目录
Flink异步算子使用介绍
使用Flink异步算子+多线程异步查询MySQL
相关阅读
1 Flink使用异步算子请求高德地图获取位置信息
1、概述
1)Flink异步算子使用介绍
1.异步与同步概述
同步:向数据库发送一个请求然后一直等待,直到收到响应。在许多情况下,等待占据了函数运行的大部分时间。
异步:一个并行函数实例可以并发地处理多个请求和接收多个响应。函数在等待的时间可以发送其他请求和接收其他响应。至少等待的时间可以被多个请求摊分。

异步的优势:异步交互可以大幅度提高流处理的吞吐量。
注意: 仅仅提高算子的并行度(parallelism)在有些情况下也可以提升吞吐量,但是这样做通常会导致非常高的资源消耗:更多的并行 实例意味着更多的 Task、更多的线程、更多的 Flink 内部网络连接、 更多的与数据库的网络连接、更多的缓冲和更多程序内部协调的开销。
2.数据库(或键/值存储)的异步 I/O 交互前提条件
a)需要支持异步请求的数据库客户,许多主流数据库都提供了这样的客户端。
b)如果没有异步客户端,可以通过创建多个客户端并使用线程池处理同步调用的方法,将同步客户端转换为有限并发的客户端。
3.异步 I/O API
Flink 的异步 I/O API 允许用户在流处理中使用异步请求客户端。API 处理与数据流的集成,同时还能处理好顺序、事件时间和容错等。
在具备异步数据库客户端的基础上,实现数据流转换操作与数据库的异步 I/O 交互需要以下三部分:
a)实现分发请求的 AsyncFunction
b)获取数据库交互的结果并发送给 ResultFuture 的 回调 函数
c)将异步 I/O 操作应用于 DataStream 作为 DataStream 的一次转换操作。
// 这个例子使用 Java 8 的 Future 接口(与 Flink 的 Future 相同)实现了异步请求和回调。
/**
* 实现 'AsyncFunction' 用于发送请求和设置回调。
*/
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
/** 能够利用回调函数并发发送请求的数据库客户端 */
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// 发送异步请求,接收 future 结果
final Future<String> result = client.query(key);
// 设置客户端完成请求后要执行的回调函数
// 回调函数只是简单地把结果发给 future
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// 显示地处理异常。
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// 创建初始 DataStream
DataStream<String> stream = ...;
// 应用异步 I/O 转换操作
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);
注意: 第一次调用 ResultFuture.complete 后 ResultFuture 就完成了。 后续的 complete 调用都将被忽略。
下面两个参数控制异步操作:
Timeout: 超时参数定义了异步请求发出多久后未得到响应即被认定为失败。 它可以防止一直等待得不到响应的请求。
Capacity: 容量参数定义了可以同时进行的异步请求数。 即使异步 I/O 通常带来更高的吞吐量,执行异步 I/O 操作的算子仍然可能成为流处理的瓶颈。 限制并发请求的数量可以确保算子不会持续累积待处理的请求进而造成积压,而是在容量耗尽时触发反压。
4.超时处理
当异步 I/O 请求超时的时候,默认会抛出异常并重启作业。 如果你想处理超时,可以重写 AsyncFunction#timeout 方法。
5.结果的顺序
AsyncFunction 发出的并发请求经常以不确定的顺序完成,这取决于请求得到响应的顺序。 Flink 提供两种模式控制结果记录以何种顺序发出。
无序模式: 异步请求一结束就立刻发出结果记录。 流中记录的顺序在经过异步 I/O 算子之后发生了改变。 当使用 处理时间 作为基本时间特征时,这个模式具有最低的延迟和最少的开销。 此模式使用 AsyncDataStream.unorderedWait(...) 方法。
有序模式: 这种模式保持了流的顺序。发出结果记录的顺序与触发异步请求的顺序(记录输入算子的顺序)相同。为了实现这一点,算子将缓冲一个结果记录直到这条记录前面的所有记录都发出(或超时)。由于记录或者结果要在 checkpoint 的状态中保存更长的时间,所以与无序模式相比,有序模式通常会带来一些额外的延迟和 checkpoint 开销。此模式使用 AsyncDataStream.orderedWait(...) 方法。
6.事件时间
当流处理应用使用事件时间时,异步 I/O 算子会正确处理 watermark。对于两种顺序模式,这意味着以下内容:
无序模式: Watermark 既不超前于记录也不落后于记录,即 watermark 建立了顺序的边界。 只有连续两个 watermark 之间的记录是无序发出的。 在一个 watermark 后面生成的记录只会在这个 watermark 发出以后才发出。 在一个 watermark 之前的所有输入的结果记录全部发出以后,才会发出这个 watermark。
这意味着存在 watermark 的情况下,无序模式 会引入一些与有序模式 相同的延迟和管理开销。开销大小取决于 watermark 的频率。
有序模式: 连续两个 watermark 之间的记录顺序也被保留了。开销与使用处理时间 相比,没有显著的差别。
7.容错保证
异步 I/O 算子提供了完全的精确一次容错保证。它将在途的异步请求的记录保存在 checkpoint 中,在故障恢复时重新触发请求。
8.DirectExecutor
在实现使用 Executor和回调的 Futures 时,建议使用 DirectExecutor,因为通常回调的工作量很小,DirectExecutor 避免了额外的线程切换开销。回调通常只是把结果发送给 ResultFuture,也就是把它添加进输出缓冲。从这里开始,包括发送记录和与 chenkpoint 交互在内的繁重逻辑都将在专有的线程池中进行处理。
DirectExecutor 可以通过 org.apache.flink.util.concurrent.Executors.directExecutor() 或 com.google.common.util.concurrent.MoreExecutors.directExecutor() 获得。
9.注意
以下情况导致阻塞的 asyncInvoke(...) 函数,从而使异步行为无效
a)使用同步数据库客户端,它的查询方法调用在返回结果前一直被阻塞。
b)在 asyncInvoke(...) 方法内阻塞等待异步客户端返回的 future 类型对象
目前,出于一致性的原因,AsyncFunction 的算子(异步等待算子)必须位于算子链的头部,必须断开异步等待算子的算子链以防止潜在的一致性问题。需要旧有行为并接受可能违反一致性保证的用户可以实例化并手工将异步等待算子添加到作业图中并将链策略设置回通过异步等待算子的 ChainingStrategy.ALWAYS 方法进行链接。
