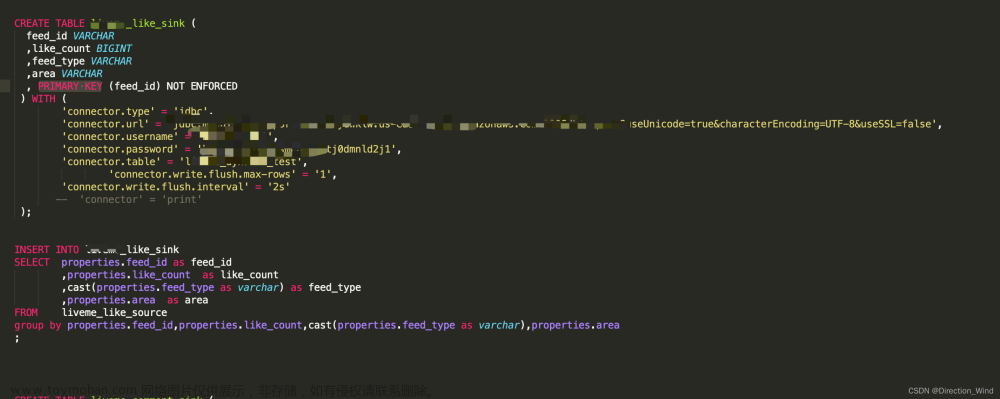
问题聚集度:最小的分母占比,贡献最多的分子占比,即小规模贡献大问题。文章来源地址https://www.toymoban.com/news/detail-625224.html
select
city_name
,user_id
,rf_type
,deal_ord_cnt
,sale_amt
,rf_ord_cnt
,rf_amt
,rf_ra
,rf_amt_ra
,rf_all
,ord_cnt_all
,rf_gx
,ord_cnt_gx
,del_gx
,row_number() over(partition by rf_type order by del_gx desc,rf_ra desc,user_id) as rn -- 贡献差由大到小排序
,sum(rf_ord_cnt) over(partition by rf_type order by del_gx desc,rf_ra desc,user_id) as rf_ordby -- 分子累计
,sum(deal_ord_cnt) over(partition by rf_type order by del_gx desc,rf_ra desc,user_id) as ord_cnt_ordby -- 分母累计
,(sum(rf_ord_cnt) over(partition by rf_type order by del_gx desc,rf_ra desc,user_id)) / rf_all as rf_ordby_ra -- 分子累计占比曲线
,(sum(deal_ord_cnt) over(partition by rf_type order by del_gx desc,rf_ra desc,user_id)) / ord_cnt_all as ord_cnt_ordby_ra -- 分母累计占比曲线
,((sum(rf_ord_cnt) over(partition by rf_type order by del_gx desc,rf_ra desc,user_id)) / rf_all -
(sum(deal_ord_cnt) over(partition by rf_type order by del_gx desc,rf_ra desc,user_id)) / ord_cnt_all) del1 -- 累计贡献差
,lead(((sum(rf_ord_cnt) over(partition by rf_type order by del_gx desc,rf_ra desc,user_id)) / rf_all -
(sum(deal_ord_cnt) over(partition by rf_type order by del_gx desc,rf_ra desc,user_id)) / ord_cnt_all),1)
over(partition by rf_type order by del_gx desc,rf_ra desc,user_id) -
((sum(rf_ord_cnt) over(partition by rf_type order by del_gx desc,rf_ra desc,user_id)) / rf_all -
(sum(deal_ord_cnt) over(partition by rf_type order by del_gx desc,rf_ra desc,user_id)) / ord_cnt_all) as del2 --二阶差分,大于0的部分为聚集部分
from
(
select
city_name
,user_id
,deal_ord_cnt -- 分母
,sale_amt
,rf_cancel_ord_cnt as rf_ord_cnt -- 分子
,rf_qx_amt as rf_amt
,rf_cancel_ord_cnt / deal_ord_cnt as rf_ra -- 监控指标
,rf_qx_amt/sale_amt as rf_amt_ra
,sum(rf_cancel_ord_cnt) over() as rf_all
,sum(deal_ord_cnt) over() as ord_cnt_all
,rf_cancel_ord_cnt / (sum(rf_cancel_ord_cnt) over()) as rf_gx -- 分子贡献
,deal_ord_cnt / (sum(deal_ord_cnt) over()) as ord_cnt_gx -- 分母贡献
,rf_cancel_ord_cnt / (sum(rf_cancel_ord_cnt) over()) - deal_ord_cnt / (sum(deal_ord_cnt) over()) as del_gx -- 贡献差值
,'取消订单' as rf_type
from table_refund
where rf_cancel_ord_cnt > 0 -- 限定分子>0
) t0
文章来源:https://www.toymoban.com/news/detail-625224.html
到了这里,关于问题聚集度Hive SQL的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!