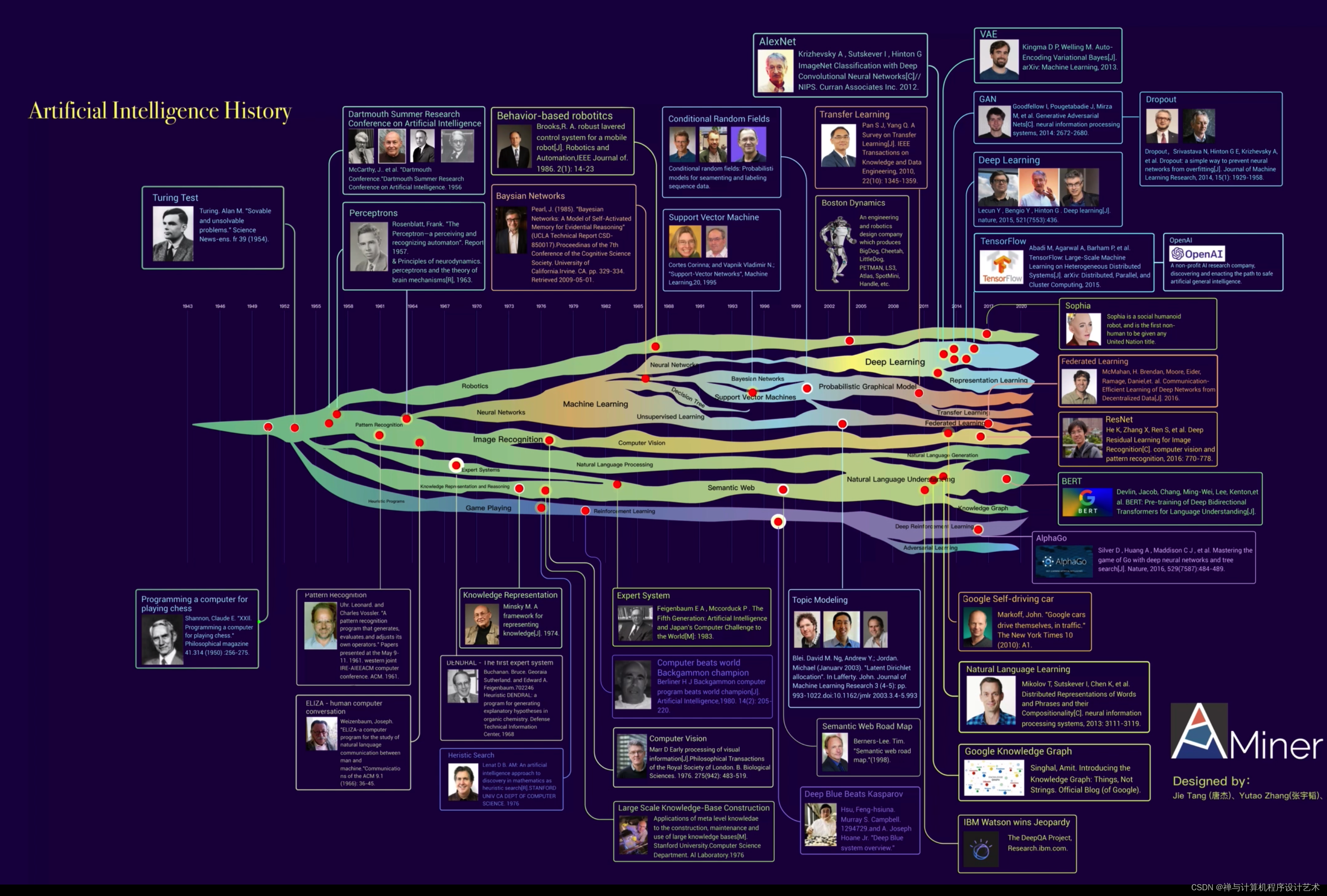
关于RKNN
RKNN 是Rockchip npu 平台使用的模型类型,以.rknn后缀结尾的模型文件。Rockchip 提供了完整了模型转换 Python 工具,方便用户将自主研发的算法模型转换成 RKNN 模型,同时 Rockchip 也提供了C/C++和Python API 接口。
使用RKNN
RKNN-Toolkit2 是为用户提供在 PC 平台上进行模型转换、推理和性能评估的开发套件,用户
通过该工具提供的 Python 接口可以便捷地完成以下功能:
- 模型转换:支持 Caffe、TensorFlow、TensorFlow Lite、ONNX、DarkNet、PyTorch 等模型
转为 RKNN 模型,并支持 RKNN 模型导入导出,RKNN 模型能够在 Rockchip NPU 平台
上加载使用。 - 量 化 功 能 : 支 持 将 浮 点 模 型 量 化 为 定 点 模 型 , 目 前 支 持 的 量 化 方 法 为 非 对 称 量 化
(asymmetric_quantized-8),并支持混合量化功能。 - 模型推理:能够在 PC 上模拟 NPU 运行 RKNN 模型并获取推理结果;或将 RKNN 模型分
发到指定的 NPU 设备上进行推理并获取推理结果。 - 性能和内存评估:将 RKNN 模型分发到指定 NPU 设备上运行,以评估模型在实际设备上
运行时的性能和内存占用情况。 - 量化精度分析:该功能将给出模型量化前后每一层推理结果与浮点模型推理结果的余弦距
离,以便于分析量化误差是如何出现的,为提高量化模型的精度提供思路。 - 模型加密功能:使用指定的加密等级将 RKNN 模型整体加密。因为 RKNN 模型的加密是
在 NPU 驱动中完成的,使用加密模型时,与普通 RKNN 模型一样加载即可,NPU 驱动会
自动对其进行解密。
rknpu2
RKNN SDK 为带有RKNPU的芯片平台提供编程接口,能够帮助用户部署使用RKNN-Toolkit2导出的RKNN模型,加速AI应用的落地。
环境安装
系统:Ubuntu20.04 LTS x64
内存:16GB
Python:3.8.10
目标平台:RK356X/RK3568
RKNN-Toolkit2: 参考文档安装 Rockchip_Quick_Start_RKNN_Toolkit2_CN-1.4.0
从Github克隆代码后开始安装。
PS:注意网络问题,有条件的话使用科学上网,可以减少安装问题和加快安装速度
#已安装的工具包请忽略
#1.安装 Python3.6 和 pip3
sudo apt-get install python3 python3-dev python3-pip
#2.安装相关依赖
sudo apt-get install libxslt1-dev zlib1g zlib1g-dev libglib2.0-0 libsm6 \
libgl1-mesa-glx libprotobuf-dev gcc
#3.获取 RKNN-Toolkit2 安装包,然后执行以下步骤:
##a)安装 Python 依赖:
## 也可根据前面的版本安装doc/requirements_cp38-1.4.0.txt
pip3 install -r doc/requirements*.txt
##b)进入 package 目录:
cd packages/
##c)安装 RKNN-Toolkit2
