一、简介
Redis是一个高性能的键值对数据库,支持常用的数据结构和分布式操作,被广泛应用于缓存、消息队列和排行榜等场景。除了基本的数据结构,Redis还支持图数据结构并提供了一些算法支持。
1 天梯图算法
天梯图算法是一种基于贪心的图搜索算法,在寻找最短路径问题中具有很高的效率。该算法通过对图中每个节点的估价函数(启发式函数)进行评估,并根据估价函数贪心地选择下一步的节点,直到找到目标节点或确定无解。天梯图算法被广泛应用于路径规划、游戏AI和网络优化等领域。
2 天梯图算法在Redis的应用
在Redis图数据库中,天梯图算法可以用在各种问题上,如查找两个节点之间的最短路径、查找节点的连通性等。通过Redis的多节点支持,我们可以利用其分布式计算的能力来加速天梯图算法的计算过程。
二、Redis分布式天梯图算法设计与优化
在Redis分布式系统中,我们的目标是减少算法计算时间并提高响应速度。以下是我们所采用的一些设计与优化措施。
1 基于天梯图的分布式算法设计
我们采用了一种基于分区的设计,把整个图划分为若干个子图,每个子图包含一个或多个节点。在分布式求解最短路径问题上,我们首先需要定位起始点所在的分区。然后在该分区的节点进行计算,同时利用Redis的消息队列特性,在不同节点间传递信息并协作完成任务。
2 多节点扩展与负载均衡优化
由于Redis支持多节点部署,我们可以通过增加节点的数量来提高算法的吞吐量。我们采用了一种动态调整节点数量的策略,能够有效地负载均衡和充分利用集群资源。
3 数据存储方案与压缩策略
对于大规模图数据集,存储与传输开销是非常重要的问题。我们采用了边存储和节点存储两种方式,并且对边存储采用了一种压缩策略,尽可能减少存储开销。
//以下是对节点数据进行压缩示例代码
public class Node {
private int id;
private int[] neighbors; //节点的邻居节点id数组
public Node(int id, int[] neighbors) {
this.id = id;
this.neighbors = neighbors;
}
public byte[] serialize() {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
try (DataOutputStream out = new DataOutputStream(bos)) {
out.writeInt(id);
out.writeByte(neighbors.length);
for (int neighbor : neighbors) {
out.writeInt(id - neighbor); //将节点id与邻居节点id差值序列化,通过涨幅来压缩存储空间
}
} catch (IOException e) {
e.printStackTrace();
}
return bos.toByteArray();
}
public static Node deserialize(byte[] data) {
ByteArrayInputStream bis = new ByteArrayInputStream(data);
try (DataInput in = new DataInputStream(bis)) {
int id = in.readInt();
int size = in.readByte();
int[] neighbors = new int[size];
for (int i = 0; i < size; i++) {
neighbors[i] = id - in.readInt(); //反序列化时,加上压缩的序列化涨幅
}
return new Node(id, neighbors);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
三、技术实现
3.1 系统架构设计
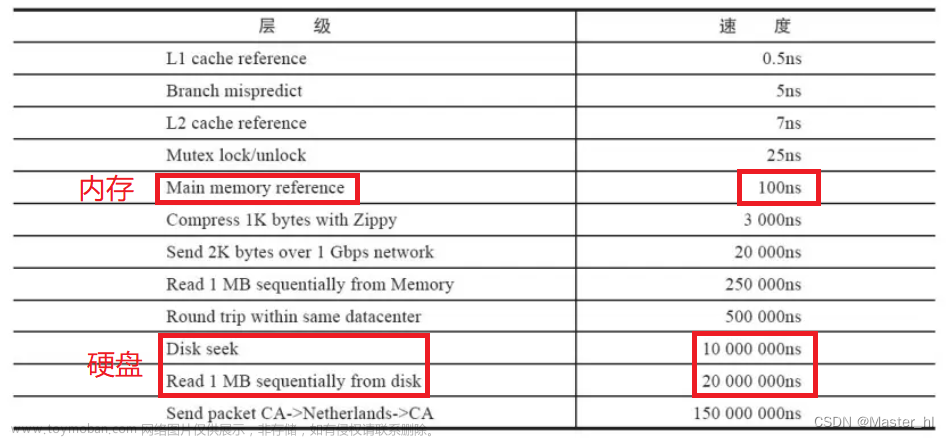
Redis采用单线程模型,即一个redis-server进程只会使用单个线程来处理客户端请求以及数据操作。这种设计选择是基于内存存储是速度最快的数据库存储方式,并且单线程可以最大化地避免多线程带来的CPU上下文切换和锁冲突问题。
