这篇文章主要是整理了一些作者在各种建模比赛中遇到的数据预处理问题以及方法,主要针对excel或csv格式的数据,为后续进行机器学习或深度学习做前期准备
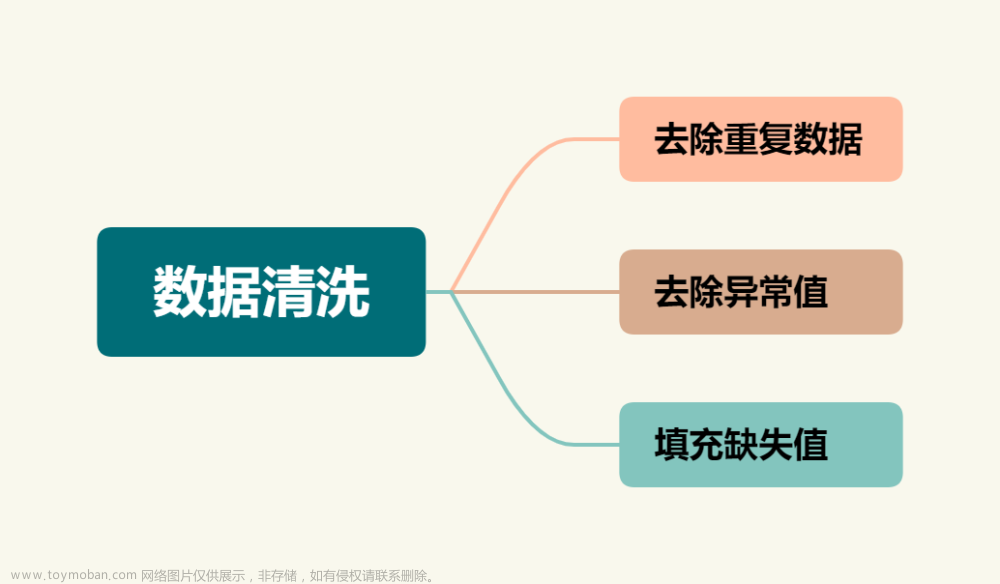
数据清洗
导入库和文件,这里使用的是绝对路径,可改为相对路径
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取xls数据文件
data = pd.read_csv(r'D:\1112222.csv',encoding='gbk')传入的为csv格式的文件,如果是xlsx格式的文件,建议先使用excel另存为csv结尾格式的文件再进行操作,选择下图所示选项:

合并多个文件数据
可能同时存在多个csv文件,需要进行合并
import glob,os
filenames_in = r'D:\in' # 输入文件的文件地址
filenames_out = r'D:\inner' # 新文件的地址
path_in = r'D:\in'
file_names = os.listdir(path_in)
file_paths = glob.glob(os.path.join(path_in,'*.csv'))
print(file_paths)
df1 = pd.DataFrame()
for file in file_paths:
df2 = pd.read_csv(file,sep=',',header=None)
#df2=df2.iloc[:,2] #只取第三列
df1 = pd.concat([df1, df2], axis=0) #axis=0意思是纵向拼接,=1的时候是横向拼接
print('dataframe的维度是:', df1.shape)
#print(df1)
# 输出数据到本地
df1.to_csv(r'D:\inner\result.csv', index=False, sep=',')填补缺失值
对于数字类型的数据,用均值填补空值;对于字符类型的数据,用众数填补空值
def fill_missing_values(df):
"""用DataFrame中各列的均值或众数来填补空值"""
for column in df:
if df[column].dtype == np.number: # 如果数据是数字类型
mean = df[column].mean()
df[column].fillna(mean, inplace=True) # 用均值填补空值
else: # 如果数据不是数字类型
mode = df[column].mode().iloc[0] # 找到最频繁出现的项
df[column].fillna(mode, inplace=True) # 用众数填补空值
return df
data=fill_missing_values(data)去除数据中的符号
对于有些数据,可能含有空格、中英文标点,需要进行去除
import string
from zhon.hanzi import punctuation
punctuation_string = string.punctuation
for i in punctuation_string:
data= data.replace(i, '')
punctuation_str = punctuation
for i in punctuation_str:
data = data.replace(i, '')
当然,如果遇到这种数据,我会更建议使用excel自带的功能进行手动去除,比调代码更快(毕竟有时候可能调代码半天手动早就做好了)
如图,c列是一列数据前面有空格的数据,这时我们只需要在c列后插入新的一列,并在第一行中输入c列无空格的数据

输入好后,直接快捷键CTRL+E,即可自动将D列填充为去除空格后的数据(注意要确保此时其他数据没有别的空缺,否则会把别的空缺也自动填充上)

