动动发财的小手,点个赞吧!
在本文[1]中,我们将首先了解数据并行(DP)和分布式数据并行(DDP)算法之间的差异,然后我们将解释什么是梯度累积(GA),最后展示 DDP 和 GA 在 PyTorch 中的实现方式以及它们如何导致相同的结果。
简介
训练深度神经网络 (DNN) 时,一个重要的超参数是批量大小。通常,batch size 不宜太大,因为网络容易过拟合,但也不宜太小,因为这会导致收敛速度慢。
当处理高分辨率图像或占用大量内存的其他类型的数据时,假设目前大多数大型 DNN 模型的训练都是在 GPU 上完成的,根据可用 GPU 的内存,拟合小批量大小可能会出现问题。正如我们所说,因为小批量会导致收敛速度慢,所以我们可以使用三种主要方法来增加有效批量大小:
-
使用多个小型 GPU 在小批量上并行运行模型 — DP 或 DDP 算法 -
使用更大的 GPU(昂贵) -
通过多个步骤累积梯度
现在让我们更详细地了解 1. 和 3. — 如果您幸运地拥有一个大型 GPU,可以在其上容纳所需的所有数据,您可以阅读 DDP 部分,并在完整代码部分中查看它是如何在 PyTorch 中实现的,从而跳过其余部分。
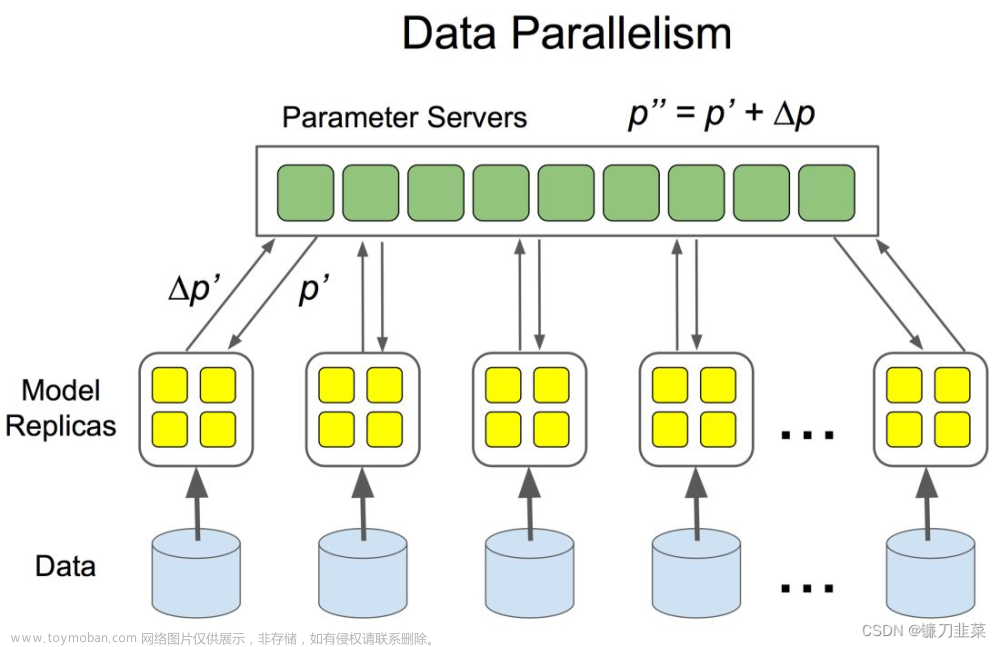
假设我们希望有效批量大小为 30,但每个 GPU 上只能容纳 10 个数据点(小批量大小)。我们有两种选择:数据并行或分布式数据并行:
数据并行性 (DP)
首先,我们定义主 GPU。然后,我们执行以下步骤:
-
将 10 个数据点(小批量)和模型的副本从主 GPU 移动到其他 2 个 GPU -
在每个 GPU 上进行前向传递并将输出传递给主 GPU -
在主 GPU 上计算总损失,然后将损失发送回每个 GPU 以计算参数的梯度 -
将梯度发送回Master GPU(这些是所有训练示例的梯度平均值),将它们相加得到整批30个的平均梯度 -
更新主 GPU 上的参数并将这些更新发送到其他 2 个 GPU 以进行下一次迭代
这个过程存在一些问题和低效率:
-
数据-从主 GPU 传递,然后在其他 GPU 之间分配。此外,主 GPU 的利用率高于其他 GPU,因为总损失的计算和参数更新发生在主 GPU 上 -
我们需要在每次迭代时同步其他 GPU 上的模型,这会减慢训练速度
分布式数据并行 (DDP)
引入分布式数据并行是为了改善数据并行算法的低效率。我们仍然采用与之前相同的设置 — 每批 30 个数据点,使用 3 个 GPU。差异如下:
-
它没有主 GPU -
因为我们不再拥有主 GPU,所以我们直接从磁盘/RAM 以非重叠方式并行加载每个 GPU 上的数据 — DistributedSampler 为我们完成这项工作。在底层,它使用本地等级 (GPU id) 在 GPU 之间分配数据 - 给定 30 个数据点,第一个 GPU 将使用点 [0, 3, 6, ... , 27],第二个 GPU [1, 4, 7, .., 28] 和第三个 GPU [2, 5, 8, .. , 29]
n_gpu = 3
for i in range(n_gpu):
print(np.arange(30)[i:30:n_gpu])
-
前向传递、损失计算和后向传递在每个 GPU 上独立执行,异步减少梯度计算平均值,然后在所有 GPU 上进行更新
由于DDP相对于DP的优点,目前优先使用DDP,因此我们只展示DDP的实现。
梯度累积
如果我们只有一个 GPU 但仍想使用更大的批量大小,另一种选择是累积一定数量的步骤的梯度,有效地累积一定数量的小批量的梯度,从而增加有效的批量大小。从上面的例子中,我们可以通过 3 次迭代累积 10 个数据点的梯度,以达到与我们在有效批量大小为 30 的 DDP 训练中描述的结果相同的结果。
DDP流程代码
下面我将仅介绍与 1 GPU 代码相比实现 DDP 时的差异。完整的代码可以在下面的一些部分找到。首先我们初始化进程组,允许不同进程之间进行通信。使用 int(os.environ[“LOCAL_RANK”]) 我们检索给定进程中使用的 GPU。
init_process_group(backend="nccl")
device = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(device)
然后,我们需要将模型包装在 DistributedDataParallel 中,以支持多 GPU 训练。
model = NeuralNetwork(args.data_size)
model = model.to(device)
if args.distributed:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[device])
最后一部分是定义我在 DDP 部分中提到的 DistributedSampler。
sampler = torch.utils.data.DistributedSampler(dataset)
培训的其余部分保持不变 - 我将在本文末尾包含完整的代码。
梯度累积代码
当反向传播发生时,在我们调用 loss.backward() 后,梯度将存储在各自的张量中。实际的更新发生在调用 optimizationr.step() 时,然后使用 optimizationr.zero_grad() 将张量中存储的梯度设置为零,以运行反向传播和参数更新的下一次迭代。
因此,为了累积梯度,我们调用 loss.backward() 来获取我们需要的梯度累积数量,而不将梯度设置为零,以便它们在多次迭代中累积,然后我们对它们进行平均以获得累积梯度迭代中的平均梯度(loss = loss/ACC_STEPS)。之后我们调用optimizer.step()并将梯度归零以开始下一次梯度累积。在代码中:
ACC_STEPS = dist.get_world_size() # == number of GPUs
# iterate through the data
for i, (idxs, row) in enumerate(loader):
loss = model(row)
# scale loss according to accumulation steps
loss = loss/ACC_STEPS
loss.backward()
# keep accumualting gradients for ACC_STEPS
if ((i + 1) % ACC_STEPS == 0):
optimizer.step()
optimizer.zero_grad()
代码
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
print(os.environ["CUDA_VISIBLE_DEVICES"])
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset, Sampler
import argparse
import torch.optim as optim
import numpy as np
import random
import torch.backends.cudnn as cudnn
import torch.nn.functional as F
from torch.distributed import init_process_group
import torch.distributed as dist
class data_set(Dataset):
def __init__(self, df):
self.df = df
def __len__(self):
return len(self.df)
def __getitem__(self, index):
sample = self.df[index]
return index, sample
class NeuralNetwork(nn.Module):
def __init__(self, dsize):
super().__init__()
self.linear = nn.Linear(dsize, 1, bias=False)
self.linear.weight.data[:] = 1.
