目录
1.神经网络的整体构架
2.神经网络架构细节
3.正则化与激活函数
4.神经网络过拟合解决方法
1.神经网络的整体构架

ConvNetJS demo: Classify toy 2D data
我们可以看看这个神经网络的网站,可以用来学习。
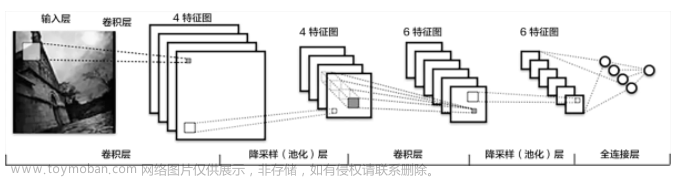
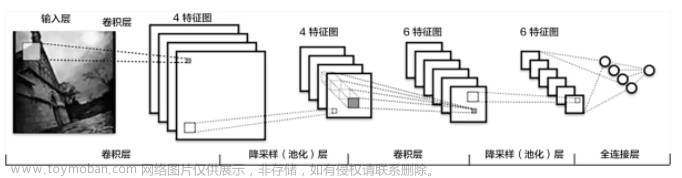
神经网络的整体构架如下1:
-
感知器(Perceptron)感知器是所有神经网络中最基本的,也是更复杂的神经网络的基本组成部分。它只连接一个输入神经元和一个输出神经元。
-
前馈(Feed-Forward)网络前馈网络是感知器的集合,其中有三种基本类型的层:输入层、隐藏层和输出层。在每个连接过程中,来自前一层的信号被乘以一个权重,增加一个偏置,然后通过一个激活函数。前馈网络使用反向传播迭代更新参数,直到达到理想的性能。
-
残差网络(Residual Networks/ResNet深层前馈神经网络的一个问题是所谓的梯度消失,即当网络太深时,有用的信息无法在整个网络中反向传播。当更新参。
对于神经网络的整体构架,我们总结为四点:层次结构、神经元、全连接和非线性。

层次结构:
由上图不难看出,在神经网络中神经网络的我们一般分成三个部分:
1:输入层(input layer)
2:隐藏层(hidden layer)
3:输出层(output layer)
ps:要注意的是,中间的隐藏层可以有多层。
神经元:
每个层次中都有许多圆圆的球似的东西,这个东西就是在神经网络中的神经元,就是数据的量或者是矩阵的大小,每一种层次中的神经元中的含量不太一样。
在输入层中的每一个神经元里面是你输入原始数据(一般称为X)的不同特征,比如x为一张图片,这张图片的像素是32323,其中的每一个像素都是它的特征吧,所以有3072个特征对应的输入层神经元个数就是3072个,这些特征以矩阵的形式进行输入的。我们举个例子比如我们的输入矩阵为1*3072(第一维的数字表示一个batch(batch指的是每次训练输入多少个数据)中有多少个输入;第二维数字中的就是每一个输入有多少特征。)
在隐藏层中的每一层神经元表示对x进行一次更新的数据,而每层有几个神经元(比如图中hidden1层中有四个神经元)表示将你的输入数据的特征扩展到几个(比如图中就是四个),就比如你的输入三个特征分别为年龄,体重,身高,而图中hidden1层中第一个神经元中经过变换可以变成这样‘年龄0.1+体重0.4+身高0.5’,而第二个神经元可以表示成‘年龄0.2+体重0.5+身高0.3’,每一层中的神经元都可以有不同的表示形式。
在输出层中的的神经元个数主要取决于你想要让神经网络干什么,比如你想让它做一个10分类问题,输出层的矩阵就可以是’1*10’的矩阵(第一维表示的与输入层表示数字相同,后面10就是10种分类)。
全连接:
我们看到的每一层和下一层中间都有灰色的线,这些线就被称为全连接(因为你看上一层中每个神经元都连接着下一层中的所有神经元),而这些线我们也可以用一个矩阵表示,这个矩阵我们通常称为‘权重矩阵’,用大写的W来表示(是后续我们需要更新的参数)。 权重矩阵W的维数主要靠的是上一层进来数据的输入数据维数和下一层需要输入的维数,可以简单理解为上有一层有几个神经元和下一层有几个神经元,例如图中input layer中有3个神经元,而hidden1 layer中有4个神经元,中的W的维度就为‘3*4’,以此类推。(主要是因为我们全连接层的形式是矩阵运算形式,需要满足矩阵乘法的运算法则。
非线性:
非线性(non-linear),即 变量之间的数学关系,不是直线而是曲线、曲面、或不确定的属性,叫非线性。非线性是自然界的复杂性的典型性质之一;与线性相比,非线性更接近客观事物性质本身,是量化研究认识复杂知识的重要方法之一;凡是能用非线性描述的关系,通称非线性关系。
2.神经网络架构细节
整体构架:
基础构架:f=W2max(0, W1x)
继续堆加一层:f=W3max(0, W2max(0,W1x))
神经网络的强大之处在于用更多的参数来拟合复杂的数据。
神经元个数对结果的影响:
改之前的:
layer_defs = [];
layer_defs.push({type:'input', out_sx:1, out_sy:1, out_depth:2});
layer_defs.push({type:'fc', num_neurons:, activation: 'tanh'});
layer_defs.push({type:'fc', num_neurons:2, activation: 'tanh'});
layer_defs.push({type:'softmax', num_classes:2});
net = new convnetjs.Net();
net.makeLayers(layer_defs);
trainer = new convnetjs.SGDTrainer(net, {learning_rate:0.01, momentum:0.1, batch_size:10, l2_decay:0.001});