## 同样可选择根据版本安装:packages/rknn_toolkit2-1.4.0_22dcfef4-cp38-cp38-linux_x86_64.whl
sudo pip3 install rknn_toolkit2*.whl
##d)检查 RKNN-Toolkit2 是否安装成功
rk@rk:~/rknn-toolkit2/packages$ python3
>>> from rknn.api import RKNN
>>>
如果导入 RKNN 模块没有失败,说明安装成功。
可以在安装一个工具Netron方便查看模型的信息
sudo snap install netron
Netron是一个基于Electron平台开发的神经网络模型可视化工具,支持许多主流AI框架模型的可视化,支持多种平台(Mac、Windows、Linux等)。 Netron 支持MindSpore Lite模型,可以方便地查看模型信息。网页版也可以netron
比如直接打开查看:rknn-toolkit2/examples/onnx/yolov5/yolov5s.onnx
模型转换
导出ONNX模型
README_rkopt_manual.md
yolo
YOLO - demo
基于 https://github.com/Megvii-BaseDetection/YOLOX 代码修改,设配 rknpu 设备的部署优化
切换分支 git checkout {分支名}
目前支持分支:
v0.3.0.rkopt
maxpool/ focus 优化,输出改为个branch分支的输出。以上优化代码使用插入宏实现,不影响原来的训练逻辑,这个优化兼容修改前的权重,故支持官方给的预训练权重。
训练的相关内容请参考 README.md 说明
导出模型时 python export.py --rknpu {rk_platform} 即可导出优化模型
(rk_platform支持 rk1808, rv1109, rv1126, rk3399pro, rk3566, rk3568, rk3588, rv1103, rv1106)
导出RKNN模型(convert.py 代码摘自rknn_toolkit2, 抽取简化)
调用: python3 convert.py file.onnx rk3568 True dataset.txt
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknn.api import RKNN
ONNX_MODEL = 'yolov5s.onnx'
RKNN_MODEL = 'yolov5s.rknn'
DATASET = './dataset.txt'
QUANTIZE_ON = False
PLATFORM = 'rk3568'
if __name__ == '__main__':
print("CONVERT: argc", len(sys.argv))
argc = len(sys.argv)
if argc < 2:
print("CONVERT need more arguments")
print("python3 convert.py file.onnx platform QTANTIZE dataset.txt")
print("python3 convert.py argv[1] argv[2] argv[3] argv[4]")
print(" platform{rk3566 rk3568 rk3588}")
print(" QTANTIZE{True False}")
