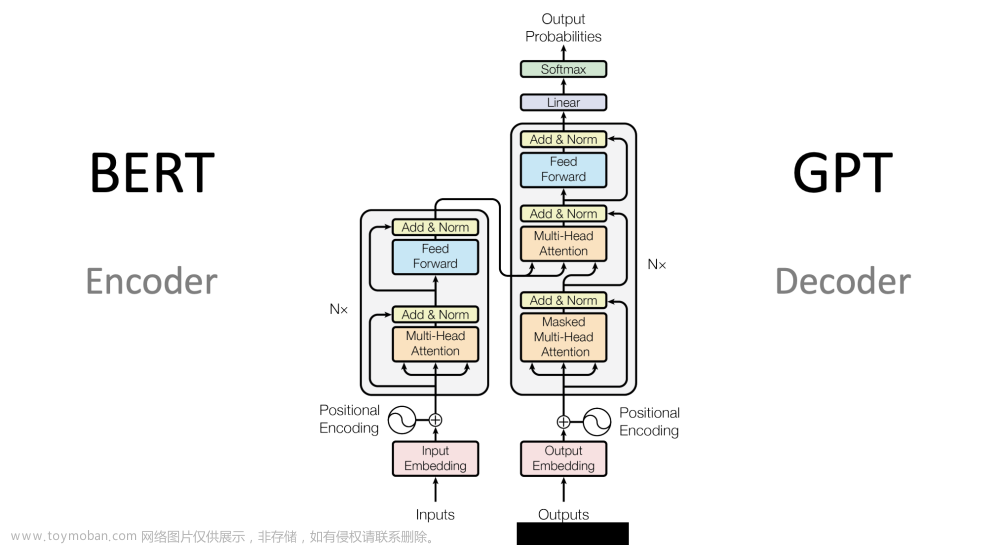
Transformer模型由多个编码器和解码器层组成,其中包含自注意力机制、线性层和层归一化等关键构造模块。虽然无法将整个模型完美地表示为单个数学公式,但我们可以提供一些重要构造模块的数学表示。以下是使用LaTeX格式渲染的部分Transformer关键组件的数学公式:文章来源:https://www.toymoban.com/news/detail-623183.html
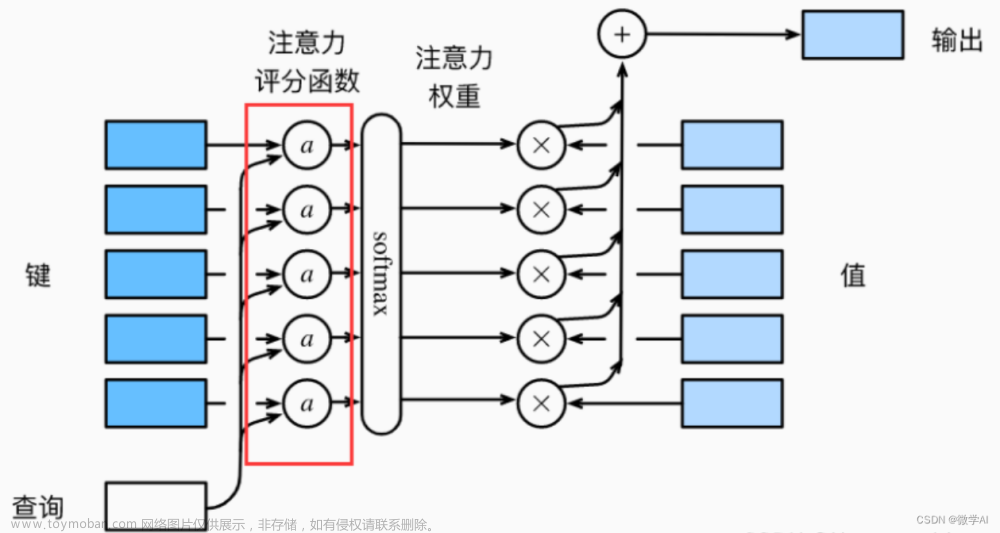
Scaled Dot-Product Attention
自注意力机制 (Scaled Dot-Product Attention) 是Transformer的核心组件。给定输入序列 Q Q Q, K K 文章来源地址https://www.toymoban.com/news/detail-623183.html
到了这里,关于【人工智能】Transformer 模型数学公式:自注意力机制、多头自注意力、QKV 矩阵计算实例、位置编码、编码器和解码器、常见的激活函数等的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!