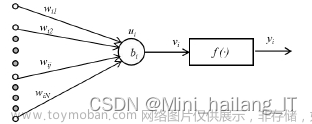
深度学习基础
卷积神经网络与传统神经网络区别
深度学习与神经网络的区别

目标函数
选择合适的目标函数


Softmax层

改进的梯度下降
梯度消失的直观解释

激活函数


学习步长

SGD的问题

存在马鞍面,使我们的训练卡住,于是提出下面方法:
Momentum动量

Nesterov Momentum

先利用“惯性”,“走”一步。避免一开始,就被当前梯度带偏。
Adagrad
为不同的参数设置不同的学习步长。
RMSprop
改进的Adagrad。使:
小的可以变大,大的可以变小。
Adam

各种梯度下降算法比较


关于算法选择的建议

Batch Normalization的由来


量纲不同,需要进行归一化处理。
避免过适应

早期停止训练

权重衰减

Dropout

测试时权重应减小

CNN初步介绍
CNN的基本组件

CNN卷积层




CNN池化层

通道数没变,尺度大小变了。
CNN-Softmax层

池化层的误差反向传播



卷积层计算
卷积层运算的展开表示

与全连接是有区别的。
卷积层的误差反向传播




转了180度


下面是残差 文章来源:https://www.toymoban.com/news/detail-624910.html
文章来源:https://www.toymoban.com/news/detail-624910.html
下面是梯度· 文章来源地址https://www.toymoban.com/news/detail-624910.html
文章来源地址https://www.toymoban.com/news/detail-624910.html
到了这里,关于计算机视觉(五)深度学习基础的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!