exit()
else:
ONNX_MODEL = sys.argv[1]
RKNN_MODEL = sys.argv[1].replace(".onnx", "_")
if argc > 2:
PLATFORM = sys.argv[2]
if argc > 3:
QUANTIZE_ON = "True" == sys.argv[3]
if argc > 4:
DATASET = sys.argv[4]
RKNN_MODEL = RKNN_MODEL + PLATFORM + "_"
if QUANTIZE_ON :
RKNN_MODEL = RKNN_MODEL + "QUANT-ON"
else :
RKNN_MODEL = RKNN_MODEL + "QUANT-OFF"
RKNN_MODEL = RKNN_MODEL + ".rknn"
print("--> START CONVERT")
print(" MODEL=", ONNX_MODEL)
print(" PLATFORM=", PLATFORM)
print(" DATASET=", DATASET)
print(" QUANTIZE_ON=", QUANTIZE_ON)
print(" RKNN_MODEL=", RKNN_MODEL)
# Create RKNN object
rknn = RKNN(verbose=True)
# pre-process config
print('--> Config model')
std = 255
mean = 0
rknn.config(
mean_values=[[0, 0, 0]],
std_values=[[255, 255, 255]],
target_platform=PLATFORM)
print('done')
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export RKNN model
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
print("OUTPUT->> ", RKNN_MODEL)
rknn.release()
do_quantization=QUANTIZE_ON
是否对模型进行量化,值为 True 或 False, “fp16 模型”的结果正确是保证后续“量化模型”精度正确的前提,
用户只需要在使用 RKNN的 build 接口时,将 do_quantization 参数设置为 False,即可以将原始模型转换为“fp16 模型”。
这个变量会影响模型的IO:
-----------------------------------------左边-非量化(False) ::::::::::::::::::::::::::::::::::::::::::右边-量化(True)
在后续的代码中,会提及到对C++的影响
target_platform=‘rk3568’ 设置目标平台, rk3566 的RKNN 不能放到 rk3568上运行。
rknn.config(target_platform='rk3568', mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]])
执行模型
关于test.py:RK提供的参考demo, 主要完成了两个功能:
- ONNX -> RKNN 的模型转换
- 运行测试模型推理并输出结果.