layer_defs = [];
layer_defs.push({type:'input', out_sx:1, out_sy:1, out_depth:2});
layer_defs.push({type:'fc', num_neurons:2, activation: 'tanh'});
layer_defs.push({type:'fc', num_neurons:2, activation: 'tanh'});
layer_defs.push({type:'softmax', num_classes:2});
net = new convnetjs.Net();
net.makeLayers(layer_defs);
trainer = new convnetjs.SGDTrainer(net, {learning_rate:0.01, momentum:0.1, batch_size:10, l2_decay:0.001});
改成2以后的图样

然后神经个数调为5以后的样子:
layer_defs = [];
layer_defs.push({type:'input', out_sx:1, out_sy:1, out_depth:2});
layer_defs.push({type:'fc', num_neurons:5, activation: 'tanh'});
layer_defs.push({type:'fc', num_neurons:5, activation: 'tanh'});
layer_defs.push({type:'softmax', num_classes:2});
net = new convnetjs.Net();
net.makeLayers(layer_defs);
trainer = new convnetjs.SGDTrainer(net, {learning_rate:0.01, momentum:0.1, batch_size:10, l2_decay:0.001});

3.正则化与激活函数
正则化的作用:
机器学习中经常会在损失函数中加入正则项,称之为正则化(Regularize)。防止模型过拟合,也就是说,在损失函数上加上某些规则(限制),缩小解空间,从而减少求出过拟合解的可能性。
激活函数:
常用的激活函数有Sigmoid,Relu,Tanh等,进行相应的非线性变换

激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。
学高等数学的时候,在不定积分那一块,有个画曲为直思想来近似求解。那么,我们可以来借鉴一下,用无数条直线去近似接近一条曲线。
4.神经网络过拟合解决方法
参数初始化:
参数初始化是很重要的,通常我们都适用随机策略来进行参数初始化
W = 0.01 * np.random.randn(D, H)
数据预处理:
不同的处理结果会使得模型的效果发生很大的差异

DROP-OUT
这就是传说中的七伤拳
过拟合是神经网络中一个令人非常头疼的大问题
-
一种含义是:在机器学习中,是解决模型过拟合问题的策略。
-
另一种含义是:是dropout技术的实现,让每一层网络的输出被随机选择丢弃一些神经元,这样可以防止梯度消失和爆炸的问题,有助于提升整个网络的泛化能力。
 文章来源:https://www.toymoban.com/news/detail-624975.html
文章来源:https://www.toymoban.com/news/detail-624975.html
 文章来源地址https://www.toymoban.com/news/detail-624975.html
文章来源地址https://www.toymoban.com/news/detail-624975.html
到了这里,关于深度学习,神经网络介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!