- 一、爬取目标
- 二、展示爬取结果
-
三、讲解代码
- 3.1 分析页面
- 3.2 开发爬虫
- 四、同步视频
- 五、获取完整源码
您好,我是@马哥python说,一枚10年程序猿。
一、爬取目标
之前我分享过一篇知乎评论的爬虫教程,但是学习群中的小伙伴强烈要求爬取知乎回答,所以本次分享知乎回答的爬虫。
二、展示爬取结果
老规矩,先展示结果。
最近《罗刹海市》这首歌比较火,就爬这个问题下的回答吧:如何评价刀郎的新歌《罗刹海市》?
爬取了前200多页,每页5条数据,共1000多条回答。(程序设置的自动判断结束页,我是手动break的)
共爬到13个字段,包含:
问题id,页码,答主昵称,答主性别,答主粉丝数,答主主页,答主签名,回答id,回答时间,评论数,点赞数,喜欢数,回答内容
三、讲解代码
3.1 分析页面
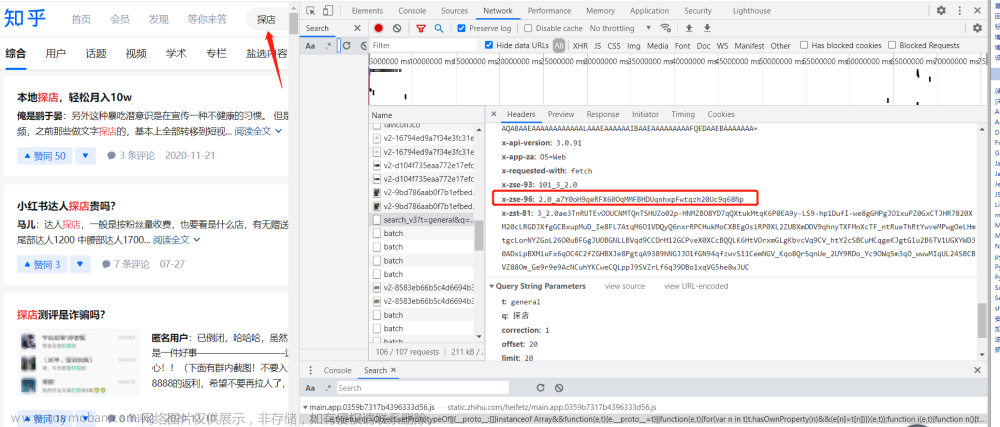
我是通过知乎的ajax接口爬的。打开一个知乎问题,Chrome浏览器按F12进入开发者模式之后,多往下翻几页回答,就会找到目标请求地址,如下:
每翻一次页,就会出现一个请求,请求中含5条回答数据。
3.2 开发爬虫
首先,导入需要用到的库:
import requests
import time
import pandas as pd
import os
import re
import random
定义一个请求头:
# 请求头
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
这里,我仅设置了user-agent足矣。(如果数据量仍未满足且遇到反爬,请尝试增加cookie等其他请求头解决)
定义请求地址(含指定问题id):
# 请求地址
url = 'https://www.zhihu.com/api/v4/questions/{}/feeds?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Creaction_instruction%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=0&order=default&platform=desktop'.format(
v_question_id)
发送请求,并接收数据:
# 发送请求
r = requests.get(url, headers=headers)
# 接收返回数据
j_data = r.json()
定义一些空列表用于存放解析后数据:
author_name_list = [] # 答主昵称
author_gender_list = [] # 答主性别
follower_count_list = [] # 答主粉丝数
author_url_list = [] # 答主主页
headline_list = [] # 答主签名
answer_id_list = [] # 回答id
answer_time_list = [] # 回答时间
answer_content_list = [] # 回答内容
comment_count_list = [] # 评论数
voteup_count_list = [] # 点赞数
thanks_count_list = [] # 喜欢数
以"回答内容"字段为例:
for answer in answer_list:
# 回答内容
try:
answer_content = answer['target']['content']
answer_content = clean_content(answer_content)
except:
answer_content = ''
answer_content_list.append(answer_content)
其他字段同理,不再赘述。
把数据保存为Dataframe并进一步保存到csv文件:
# 数据保存为Dataframe格式
df = pd.DataFrame(
{
'问题id': v_question_id,
'页码': page,
'答主昵称': author_name_list,
'答主性别': author_gender_list,
'答主粉丝数': follower_count_list,
'答主主页': author_url_list,
'答主签名': headline_list,
'回答id': answer_id_list,
'回答时间': answer_time_list,
'评论数': comment_count_list,
'点赞数': voteup_count_list,
'喜欢数': thanks_count_list,
'回答内容': answer_content_list,
}
)
# 保存到csv文件
df.to_csv(v_result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
保存到csv时加上encoding='utf_8_sig'参数,防止产生乱码问题。
至此,核心代码逻辑讲解完毕。完整代码还包括:转换时间格式、转换性别、正则表达式清洗回答内容、循环内判断结束页等功能,详见文末获取。
代码中,question_id换成任意知乎问题id,即可爬取该问题的对应回答。
四、同步视频
代码演示视频:https://www.bilibili.com/video/BV1BX4y1772v
五、获取完整源码
附完整python源码:【2023知乎爬虫】知友怎么看待《罗刹海市》?爬了上千条知乎回答!文章来源:https://www.toymoban.com/news/detail-623621.html
我是@马哥python说 ,一名10年程序猿,持续分享python干货中!文章来源地址https://www.toymoban.com/news/detail-623621.html
到了这里,关于【2023知乎爬虫】知友怎么看待《罗刹海市》?爬了上千条知乎回答!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!