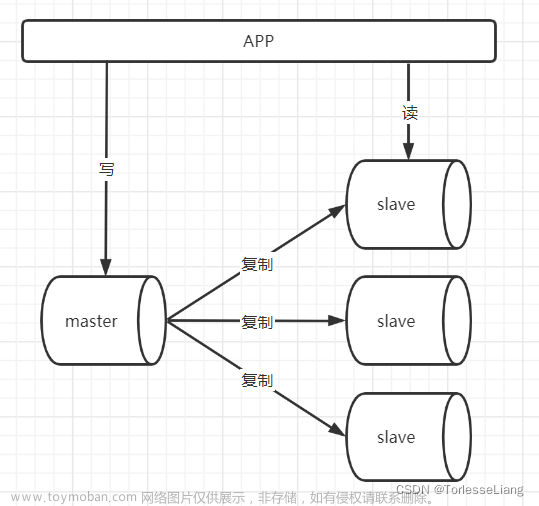
Redis支持主从复制模式,可以实现数据的高可用性和数据备份。Redis的主从复制是异步的,主节点收到写操作后先在自己本地处理,然后将数据同步给从节点。从节点收到同步请求后向主节点发送同步指令,并等待指令结果返回,然后再对本地数据进行修改操作。
3.2 技术选型
Redis采用C语言编写,为了提升性能采用了以下技术:
- 基于内存存储的单线程模型
- 高效的I/O多路复用机制
- 对象池技术,减少动态内存申请和回收开销
- 各种算法的优化,如哈希算法、跳跃表、压缩列表等
3.3 关键实现细节
Redis的关键实现细节如下:
- Redis的内存使用分配、回收和异步处理,采用非常高效的jemalloc内存库来管理。
- 对象池技术的具体实现是通过预先设置缓存对象池,避免频繁的malloc和free操作,提升了性能。
- Redis支持的数据类型有基本数据类型(如字符串、数字等)和高级数据类型(如哈希表、链表等),通过各种优化手段提高了内存利用率和访问速度。
- Redis的多路复用模型支持IO事件异步处理,避免出现I/O阻塞从而提高了运行效率。
四、评估与测试
4.1 性能指标选择
在对Redis进行性能评估和测试时,一般关注以下几个方面的指标:
- 吞吐量:Redis在单位时间内能够完成的请求次数,通常以QPS或TPS来衡量。
- 响应时间:Redis处理单次请求所需的时间,通常以平均响应时间、最大响应时间等指标来衡量。
- 并发数:并发连接数是同时连接到Redis服务的客户端数量。
4.2 测试数据集设计
在对Redis的性能进行评估和测试时,需要准备不同类型的测试数据集。根据具体情况,可以采用Benchmark工具、Redis自带的redis-benchmark命令或自行编写测试用例进行性能测试。文章来源:https://www.toymoban.com/news/detail-623489.html
4.3 测试结果评估与分析
测试结果包括吞吐量、响应时间等指标,需要进行综合分析和评估,找出Redis服务中的性能瓶颈,并针对性地进行优化和调整。在Redis服务达到高并发负载时,如何解决Redis单线程模型带来的瓶颈问题是一个重要的研究课题。文章来源地址https://www.toymoban.com/news/detail-623489.html
五、天梯图算法实际应用场景
5.1 地图服务
- 通过将地图中的交通网络(路网)转换为图(Graph)数据结构,应用天梯图算法,可以实现地图上最短路径和带约束条件的最短路径搜索功能。
- 在互联网地图服务中,如高德地图、百度地图等,都使用了Redis作为索引数据库,使用天梯图算法,快速高效地支持用户进行导航、规划出行路线等功能。
5.2 路径规划
- 天梯图算法可以在道路网格状不规则的城市中精确地寻找最短路径,支持“公交站与地铁站之间的步行时间”、“乘车时间”、“换乘次数”、“购票站点”等约束条件的路径规划。
- 在出租车调度、物流配送、共享单车调度等领域,根据不同的业务需求,利用Redis+天梯图算法可以灵活地进行路径规划。
5.3 社交网络关系分析
- 在社交网络上,人与人之间的关系可以抽象成一张图。用户可以根据自己的兴趣爱好和互动频次等因素,建立与其他人的联系。
- 利用Redis天梯图算法,可以从社交网络的关系图中,快速计算某个用户与其他用户之间的“最短距离”、“关系强度”等指标,支持推荐系统、用户画像等应用。
六、安全与容错机制设计
6.1 安全设计方案
- Redis提供了密码认证机制,可以为Redis实例设置密码或使用密钥进行认证,以保障数据安全。
- Redis还支持SSL/TLS协议,通过对数据进行加密传输,防止数据在传输过程中被窥探或篡改。
6.2 容错机制设计方案
- Redis支持数据备份机制,可以将数据刷到磁盘上,以保障数据不会因为内存失效而丢失。
- Redis还支持主从复制和哨兵机制,保证Redis系统具有高可用性,并支持自动故障恢复和负载均衡。
到了这里,关于分布式天梯图算法在 Redis 图数据库中的应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!