本文将详细介绍在Flask Web应用中如何设计数据库模型,并使用Flask-SQLAlchemy等扩展进行数据库操作的最佳实践。内容涵盖数据模型设计,ORM使用,关系映射,查询方法,事务处理等方面。通过本文,您可以掌握Flask数据库应用的基本知识。
Flask作为一个流行的Python Web框架,提供了高度的灵活性来构建Web应用程序。但是Flask本身不包含数据库抽象层,所以我们需要选择合适的数据库工具来辅助开发。
1. 数据库工具选择
要在Flask中集成数据库操作,我们通常有以下几种选择:
-
原生SQL:直接使用Python中的DBAPI,如MySQL-Python等,编写SQL语句操作数据库。但这需要自行处理许多细节。
-
SQLAlchemy:这是一个非常强大的ORM框架,可以映射Python对象到数据库表,简化数据库操作。推荐用于复杂项目。
-
Flask-SQLAlchemy:这是在Flask中整合SQLAlchemy的扩展,可以便捷地将其与Flask应用结合使用。
-
其他扩展:如Flask-MongoEngine for MongoDB,Flask-Pony for PonyORM等。
考虑到SQLAlchemy提供的便利性,我们这里选择使用Flask-SQLAlchemy来示例Flask的数据库用法。
2. 安装Flask-SQLAlchemy
使用pip安装Flask-SQLAlchemy:
pip install flask-sqlalchemy
然后在Flask应用中进行初始化:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
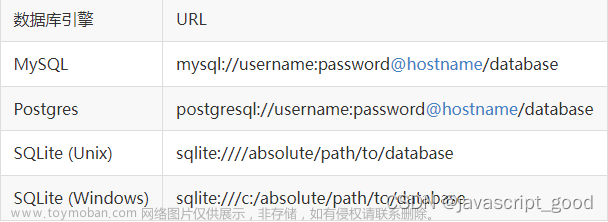
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///test.db'
db = SQLAlchemy(app)
3. 定义模型
使用Flask-SQLAlchemy时,数据库使用ORM映射模型表示。我们可以定义代表表的Model类:
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True)
email = db.Column(db.String(120), unique=True)
def __repr__(self):
return '<User %r>' % self.username
User类表示users表,类的属性映射到表的列。有PrimaryKey,Unique等约束。
4. 创建表
有了Model类定义,我们可以通过migrate命令创建对应的数据库表:
flask db init
flask db migrate
flask db upgrade
这将根据Model类创建数据库表。
5. CRUD操作
有了映射表,我们就可以进行常规的CRUD操作:
创建
user = User(username='greyli', email='greyli@example.com')
db.session.add(user)
db.session.commit()
查询
User.query.get(1) # 主键查询
User.query.filter_by(username='greyli').first() # 条件查询
更新
user = User.query.get(1)
user.username = 'new username'
db.session.commit() # 提交更新
删除
user = User.query.get(1)
db.session.delete(user)
db.session.commit() # 提交删除
可以看到Flask-SQLAlchemy为这些常见操作提供了简单的API。
6. 关系映射
关系映射也是ORM的重要功能之一。例如一篇文章可对应多个标签,我们可以定义:
class Article(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(100), unique=True)
tags = db.relationship('Tag', backref='article', lazy='dynamic')
class Tag(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
这样Article和Tag之间就建立了一对多的关系,可以方便地查询:
article = Article.query.get(1)
tags = article.tags
7. 事务处理
事务处理可以保证数据库操作的完整性:
try:
article = Article(title='my article')
db.session.add(article)
db.session.commit()
except:
db.session.rollback()
raise
这样可以回滚错误的修改,保证事务的原子性。
补充
在Flask应用中,这几条命令是用于数据库迁移的:
- flask db init
这个命令会初始化一个迁移仓库,在migrations文件夹下创建必要的文件。这个迁移仓库用于追踪数据库模式的变更。
- flask db migrate
这个命令会自动比对模型定义和现有数据库的差异,然后生成一个迁移脚本,放在migrations/versions文件夹下。
这个迁移脚本包含了使数据库模式达到我们模型定义的状态所需要的操作指令(如创建新表,添加字段等)。
- flask db upgrade
这个命令则会执行迁移仓库中所有的迁移脚本,实际更新数据库模式,使数据库与模型一致。
所以这三步命令的作用是:
-
初始化迁移仓库
-
生成迁移脚本
-
执行迁移操作
当我们修改了模型类的时候,只需要再次运行:
flask db migrate
flask db upgrade
就可以自动更新数据库,非常方便。
这样做的好处是可以很好地追踪数据库模式的变迁,同时可以通过downgrade回滚变更。总体上可以更轻松地管理数据库模式。文章来源:https://www.toymoban.com/news/detail-624945.html
所以Flask强烈建议使用这套迁移机制来维护数据库,而不是直接修改数据库模式。文章来源地址https://www.toymoban.com/news/detail-624945.html
到了这里,关于flask数据库操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!