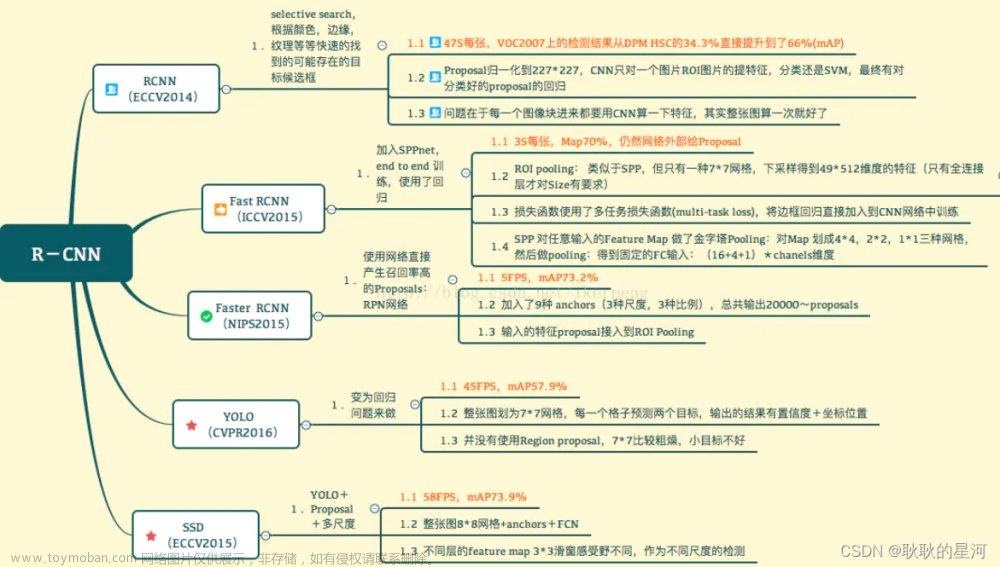
Mask R-CNN 是一种自顶向下(top-down)的姿态估计模型,它是在 Faster R-CNN [44] 这个目标检测框架的基础上扩展而来的。目标检测是指从图像中检测出不同类别的物体,并且输出它们的边界框(bounding box)。
Mask R-CNN 的结构包括一个标准的基础 CNN,通常是一个 ResNet [18] ,用于从图像中提取特征,然后将这些特征输入到一些专门针对不同任务训练的小型神经网络中,用于提出物体候选(RPN [44])
RPN 的输出是一个二元组 (rpn_class, rpn_bbox) ,其中:
- rpn_class 是一个二维数组,表示每个锚点(anchor)的类别概率。锚点是一种预定义的边界框,它们覆盖了图像中不同的位置、大小和形状。RPN 会对每个锚点进行二分类,判断它是否包含了物体(foreground)或者背景(background)。rpn_class 的形状是 (batch, anchors, 2) ,其中 batch 是批次大小,anchors 是锚点的总数,2 是类别数。rpn_class 中每个元素是一个长度为 2 的向量,表示该锚点属于 foreground 或者 background 的概率。
- rpn_bbox 是一个二维数组,表示每个锚点的边界框偏移量。边界框偏移量是指将锚点调整为更贴合物体的位置和大小所需要的平移和缩放的量。rpn_bbox 的形状是 (batch, anchors, 4) ,其中 batch 是批次大小,anchors 是锚点的总数,4 是偏移量的维度。rpn_bbox 中每个元素是一个长度为 4 的向量,表示该锚点在 x, y, w, h 四个方向上的偏移量,其中 x, y 是中心坐标,w, h 是宽度和高度。
region proposals+Feature Map 不同大小和形状,后续难以统一处理,所以需要RoIAlign 。
RoIAlign 的输出是一个固定大小的 feature map,比如 7 x 7 x C ,其中 C 是通道数。这个 feature map 是从输入的 feature map 中根据 RoI 的位置和大小进行裁剪和插值得到的。RoIAlign 使用了双线性插值(bilinear interpolation)来计算 feature map 中每个像素点的值,使得 feature map 更加平滑和精确。
为了从 RoIAlign 的输出得到 box 和 class,Mask R-CNN 使用了一个叫做 box head 的小型神经网络,它由两个全连接层(fully connected layer)组成。box head 的输入是 RoIAlign 的输出,也就是一个固定大小的 feature map。box head 的输出是一个长度为 K+4 的向量(vector),其中 K 是类别数。这个向量表示每个 RoI 的类别概率和边界框偏移量,也就是说,前 K 个元素是一个 one-hot 向量,表示该 RoI 属于哪个类别的概率,后 4 个元素是一个四维向量,表示该 RoI 在 x, y, w, h 四个方向上的偏移量,其中 x, y 是中心坐标,w, h 是宽度和高度。
通过 box head 的输出,我们可以得到每个 RoI 的类别和边界框,用于后续的 Mask R-CNN 的分割任务。文章来源:https://www.toymoban.com/news/detail-622958.html
为了从 RoIAlign 的输出得到 mask,Mask R-CNN 使用了一个叫做 mask head 的小型神经网络,它由两个卷积层(convolution layer)和一个反卷积层(deconvolution layer)组成。mask head 的输入是 RoIAlign 的输出,也就是一个固定大小的 feature map。mask head 的输出是一个 28 x 28 x K 的张量(tensor),其中 K 是类别数。这个张量表示每个类别对应的 mask 的概率分布,也就是说,每个类别有一个 28 x 28 的 mask,表示该类别物体在图像中的位置和形状。为了得到最终的 mask,我们需要根据分类结果选择对应的类别,并且将 mask 进行二值化(binarization),即将大于某个阈值(比如 0.5)的像素点设为 1 ,表示物体,将小于等于阈值的像素点设为 0 ,表示背景。文章来源地址https://www.toymoban.com/news/detail-622958.html
到了这里,关于【图解】Mask R-CNN 架构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!