,例如说做相关性分析,差异性分析等等,这里差异性分析可以举一个例子,例如说基于PM2.5浓度,我们可以用配对样本t检验研究他跟其他样本的是否存在差异以及其程度。第二种做法就比较炫技了,我们可以先构建一个机器学习模型,例如Xgboost.模型对PM2.5浓度进行预测,将其他相关影响的因素作为模型的输入变量,通过调参交叉验证得到最优的xgboost模型,这里我们可以采用一些启发式算法,例如说pso,遗传算法等等,然后我们再通过shap模型计算每个特征对模型的贡献程度,可视化特征重要性。另外我们也可以先用第二种方式研究各个变量的特征重要性,然后再用第一种方式去研究不同变量它们之间的差异情况 |



问题二:
自行划分训练集和测试集,根据附件 1和附件 2,基于问题一构建 PM2.5 浓度多步预测模型,分别使用均方根误差 (RMSE) 对 3 步、5 步、7步、12 步预测效果进行评估,其结果请用表 1格式在正文中具体给出,并对测试集及其预测结果进行可视化同时,用该模型预测附件 3 所给定时间的 PM2.5 浓度,其结果请用表 2格式在正文中具体给出。
| 第二问的话,我们可以采用时间序列分析,他这里的多部其实指的就是时间滑动预测窗口的步阶,一般来说做时间序列分析有两种做法,一种是传统的arima.模型或灰色预测模型,他们就是很正统的单序列时间预测。但是其实在工业界用的更火的一种是回归模型预测,这种做法其实就是对数据进行了时间窗口滑动处理,简单说,例如步阶设置为1,那么就是用第一天的数据预测第二天,第二天的数据预测第三天,第三天的数据预测第四天。以此类推,这样我们就得到了x跟y,然后通过机器学习回归进行训练与预测,因此他这里说的步阶为三,那其实就是用123天的数据去预测第四天,用234天的数据去预测第五天,像这种模型我们可以采用深度学习模型LSTM或者机器学习,例如说xgboost模型 |


问题三:
构建 AQI多步预测模型,使用均方根误差(RMSE) 对建模效果进行评估,并对测试集及其预测结果进行可视化。同时,用该模型预测附件 3 所给定时间的 AQI,并给出每天空气质量的预警等级,其结果请用表 3 和表 4格式在正文中具体给出。
| 第三问与第二问一直,没啥好说的 |
完整解题视频可看B站文章来源:https://www.toymoban.com/news/detail-622846.html
全保姆教程 2023华中杯数模竞赛C题解题+代码+数据_哔哩哔哩_bilibili文章来源地址https://www.toymoban.com/news/detail-622846.html
到了这里,关于2023华中杯C题全保姆教程及代码 空气质量预测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!