四万个数据不到一秒就全部填充好了,速度还是比较快的。然后直接把c列删除即可。
如果是数据中包含特殊字符,想去除也可以用这个方法,只是对某几列做操作时,比调代码快。
去除冗余数据
有些数据,可能一整列都是同一个数据,没有变化,这些变量对机器学习没有帮助,但因为数据太多,不可能人工判断每列数据情况,需要代码调试进行去除
for col in data.columns:
# 如果这一列所有的值都相等
if data[col].nunique() == 1:
# 则删除这一列
data = data.drop(col, axis=1)格式转换
将true和false类型数据转换为int型
data['11'] = data['11'].astype(int)其他类型同理,将“int”改为想转换的类型即可
字母或字符串转换为对应数字
如果想将字母或字符串转换为数字在后续作为变量进行处理,建议直接在excel中快捷键CTRL+h进行转换,代码总是会出现各种错误。
合并某几列数据
如果给出的数据有年、月、日,需要将其合并成一列
data['timestamp'] = data['月'].astype(str) + '-' + data['日'].astype(str) + '-' + data['具体时间']
data = data.drop(['月', '日', '具体时间'], axis=1)
# 将时间戳列设置为索引
#data.set_index('timestamp', inplace=True)
data['time'] = pd.to_datetime('2023-' + data['timestamp'], format='%Y-%m-%d-%H:%M:%S')对多列数据求平均值并合并为一列:
class_df = (data['ROLL_ATT1']+data['ROLL_ATT2'])/2
data['ROLL_ATT1']=class_df
data = data.drop(['ROLL_ATT2','MAGNETIC_HEADING'], axis=1)数据可视化
可以将已处理好的数据进行可视化
以某个自变量为横坐标(如时间),其余为纵坐标画出折线图,画出所有变量随时间变化的折线图:
import matplotlib.pyplot as plt
#画出所有变量随时间变化图像
feature = data.columns[1:]
for feas in feature:
plt.plot(data['time'], data[feas])
plt.xlabel('Time')
plt.ylabel(feas)
plt.show()判断某个变量的分布情况可以绘制分布图
# 绘制分布图
plt.hist(df2['train1'], bins=20)
plt.xlabel('train1')
plt.ylabel('Frequency')
plt.title('Takeoff Weight Distribution')
plt.show()散点图绘制
import seaborn as sns
sns.pairplot(data , hue ='label')
plt.savefig(r"D:\pairplot001.png")效果如下:

也可以画出相关性系数热力图
import seaborn as sns
sns.set(style="ticks")
sns.heatmap(data.corr(), annot=True, cmap="YlGnBu");
plt.savefig(r"D:\heatmap.png")效果如下:

针对机器学习及深度学习数据预处理
导入库(keras库的内容是深度学习才需要用到的,仅进行机器学习可以不导入)
import numpy as np
import pandas as pd
import keras
from keras.models import Sequential
from keras.wrappers.scikit_learn import KerasClassifier
from keras.utils import np_utils, plot_model
import matplotlib.pyplot as pl
from sklearn import metrics
from sklearn.model_selection import cross_val_score, train_test_split, KFold
from sklearn.preprocessing import LabelEncoder
from keras.layers import Dense, Dropout, Flatten, Conv1D, MaxPooling1D
from keras.models import model_from_json
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import seaborn as sns
import os
from sklearn.preprocessing import StandardScaler
import itertools首先是对数据集进行划分
data2=data.drop(['label'],axis=1)
X = np.expand_dims(data2.astype(float), axis=2)
Y = data['label']
print(X.shape)
print(Y.shape)
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.7, random_state=20)
x_valid, x_test, y_test, y_valid=train_test_split(X, Y, test_size=0.5, random_state=20)数据标准化
standard = StandardScaler()
# 对训练集进行标准化,它会计算训练集的均值和标准差保存起来
x_train = standard.fit_transform(x_train)
# 使用标准化器在训练集上的均值和标准差,对测试集进行归一化
x_test = standard.transform(x_test)接下来都是深度学习需要进行的预处理操作,机器学习不用
深度学习需要对label进行onehot编码
from keras.utils import to_categorical
y_test = to_categorical(y_test)
y_train = to_categorical(y_train)
from keras import backend as K
K.set_image_dim_ordering("tf")
#one_hot编码转换
def one_hot(Train_Y, Test_Y):
Train_Y = np.array(Train_Y).reshape([-1, 1])
Test_Y = np.array(Test_Y).reshape([-1, 1])
Encoder = preprocessing.OneHotEncoder()
Encoder.fit(Train_Y)
Train_Y = Encoder.transform(Train_Y).toarray()
Test_Y = Encoder.transform(Test_Y).toarray()
Train_Y = np.asarray(Train_Y, dtype=np.int32)
Test_Y = np.asarray(Test_Y, dtype=np.int32)
return Train_Y, Test_Y
y_train, y_test = one_hot(y_train, y_test)接下来需要根据训练参数进行调整,假设训练参数设置如下
# 训练参数
batch_size = 128
epochs = 40 #训练轮数
num_classes = 6 #总共的训练类数
length = 2048
BatchNorm = False # 是否批量归一化
number = 1000 # 每类样本的数量
normal = False # 是否标准化重塑训练参数,否则传入模型时会出错
x_train=x_train.reshape((x_train.shape[0],x_train.shape[1],1))
x_test = x_test.reshape((x_test.shape[0], x_test.shape[1],1))需要根据betch_size的大小改变选择的训练数据数目,否则传入模型训练会出错文章来源:https://www.toymoban.com/news/detail-624193.html
# # 改变dataset的大小,变成batch_size的倍数
def change_dataset_size(x, y, batch_size):
length = len(x)
if (length % batch_size != 0):
remainder = length % batch_size
x = x[:(length - remainder)]
y = y[:(length - remainder)]
return x, y
x_train,y_train=change_dataset_size(x_train,y_train,batch_size)
x_valid, y_valid=change_dataset_size(x_valid, y_valid,batch_size)这一步之后基本就可以直接传入模型进行训练了 文章来源地址https://www.toymoban.com/news/detail-624193.html
到了这里,关于数据预处理方法整理(数学建模)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!