代码中使用rknn-toolkit2/examples/onnx/yolov5/models/yolov5s.onnx一个目标检测识别的模型做测试。
rknn-toolkit2/examples/onnx/yolov5/test.py
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknn.api import RKNN
#模型的路径
ONNX_MODEL = 'yolov5s.onnx'
RKNN_MODEL = 'yolov5s.rknn'
#模拟推理用到的测试图片
IMG_PATH = './bus.jpg'
DATASET = './dataset.txt'
QUANTIZE_ON = True
# 根据自己的模型设置
OBJ_THRESH = 0.25
NMS_THRESH = 0.45
IMG_SIZE = 640
CLASSES = ("person", "bicycle", "car", "motorbike ", "aeroplane ", "bus ", "train", "truck ", "boat", "traffic light",
"fire hydrant", "stop sign ", "parking meter", "bench", "bird", "cat", "dog ", "horse ", "sheep", "cow", "elephant",
"bear", "zebra ", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite",
"baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife ",
"spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza ", "donut", "cake", "chair", "sofa",
"pottedplant", "bed", "diningtable", "toilet ", "tvmonitor", "laptop ", "mouse ", "remote ", "keyboard ", "cell phone", "microwave ",
"oven ", "toaster", "sink", "refrigerator ", "book", "clock", "vase", "scissors ", "teddy bear ", "hair drier", "toothbrush ")
#CLASSES = ("ship", "car", "person")
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def xywh2xyxy(x):
# Convert [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = sigmoid(input[..., 5:])
box_xy = sigmoid(input[..., :2])*2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE/grid_h)
box_wh = pow(sigmoid(input[..., 2:4])*2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with box threshold. It's a bit different with origin yolov5 post process!
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
boxes = boxes.reshape(-1, 4)
box_confidences = box_confidences.reshape(-1)
box_class_probs = box_class_probs.reshape(-1, box_class_probs.shape[-1])
_box_pos = np.where(box_confidences >= OBJ_THRESH)
boxes = boxes[_box_pos]
box_confidences = box_confidences[_box_pos]
box_class_probs = box_class_probs[_box_pos]
class_max_score = np.max(box_class_probs, axis=-1)
classes = np.argmax(box_class_probs, axis=-1)
_class_pos = np.where(class_max_score >= OBJ_THRESH)
boxes = boxes[_class_pos]
classes = classes[_class_pos]
scores = (class_max_score* box_confidences)[_class_pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov5_post_process(input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]]
boxes, classes, scores = [], [], []
for input, mask in zip(input_data, masks):
b, c, s = process(input, mask, anchors)
b, c, s = filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
boxes = xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def draw(image, boxes, scores, classes):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
top = int(top)
left = int(left)
right = int(right)
bottom = int(bottom)
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
# pre-process config
# 配置对应平台等信息
print('--> Config model')
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]])
print('done')
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model,传入是否量化等参数
# do_quantization: 是否对模型进行量化,值为 True 或 False
# dataset: RKNN 的 build 接口的量化校正集配置。如果选择了和实际部署场景不大一致的校正
# 集,则可能会出现精度下降的问题,或者校正集的数量过多或过少都会影响精度(一般选择 50~ 200 张)
print('--> Building model')
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export RKNN model
# 导出到这里就结束了
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
#
# --> 从这里开始模拟使用模型推理:
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
# ret = rknn.init_runtime('rk3566')
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Set inputs 读取图片,转换RGB,尺寸拉伸到640x640
img = cv2.imread(IMG_PATH)