def forward(self, x):
x = self.linear(x)
loss = x.sum()
return loss
class DummySampler(Sampler):
def __init__(self, data, batch_size, n_gpus=2):
self.num_samples = len(data)
self.b_size = batch_size
self.n_gpus = n_gpus
def __iter__(self):
ids = []
for i in range(0, self.num_samples, self.b_size * self.n_gpus):
ids.append(np.arange(self.num_samples)[i: i + self.b_size*self.n_gpus :self.n_gpus])
ids.append(np.arange(self.num_samples)[i+1: (i+1) + self.b_size*self.n_gpus :self.n_gpus])
return iter(np.concatenate(ids))
def __len__(self):
# print ('\tcalling Sampler:__len__')
return self.num_samples
def main(args=None):
d_size = args.data_size
if args.distributed:
init_process_group(backend="nccl")
device = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(device)
else:
device = "cuda:0"
# fix the seed for reproducibility
seed = args.seed
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
cudnn.benchmark = True
# generate data
data = torch.rand(d_size, d_size)
model = NeuralNetwork(args.data_size)
model = model.to(device)
if args.distributed:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[device])
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
dataset = data_set(data)
if args.distributed:
sampler = torch.utils.data.DistributedSampler(dataset, shuffle=False)
else:
# we define `DummySampler` for exact reproducibility with `DistributedSampler`
# which splits the data as described in the article.
sampler = DummySampler(dataset, args.batch_size)
loader = DataLoader(
dataset,
batch_size=args.batch_size,
num_workers=0,
pin_memory=True,
sampler=sampler,
shuffle=False,
collate_fn=None,
)
if not args.distributed:
grads = []
# ACC_STEPS same as GPU as we need to divide the loss by this number
# to obtain the same gradient as from multiple GPUs that are
# averaged together
ACC_STEPS = args.acc_steps
optimizer.zero_grad()
for epoch in range(args.epochs):
if args.distributed:
loader.sampler.set_epoch(epoch)
for i, (idxs, row) in enumerate(loader):
if args.distributed:
optimizer.zero_grad()
row = row.to(device, non_blocking=True)
if args.distributed:
rank = dist.get_rank() == 0
else:
rank = True
loss = model(row)
if args.distributed:
# does average gradients automatically thanks to model wrapper into
# `DistributedDataParallel`
loss.backward()
else:
# scale loss according to accumulation steps
loss = loss/ACC_STEPS
loss.backward()
if i == 0 and rank:
print(f"Epoch {epoch} {100 * '='}")
if not args.distributed:
if (i + 1) % ACC_STEPS == 0: # only step when we have done ACC_STEPS
# acumulate grads for entire epoch
optimizer.step()
optimizer.zero_grad()
else:
optimizer.step()
if not args.distributed and args.verbose:
print(100 * "=")
print("Model weights : ", model.linear.weight)
print(100 * "=")
elif args.distributed and args.verbose and rank:
print(100 * "=")
print("Model weights : ", model.module.linear.weight)
print(100 * "=")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--distributed', action='store_true',)
parser.add_argument('--seed', default=0, type=int)
parser.add_argument('--epochs', default=2, type=int)
parser.add_argument('--batch_size', default=4, type=int)
parser.add_argument('--data_size', default=16, type=int)
parser.add_argument('--acc_steps', default=3, type=int)
parser.add_argument('--verbose', action='store_true',)
args = parser.parse_args()
print(args)
main(args)
总结
在本文中,我们简要介绍并直观地介绍了 DP、DDP 算法和梯度累积,并展示了如何在没有多个 GPU 的情况下增加有效批量大小。需要注意的一件重要事情是,即使我们获得相同的最终结果,使用多个 GPU 进行训练也比使用梯度累积要快得多,因此如果训练速度很重要,那么使用多个 GPU 是加速训练的唯一方法。
Reference
Source: https://towardsdatascience.com/multiple-gpu-training-in-pytorch-and-gradient-accumulation-as-an-alternative-to-it-e578b3fc5b91文章来源:https://www.toymoban.com/news/detail-624249.html
本文由 mdnice 多平台发布文章来源地址https://www.toymoban.com/news/detail-624249.html
到了这里,关于PyTorch 中的多 GPU 训练和梯度累积作为替代方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!