2)版本说明

2、代码实现
1)使用Flink异步算子+多线程异步查询MySQL
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import com.alibaba.druid.pool.DruidDataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Collections;
import java.util.concurrent.Callable;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
import java.util.function.Supplier;
public class AsyncMySqlQueryWithThreadPool {
public static void main(String[] args) throws Exception {
// 创建 Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 模拟source输出数据
SingleOutputStreamOperator<Integer> line = env.socketTextStream("localhost", 8888)
.map(Integer::parseInt);
// 创建异步算子
AsyncDataStream.orderedWait(line,
new MySqlAsyncFunction(20),
30000,
TimeUnit.MILLISECONDS,
20)
.print();
// 触发执行
env.execute();
}
}
/**
* 自定义 Flink 异步算子
*/
class MySqlAsyncFunction extends RichAsyncFunction<Integer, Tuple2<Integer, String>> {
private int maxConnTotal;
private transient ExecutorService executorService;
private DruidDataSource dataSource;
// 传入最大链接数
public MySqlAsyncFunction(int maxConnTotal) {
this.maxConnTotal = maxConnTotal;
}
@Override
public void open(Configuration parameters) throws Exception {
//创建一个线程池,实现并发提交请求
executorService = Executors.newFixedThreadPool(maxConnTotal);
//创建链接池(异步IO 一个请求对应一个线程,一个请求对应一个链接)
dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setUrl("jdbc:mysql://localhost:3306/xlink?characterEncoding=UTF-8&useSSL=false");
dataSource.setMaxActive(maxConnTotal);
}
@Override
public void close() throws Exception {
executorService.shutdown();
dataSource.close();
}
@Override
public void asyncInvoke(Integer input, ResultFuture<Tuple2<Integer, String>> resultFuture) throws Exception {
//使用线程池提交请求
Future<String> future = executorService.submit(new Callable<String>() {
@Override
public String call() throws Exception {
return queryFromMySql(input);
}
});
// 同步获取请求结果
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return future.get();
} catch (Exception e) {
return null;
}
}
}).thenAccept((String result) -> {
resultFuture.complete(Collections.singleton(Tuple2.of(input, result)));
});
}
/**
* SQL 查询代码实现
*/
private String queryFromMySql(Integer id) throws SQLException {
String sql = "SELECT deptno,db_source FROM dept WHERE deptno = ?";
String result = null;
Connection connection = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
connection = dataSource.getConnection();
stmt = connection.prepareStatement(sql);
stmt.setInt(1, id);
rs = stmt.executeQuery();
while (rs.next()) {
result = rs.getString("db_source");
}
} finally {
if (rs != null) {
rs.close();
}
if (stmt != null) {
stmt.close();
}
if (connection != null) {
connection.close();
}
}
return result;
}
}
3、执行结果
1)命令行创建端口
nc -lk 8888
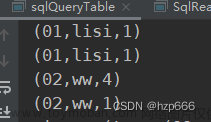
2)输入数据 1文章来源:https://www.toymoban.com/news/detail-624964.html
3)打印执行结果 文章来源地址https://www.toymoban.com/news/detail-624964.html
文章来源地址https://www.toymoban.com/news/detail-624964.html
到了这里,关于一、Flink使用异步算子+线程池查询MySQL的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[flink 实时流基础]源算子和转换算子](https://imgs.yssmx.com/Uploads/2024/04/847286-1.png)