# img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
# Inference 推理
print('--> Running model')
outputs = rknn.inference(inputs=[img])
# 把推理结果写入到文件。debug 用可以注释
np.save('./onnx_yolov5_0.npy', outputs[0])
np.save('./onnx_yolov5_1.npy', outputs[1])
np.save('./onnx_yolov5_2.npy', outputs[2])
print('done')
# post process 处理推理结果。
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
input0_data = input0_data.reshape([3, -1]+list(input0_data.shape[-2:]))
input1_data = input1_data.reshape([3, -1]+list(input1_data.shape[-2:]))
input2_data = input2_data.reshape([3, -1]+list(input2_data.shape[-2:]))
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov5_post_process(input_data)
img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if boxes is not None:
draw(img_1, boxes, scores, classes)
# show output
# 去掉这几行代码的注释可以在完成后显示结果图片
# cv2.imshow("post process result", img_1)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
rknn.release()
结果图片(记得去掉代码后面的注释)
联机调试(ADB)
RKNN Toolkit2 目前支持的 Rockchip NPU 平台包括 RK3566 / RK3568 / RK3588 / RV1103 /
8RV1106。该场景下,RKNN Toolkit2 运行在 PC 上,通过 PC 的 USB 连接 NPU 设备。RKNN Toolkit2
将 RKNN 模型传到 NPU 设备上运行,再从 NPU 设备上获取推理结果、性能信息等。
首先,需要完成以下3个步骤:
- 确保开发板的 USB OTG 连接到 PC,并且正确识别到设备,即在 PC 上调用 RKNN-Toolkit2
的 list_devices 接口可查询到相应的设备,关于该接口的使用方法,参见 3.5.15 章节。 - 调用 init_runtime 接口初始化运行环境时需要指定 target 参数和 device_id 参数。
其中 target 参数表明硬件类型,当前版本可选值为“rk3566”、“rk3568”、“rk3588”、“rv1103”、
“rv1106”。当 PC 连接多个设备时,还需要指定 device_id 参数,即设备编号,设备编
号可通过 list_devices 接口查询,
示例如下:
all device(s) with adb mode:
VD46C3KM6N
- 板端支持rknn_server和librknnrt.so: 是一个板端的runtime库
# 板端版本:
rk3568_r:/data # rknn_server -v
start rknn server, version:1.1.0 (55c42b7 build: 2021-08-25 14:44:32)
可以的话,更新板子的rknn_server和librknnrt, 下载rknpu2并推送对应的文件到板子
git clone https://github.com/rockchip-linux/rknpu2
adb push rknpu2/runtime/RK3588/Linux/rknn_server/aarch64/usr/bin/rknn_server /usr/bin/
adb push rknpu2/runtime/RK3588/Linux/librknn_api/aarch64/librknnrt.so /usr/lib/
adb push rknpu2/runtime/RK3588/Linux/librknn_api/aarch64/librknn_api.so /usr/lib/
PS: Android系统需要推送到对应的目录下,自行查找并替换即可!
初始化运行时环境代码示例如下, 可以修改前面的test.py的代码进行验证:
# RK3566
ret = init_runtime(target='rk3566', device_id='VGEJY9PW7T')
# RK3588
ret = init_runtime(target='rk3588', device_id='515e9b401c060c0b')
成功LOG
//LOG
--> Init runtime environment
I target set by user is: rk3568
I Starting ntp or adb, target is RK3568
I Device [e0912a58aa7da2cd] not found in ntb device list.
I Start adb...
I Connect to Device success!
I NPUTransfer: Starting NPU Transfer Client, Transfer version 2.1.0 (b5861e7@2020-11-23T11:50:36)
D NPUTransfer: Transfer spec = local:transfer_proxy
D NPUTransfer: Transfer interface successfully opened, fd = 3
D RKNNAPI: ==============================================
D RKNNAPI: RKNN VERSION:
D RKNNAPI: API: 1.4.0 (bb6dac9 build: 2022-08-29 16:17:01)(null)
D RKNNAPI: DRV: rknn_server: 1.4.0 (bb6dac9 build: 2022-08-29 16:16:39)
D RKNNAPI: DRV: rknnrt: 1.4.0 (a10f100eb@2022-09-09T09:06:40)
D RKNNAPI: ==============================================
失败LOG:
--> Export rknn model
done
--> Init runtime environment
I target set by user is: rk3568
I Starting ntp or adb, target is RK3568
I Device [e0912a58aa7da2cd] not found in ntb device list.
I Start adb...
I Connect to Device success!
I NPUTransfer: Starting NPU Transfer Client, Transfer version 2.1.0 (b5861e7@2020-11-23T11:50:36)
D NPUTransfer: Transfer spec = local:transfer_proxy
D NPUTransfer: Transfer interface successfully opened, fd = 3
E RKNNAPI: rknn_server version is too old, please update rknn_server to at least 1.4.0
E init_runtime: Catch exception when init runtime!
E init_runtime: Traceback (most recent call last):
E init_runtime: File "rknn/api/rknn_base.py", line 1985, in rknn.api.rknn_base.RKNNBase.init_runtime
E init_runtime: File "rknn/api/rknn_runtime.py", line 364, in rknn.api.rknn_runtime.RKNNRuntime.build_graph
E init_runtime: Exception: RKNN init failed. error code: RKNN_ERR_FAIL
Init runtime environment failed!
C++
主要参考:rknpu2/examples/rknn_yolov5_demo/
rknpu2/examples/rknn_yolov5_demo
├── build-android_RK356X.sh
├── build-linux_RK356X.sh
├── src
├── main.cc
└── postprocess.cc
代码自行下载查看,不一一列出来了
参考
Android Demo
编译
根据指定平台修改 build-android_<TARGET_PLATFORM>.sh中的Android NDK的路径 ANDROID_NDK_PATH,<TARGET_PLATFORM>可以是RK356X或RK3588 例如修改成:
ANDROID_NDK_PATH=~/opt/tool_chain/android-ndk-r17
然后执行:
./build-android_<TARGET_PLATFORM>.sh
推送执行文件到板子
连接板子的usb口到PC,将整个demo目录到 /data:
adb root
adb remount
adb push install/rknn_yolov5_demo /data/
运行
adb shell
cd /data/rknn_yolov5_demo/
export LD_LIBRARY_PATH=./lib
./rknn_yolov5_demo model/<TARGET_PLATFORM>/yolov5s-640-640.rknn model/bus.jpg
Aarch64 Linux Demo
编译
根据指定平台修改 build-linux_<TARGET_PLATFORM>.sh中的交叉编译器所在目录的路径 TOOL_CHAIN,例如修改成
export TOOL_CHAIN=~/opt/tool_chain/gcc-9.3.0-x86_64_aarch64-linux-gnu/host
然后执行:
./build-linux_<TARGET_PLATFORM>.sh
推送执行文件到板子
将 install/rknn_yolov5_demo_Linux 拷贝到板子的/userdata/目录.
- 如果使用rockchip的EVB板子,可以使用adb将文件推到板子上:
adb push install/rknn_yolov5_demo_Linux /userdata/
- 如果使用其他板子,可以使用scp等方式将install/rknn_yolov5_demo_Linux拷贝到板子的/userdata/目录
运行
adb shell
cd /userdata/rknn_yolov5_demo_Linux/
export LD_LIBRARY_PATH=./lib
./rknn_yolov5_demo model/<TARGET_PLATFORM>/yolov5s-640-640.rknn model/bus.jpg
Note: Try searching the location of librga.so and add it to LD_LIBRARY_PATH if the librga.so is not found on the lib folder.
Using the following commands to add to LD_LIBRARY_PATH.
export LD_LIBRARY_PATH=./lib:<LOCATION_LIBRGA.SO>
librga
MAIN: config with OBJ_CLASS_NUM=1,
PROP_BOX_SIZE=6,
box_conf_threshold = 0.25,
nms_threshold = 0.45
Read ./model/test.jpg ...
img width = 1280, img height = 853
Loading mode...
sdk version: 1.4.0 (a10f100eb@2022-09-09T09:06:40) driver version: 0.4.2
model input num: 1, output num: 1
index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=1228800, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
index=0, name=output, n_dims=4, dims=[1, 25200, 6, 1], n_elems=151200, size=151200, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=-123, scale=2.556392
model is NHWC input fmt
model input height=640, width=640, channel=3
resize with RGA!
librga fail to get driver version! Legacy mode will be enabled.
rga_api version 1.8.1_[2]
The driver may be compatible, but it is best to update the driver to version 1.2.4. current version: librga 1.8.1_[2], driver .
The driver may be compatible, but it is best to update the driver to version 1.2.4. current version: librga 1.8.1_[2], driver .
RgaBlit(1465) RGA_BLIT fail: Bad address
RgaBlit(1466) RGA_BLIT fail: Bad address
fd-vir-phy-hnd-format[0, 0xb40000772d026040, 0x0, 0, 0]
rect[0, 0, 1280, 853, 1280, 853, 512, 0]
f-blend-size-rotation-col-log-mmu[0, 0, 0, 0, 0, 0, 1]
fd-vir-phy-hnd-format[0, 0xb40000772a7f8040, 0x0, 0, 0]
rect[0, 0, 640, 640, 640, 640, 512, 0]
f-blend-size-rotation-col-log-mmu[0, 0, 0, 0, 0, 0, 1]
This output the user patamaters when rga call blit fail
srect[x,y,w,h] = [0, 0, 0, 0] src[w,h,ws,hs] = [1280, 853, 1280, 853]
drect[x,y,w,h] = [0, 0, 0, 0] dst[w,h,ws,hs] = [640, 640, 640, 640]
usage[0x80000]
MAIN: n_output=1
MAIN: once run use 72.876000 ms
post_process
使用自己的模型,需要匹配对应的参数
rknpu2/examples/rknn_yolov5_demo/include/postprocess.h
//label集文件
#define LABEL_NALE_TXT_PATH "./model/coco_80_labels_list.txt"
#define OBJ_NAME_MAX_SIZE 16
#define OBJ_NUMB_MAX_SIZE 64
//对应85类:输出dims=[1, 255, 20, 20] OBJ_CLASS_NUM 80
//对应6类 :输出dims=[1, 18, 80, 80] OBJ_CLASS_NUM 1
// OBJ_CLASS_NUM = dims[1] / 3 - 5 (待验证)
#define OBJ_CLASS_NUM 80
#define NMS_THRESH 0.45
#define BOX_THRESH 0.25
#define PROP_BOX_SIZE (5+OBJ_CLASS_NUM)
do_quantization=QUANTIZE_ON影响了模型的输出属性:
model input num: 1, output num: 3
index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=2457600, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
index=0, name=output, n_dims=4, dims=[1, 18, 80, 80], n_elems=115200, size=230400, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
index=1, name=272, n_dims=4, dims=[1, 18, 40, 40], n_elems=28800, size=57600, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
index=2, name=274, n_dims=4, dims=[1, 18, 20, 20], n_elems=7200, size=14400, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
False 时type=FP16 相对 True 时type=INT8
读取结果的方法理论上也需要修改(待验证):
rknn_output outputs[io_num.n_output];
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++) {
outputs[i].want_float = 1;
}
踩了一个深坑
自作聪明改了输入的类型
//自作聪明改了输入的类型:
//inputs[0].type = RKNN_TENSOR_UINT8;
inputs[0].type = input_attrs[0].type;
//LOG输出:
//input type=2, TENSOR-U8=3
rknpu2/runtime/RK356X/Linux/librknn_api/include/rknn_api.h
/*
the tensor data type.
*/
typedef enum _rknn_tensor_type {
RKNN_TENSOR_FLOAT32 = 0, /* data type is float32. */
RKNN_TENSOR_FLOAT16, /* data type is float16. */
RKNN_TENSOR_INT8, /* data type is int8. */
RKNN_TENSOR_UINT8, /* data type is uint8. */
RKNN_TENSOR_INT16, /* data type is int16. */
RKNN_TENSOR_UINT16, /* data type is uint16. */
RKNN_TENSOR_INT32, /* data type is int32. */
RKNN_TENSOR_UINT32, /* data type is uint32. */
RKNN_TENSOR_INT64, /* data type is int64. */
RKNN_TENSOR_BOOL,
RKNN_TENSOR_TYPE_MAX
} rknn_tensor_type;
inline static const char* get_type_string(rknn_tensor_type type)
{
switch(type) {
case RKNN_TENSOR_FLOAT32: return "FP32";
case RKNN_TENSOR_FLOAT16: return "FP16";
case RKNN_TENSOR_INT8: return "INT8";
case RKNN_TENSOR_UINT8: return "UINT8";
case RKNN_TENSOR_INT16: return "INT16";
case RKNN_TENSOR_UINT16: return "UINT16";
case RKNN_TENSOR_INT32: return "INT32";
case RKNN_TENSOR_UINT32: return "UINT32";
case RKNN_TENSOR_INT64: return "INT64";
case RKNN_TENSOR_BOOL: return "BOOL";
default: return "UNKNOW";
}
}
导致的结果是: C++程序的识别结果一片混乱,各种参数调节没有效果,而用python执行结果都是正确的。更奇葩的是,有一张图片可以正常识别,其他的大部分图片基本阵亡!
关于推理输出
手把手教学!TensorRT部署实战:YOLOv5的ONNX模型部署
rknn教程
默认模型的输出结果是:
[1, 18, 80, 80] + [1, 18, 40, 40] + [1, 18, 20, 20]
有的模型输出的结果是:
[1, 25200, 6, 1]
YOLOv5的3个检测头一共有(80x80+40x40+20x20)x3=25200个输出单元格,
每个单元格输出x,y,w,h,objectness这5项再加80个类别的置信度总共85项内容。
经过后处理操作后,目标的坐标值已经被恢复到以640x640为参考的尺寸,
如果需要恢复到原始图像尺寸,只需要除以预处理时的缩放因子即可。
这里有个问题需要注意:由于在做预处理的时候图像做了填充,原始图像并不是被缩放成640x640而是640x480,
使得输入给模型的图像的顶部被填充了一块高度为80的区域,
所以在恢复到原始尺寸之前,需要把目标的y坐标减去偏移量80。
RKNN的python demo中,输出了模型的输入输出参数,对应上面的两种输出模式 :
YOLO.RKNN
model input num: 1, output num: 3
#index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=1228800, fmt=NHWC, type=INT8, qnt_type=AFFINE, zp=-128, scale=0.003922
index=0, name=334, n_dims=4, dims=[1, 255, 80, 80], n_elems=1632000, size=1632000, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=77, scale=0.080445
index=1, name=353, n_dims=4, dims=[1, 255, 40, 40], n_elems=408000, size=408000, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=56, scale=0.080794
index=2, name=372, n_dims=4, dims=[1, 255, 20, 20], n_elems=102000, size=102000, fmt=NCHW, type=INT8, qnt_type=AFFINE, zp=69, scale=0.081305
BEST.RKNN
model input num: 1, output num: 1
#index=0, name=images, n_dims=4, dims=[1, 640, 640, 3], n_elems=1228800, size=2457600, fmt=NHWC, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
index=0, name=output, n_dims=4, dims=[1, 25200, 6, 1], n_elems=151200, size=302400, fmt=NCHW, type=FP16, qnt_type=AFFINE, zp=0, scale=1.000000
续(20230726)
升级到1.5, 重新安装依赖环境:
THESE PACKAGES DO NOT MATCH THE HASHES FROM THE REQUIREMENTS FILE
增加参数 –no-cache-dir 如:
sudo pip install --no-cache-dir pkg
tensorflow 2.4.1 requires six~=1.15.0, but you have six 1.16.0 which is incompatible
pip install six==1.15.0
无法解决,继续 launchpadlib 1.10.6 requires testresources, which is not installed.文章来源:https://www.toymoban.com/news/detail-624268.html
sudo apt install python3-testresources
参考
RKNN 使用
rknn-toolkit2
rknpu2
RKNN模型库
README_rkopt_manual.md
API
Yolo-v5 demo
airockchip YOLO - demo
airockchip YOLO in C++
rknn-tookit使用笔记
rknn(rknpu)使用笔记
(一)模型量化与RKNN模型部署
toybrick_ssd_multithread
rknn教程
RK3588模型推理总结文章来源地址https://www.toymoban.com/news/detail-624268.html
到了这里,关于AI-新手玩转RKNN的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!